
AI 101
Kas ir dimensiju samazināšana?
Kas ir dimensiju samazināšana?
Izmēru samazināšana ir process, ko izmanto, lai samazinātu datu kopas dimensiju, izmantojot daudzas funkcijas un attēlojot tās kā mazākas funkcijas. Piemēram, izmēru samazināšanu var izmantot, lai samazinātu divdesmit objektu datu kopu līdz tikai dažiem līdzekļiem. Izmēru samazināšanu parasti izmanto mācīšanās bez uzraudzības uzdevumi, lai automātiski izveidotu klases no daudzām funkcijām. Lai labāk saprastu kāpēc un kā tiek izmantota dimensiju samazināšana, mēs apskatīsim problēmas, kas saistītas ar augstas dimensijas datiem, un populārākajām dimensiju samazināšanas metodēm.
Lielāki izmēri noved pie pārmērības
Dimensijas attiecas uz objektu/kolonnu skaitu datu kopā.
Bieži tiek pieņemts, ka mašīnmācībā vairāk funkciju ir labākas, jo tas rada precīzāku modeli. Tomēr vairāk funkciju ne vienmēr nozīmē labāku modeli.
Datu kopas funkcijas var ievērojami atšķirties atkarībā no tā, cik noderīgas tās ir modelim, un daudzām funkcijām ir maza nozīme. Turklāt, jo vairāk līdzekļu ir datu kopā, jo vairāk paraugu ir nepieciešams, lai nodrošinātu, ka dažādās pazīmju kombinācijas ir labi attēlotas datos. Tāpēc paraugu skaits palielinās proporcionāli pazīmju skaitam. Vairāk paraugu un vairāk funkciju nozīmē, ka modelim ir jābūt sarežģītākam, un, modeļiem kļūstot sarežģītākiem, tie kļūst jutīgāki pret pārmērīgu pielāgošanu. Modelis pārāk labi apgūst apmācības datu modeļus, un tas nespēj vispārināt datus, kas nav parauga dati.
Datu kopas izmēru samazināšanai ir vairākas priekšrocības. Kā minēts, vienkāršāki modeļi ir mazāk pakļauti pārklāšanai, jo modelim ir jāizdara mazāk pieņēmumu par to, kā funkcijas ir savstarpēji saistītas. Turklāt mazāks izmērs nozīmē mazāku skaitļošanas jaudu, lai apmācītu algoritmus. Tāpat mazāka izmēra datu kopai ir nepieciešams mazāk vietas. Datu kopas dimensijas samazināšana var arī ļaut izmantot algoritmus, kas nav piemēroti datu kopām ar daudzām funkcijām.
Kopējās dimensiju samazināšanas metodes
Izmēru samazināšanu var veikt, izvēloties objektu vai objektu inženieriju. Līdzekļu atlase ir vieta, kur inženieris identificē visatbilstošākos datu kopas līdzekļus funkciju inženierija ir jaunu funkciju izveides process, apvienojot vai pārveidojot citas funkcijas.
Funkciju atlasi un inženieriju var veikt programmatiski vai manuāli. Manuāli atlasot un izstrādājot līdzekļus, tipiska ir datu vizualizācija, lai atklātu korelācijas starp līdzekļiem un klasēm. Dimensiju samazināšana šādā veidā var būt diezgan laikietilpīga, un tāpēc daži no visizplatītākajiem dimensiju samazināšanas veidiem ietver tādu bibliotēkās pieejamo algoritmu izmantošanu kā Scikit-learn for Python. Šie izplatītie dimensiju samazināšanas algoritmi ietver: galveno komponentu analīzi (PCA), Singular Value Decomposition (SVD) un lineāro diskriminācijas analīzi (LDA).
Algoritmi, ko izmanto dimensiju samazināšanai neuzraudzītiem mācību uzdevumiem, parasti ir PCA un SVD, savukārt algoritmi, kas tiek izmantoti uzraudzītai mācību dimensijas samazināšanai, parasti ir LDA un PCA. Uzraudzītu mācību modeļu gadījumā jaunizveidotie līdzekļi vienkārši tiek ievadīti mašīnmācīšanās klasifikatorā. Ņemiet vērā, ka šeit aprakstītie lietojumi ir tikai vispārīgi lietošanas gadījumi, nevis vienīgie nosacījumi, kādos šīs metodes var izmantot. Iepriekš aprakstītie dimensiju samazināšanas algoritmi ir vienkārši statistikas metodes, un tos izmanto ārpus mašīnmācīšanās modeļiem.
