
AI 101
Kas ir pārtēriņš?
Kas ir pārtēriņš?
Apmācot neironu tīklu, jums ir jāizvairās no pārmērīgas pielāgošanas. Pārmērīga aprīkošana ir problēma mašīnmācībā un statistikā, kad modelis pārāk labi apgūst apmācības datu kopas modeļus, lieliski izskaidrojot apmācības datu kopu, bet nespējot vispārināt tās prognozēšanas spēku uz citām datu kopām.
Citiem vārdiem sakot, pārmērīga modeļa gadījumā tas bieži uzrādīs ārkārtīgi augstu apmācības datu kopas precizitāti, bet zemu precizitāti apkopotajos un modelī turpmākajos datos. Šī ir īsa pārmērības definīcija, taču aplūkosim pārmērības jēdzienu sīkāk. Apskatīsim, kā notiek pārklāšanās un kā no tās izvairīties.
Izpratne par “piemērotību” un “nepiemērotību”.
Ir lietderīgi aplūkot nepietiekamas atbilstības jēdzienu un “piemērots” parasti, runājot par pārmērību. Kad mēs apmācām modeli, mēs cenšamies izstrādāt sistēmu, kas spēj paredzēt datu kopas vienumu raksturu vai klasi, pamatojoties uz funkcijām, kas apraksta šos vienumus. Modelim jāspēj izskaidrot modeli datu kopā un paredzēt nākotnes datu punktu klases, pamatojoties uz šo modeli. Jo labāk modelis izskaidro attiecības starp treniņu komplekta iezīmēm, jo “piemērotāks” ir mūsu modelis.
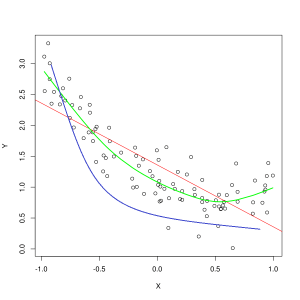
Zilā līnija apzīmē nepietiekami piemērota modeļa prognozes, savukārt zaļā līnija apzīmē labāk piemērotu modeli. Foto: Pep Roca, izmantojot Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Modelis, kas slikti izskaidro attiecības starp apmācības datu iezīmēm un tādējādi nespēj precīzi klasificēt turpmākos datu piemērus, ir nepietiekama uzstādīšana apmācības dati. Ja grafikā attēlotu nepietiekama modeļa paredzamo attiecību pret faktisko iezīmju un etiķešu krustpunktu, prognozes novirzītos no atzīmes. Ja mums būtu grafiks ar apzīmētām treniņu kopas faktiskajām vērtībām, ļoti nepietiekami piemērots modelis krasi izlaistu lielāko daļu datu punktu. Modelis ar labāku atbilstību var izgriezt ceļu caur datu punktu centru, atsevišķiem datu punktiem tikai nedaudz atkāpjoties no prognozētajām vērtībām.
Nepietiekama atbilstība bieži var rasties, ja nav pietiekami daudz datu, lai izveidotu precīzu modeli, vai mēģinot izveidot lineāru modeli ar nelineāriem datiem. Vairāk treniņu datu vai vairāk funkciju bieži vien palīdz samazināt nepietiekamu piemērotību.
Tātad, kāpēc mēs vienkārši neizveidotu modeli, kas lieliski izskaidro katru apmācības datu punktu? Vai tiešām ir vēlama nevainojama precizitāte? Tāda modeļa izveide, kas ir pārāk labi apguvis apmācības datu modeļus, izraisa pārmērību. Apmācības datu kopa un citas turpmākās datu kopas, kuras izpildīsit modelī, nebūs tieši tādas pašas. Tie, iespējams, būs ļoti līdzīgi daudzos aspektos, taču tie atšķirsies arī galvenajos veidos. Tāpēc, izstrādājot modeli, kas lieliski izskaidro apmācības datu kopu, jūs iegūstat teoriju par saistību starp funkcijām, kas nav labi vispārināma ar citām datu kopām.