Galveno komponentu analīze

Foto: Matrica ar identificētām galvenajām sastāvdaļām
Galveno komponentu analīze (PCA) ir statistikas metode, kas analizē datu kopas raksturlielumus/iezīmes un apkopo ietekmīgākās pazīmes. Datu kopas līdzekļi ir apvienoti attēlos, kas saglabā lielāko daļu datu raksturlielumu, bet ir sadalīti mazākās dimensijās. Varat to uzskatīt par datu “izspiešanu” no augstākas dimensijas attēlojuma uz tādu, kurā ir tikai dažas dimensijas.
Kā piemēru situācijai, kurā PCA varētu būt noderīga, padomājiet par dažādiem veidiem, kā varētu raksturot vīnu. Lai gan ir iespējams aprakstīt vīnu, izmantojot daudzas ļoti specifiskas pazīmes, piemēram, CO2 līmeni, aerācijas līmeni utt., šādas specifiskas pazīmes var būt salīdzinoši bezjēdzīgas, mēģinot identificēt konkrētu vīna veidu. Tā vietā būtu saprātīgāk noteikt veidu, pamatojoties uz vispārīgākām iezīmēm, piemēram, garšu, krāsu un vecumu. PCA var izmantot, lai apvienotu specifiskākas funkcijas un izveidotu funkcijas, kas ir vispārīgākas, noderīgākas un mazāk ticamas, ka tās var izraisīt pārmērīgu pielāgošanu.
PCA tiek veikta, nosakot, kā ievades pazīmes atšķiras no vidējā viena attiecībā pret otru, nosakot, vai starp pazīmēm pastāv attiecības. Lai to izdarītu, tiek izveidota kovariantu matrica, izveidojot matricu, kas sastāv no kovariācijām attiecībā uz iespējamajiem datu kopas pazīmju pāriem. To izmanto, lai noteiktu korelācijas starp mainīgajiem, ar negatīvu kovariāciju, kas norāda uz apgrieztu korelāciju, un pozitīvu korelāciju, kas norāda uz pozitīvu korelāciju.
Datu kopas galvenie (ietekmīgākie) komponenti tiek veidoti, veidojot sākotnējo mainīgo lineāras kombinācijas, kas tiek veikta ar lineārās algebras jēdzienu palīdzību, t.s. īpašvērtības un īpašvektori. Kombinācijas tiek veidotas tā, lai galvenās sastāvdaļas nebūtu savstarpēji saistītas. Lielākā daļa informācijas, kas ietverta sākotnējos mainīgajos, tiek saspiesta dažos pirmajos galvenajos komponentos, kas nozīmē, ka ir izveidoti jauni līdzekļi (galvenie komponenti), kas satur informāciju no sākotnējās datu kopas mazākas dimensijas telpā.
Singular Value Dekompozīcija
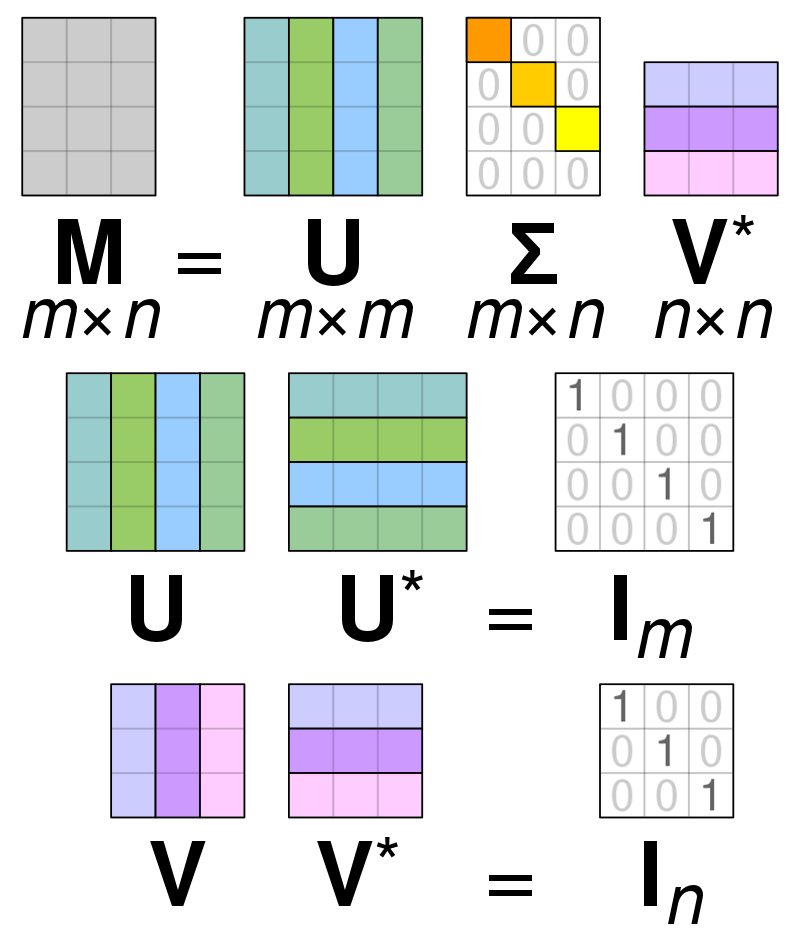
Foto: Cmglee — pašu darbs, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=67853297
Singular Value Decomposition (SVD) is izmanto, lai vienkāršotu vērtības matricā, samazinot matricu līdz tās sastāvdaļām un atvieglojot aprēķinus ar šo matricu. SVD var izmantot gan reālo vērtību, gan sarežģītām matricām, taču šī skaidrojuma nolūkos tiks pārbaudīts, kā sadalīt reālo vērtību matricu.
Pieņemsim, ka mums ir matrica, kas sastāv no reālās vērtības datiem, un mūsu mērķis ir samazināt kolonnu/iezīmju skaitu matricā, līdzīgi kā PCA mērķis. Tāpat kā PCA, SVD saspiedīs matricas dimensiju, vienlaikus saglabājot pēc iespējas lielāku matricas mainīgumu. Ja mēs vēlamies darboties ar matricu A, mēs varam attēlot matricu A kā trīs citas matricas, ko sauc par U, D un V. Matrica A sastāv no sākotnējiem x * y elementiem, savukārt matrica U sastāv no elementiem X * X (tā ir ortogonāla matrica). Matrica V ir atšķirīga ortogonāla matrica, kas satur y * y elementus. Matrica D satur elementus x * y, un tā ir diagonālā matrica.
Lai sadalītu matricas A vērtības, mums ir jāpārvērš sākotnējās vienskaitļa matricas vērtības par diagonālajām vērtībām, kas atrodamas jaunā matricā. Strādājot ar ortogonālām matricām, to īpašības nemainās, ja tās reizina ar citiem skaitļiem. Tāpēc mēs varam tuvināt matricu A, izmantojot šo īpašību. Ja mēs reizinām ortogonālās matricas ar matricas V transponēšanu, rezultāts ir līdzvērtīga matrica mūsu sākotnējai A.
Kad matrica a tiek sadalīta matricās U, D un V, tās satur datus, kas atrodami matricā A. Tomēr matricu vistālāk esošās kolonnas satur lielāko daļu datu. Mēs varam ņemt tikai šīs dažas pirmās kolonnas un iegūt Matricas A attēlojumu, kurā ir daudz mazāk dimensiju un lielākā daļa datu A ietvaros.
Lineārā diskriminantu analīze

Pa kreisi: matrica pirms LDA, pa labi: ass pēc LDA, tagad atdalāma
Lineārā diskriminācijas analīze (LDA) ir process, kas ņem datus no daudzdimensiju grafika un pārprojicē to lineārā grafikā. To var iedomāties, domājot par divdimensiju grafiku, kas piepildīts ar datu punktiem, kas pieder pie divām dažādām klasēm. Pieņemsim, ka punkti ir izkaisīti tā, lai nevarētu novilkt līniju, kas glīti atdalītu abas dažādās klases. Lai risinātu šo situāciju, 2D diagrammā atrastos punktus var samazināt līdz 1D diagrammai (līnijai). Šajā rindā visi datu punkti būs sadalīti, un, cerams, to varēs sadalīt divās daļās, kas atspoguļo vislabāko iespējamo datu atdalīšanu.
Veicot LDA, ir divi galvenie mērķi. Pirmais mērķis ir samazināt klašu dispersiju, bet otrais mērķis ir maksimāli palielināt attālumu starp divu klašu vidējiem rādītājiem. Šie mērķi tiek sasniegti, izveidojot jaunu asi, kas pastāvēs 2D diagrammā. Jaunizveidotā ass darbojas, lai atdalītu abas klases, pamatojoties uz iepriekš aprakstītajiem mērķiem. Pēc ass izveidošanas 2D grafikā atrastie punkti tiek novietoti gar asi.
Ir jāveic trīs darbības, lai pārvietotu sākotnējos punktus uz jaunu pozīciju pa jauno asi. Pirmajā posmā, lai aprēķinātu klašu atdalāmību, tiek izmantots attālums starp atsevišķām klasēm. Otrajā posmā aprēķina dispersiju dažādās klasēs, nosakot attālumu starp paraugu un attiecīgās klases vidējo. Pēdējā solī tiek izveidota zemākās dimensijas telpa, kas maksimāli palielina dispersiju starp klasēm.
LDA tehnika sasniedz labākos rezultātus, ja mērķa klasēm paredzētie līdzekļi ir tālu viens no otra. LDA nevar efektīvi atdalīt klases ar lineāro asi, ja sadalījumu līdzekļi pārklājas.