Izpratne par pārmērību
Pārmērīga pielāgošana notiek, ja modelis pārāk labi apgūst apmācības datu kopas detaļas, kā rezultātā modelis cieš, kad tiek veiktas prognozes par ārējiem datiem. Tas var notikt, ja modelis ne tikai apgūst datu kopas funkcijas, bet arī apgūst nejaušas svārstības vai troksnis datu kopā, piešķirot nozīmi šiem nejaušajiem/nesvarīgajiem gadījumiem.
Pārmērīga pielāgošana, visticamāk, notiks, ja tiek izmantoti nelineāri modeļi, jo tie ir elastīgāki, apgūstot datu funkcijas. Neparametriskiem mašīnmācīšanās algoritmiem bieži ir dažādi parametri un paņēmieni, kurus var izmantot, lai ierobežotu modeļa jutīgumu pret datiem un tādējādi samazinātu pārmērīgu pielāgošanu. Kā piemērs, lēmumu koku modeļi ir ļoti jutīgi pret pārmērīgu pielāgošanu, taču var izmantot paņēmienu, ko sauc par apgriešanu, lai nejauši noņemtu dažas detaļas, kuras modelis ir iemācījies.
Ja modeļa prognozes attēlotu grafikā uz X un Y asīm, jūs iegūtu prognozes līniju, kas svārstās uz priekšu un atpakaļ, kas atspoguļo faktu, ka modelis ir pārāk centies visus datu kopas punktus ievietot tā skaidrojums.
Pārmērīgas uzstādīšanas kontrole
Kad mēs apmācām modeli, mēs ideālā gadījumā vēlamies, lai modelis nepieļautu kļūdas. Kad modeļa veiktspēja tuvojas pareizu prognožu veikšanai visos apmācības datu kopas datu punktos, atbilstība kļūst labāka. Modelis ar labu piemērotību spēj izskaidrot gandrīz visu apmācības datu kopu bez pārmērīgas pielāgošanas.
Modelim trenējoties, laika gaitā tā veiktspēja uzlabojas. Modeļa kļūdu līmenis samazināsies, ejot apmācības laikam, bet tas samazinās tikai līdz noteiktam punktam. Punkts, kurā modeļa veiktspēja testa komplektā sāk atkal pieaugt, parasti ir punkts, kurā notiek pārmērīga uzstādīšana. Lai iegūtu modelim vislabāko piemērotību, mēs vēlamies pārtraukt modeļa apmācību treniņu komplekta mazākā zaudējuma punktā, pirms kļūda atkal sāk palielināties. Optimālo apstāšanās punktu var noteikt, attēlojot modeļa veiktspēju visā apmācības laikā un pārtraucot treniņu, kad zaudējumi ir vismazākie. Tomēr viens no riskiem, kas saistīti ar šo pārmērības kontroles metodi, ir tāds, ka apmācības beigu punkta noteikšana, pamatojoties uz testa veiktspēju, nozīmē, ka testa dati tiek iekļauti apmācības procedūrā un zaudē savu statusu kā tīri “neskarti” dati.
Ir vairāki dažādi veidi, kā cīnīties pret pārmērību. Viena no pārmērīšanas samazināšanas metodēm ir atkārtotas paraugu ņemšanas taktikas izmantošana, kas darbojas, novērtējot modeļa precizitāti. Varat arī izmantot a validēšana datu kopu papildus testa kopai un attēlojiet apmācības precizitāti pret validācijas kopu, nevis testa datu kopu. Tādējādi jūsu testa datu kopa nav redzama. Populāra atkārtotas paraugu ņemšanas metode ir K-locījumu savstarpējā validācija. Šis paņēmiens ļauj sadalīt datus apakškopās, kurām modelis ir apmācīts, un pēc tam tiek analizēta modeļa veiktspēja apakškopās, lai novērtētu, kā modelis darbosies ar ārējiem datiem.
Savstarpējās validācijas izmantošana ir viens no labākajiem veidiem, kā novērtēt modeļa precizitāti neredzamiem datiem, un, apvienojot to ar validācijas datu kopu, pārmērīgu pielāgošanu bieži var samazināt līdz minimumam.










