AI 101
बैकप्रोपेगेशन क्या है?
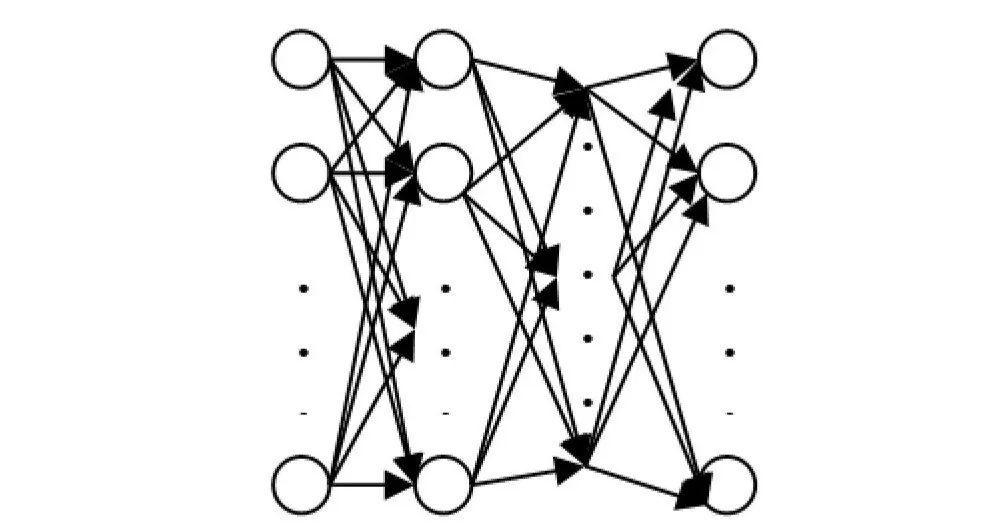
बैकप्रोपेगेशन क्या है?
गहरे शिक्षण प्रणाली बहुत जटिल पैटर्न सीखने में सक्षम हैं, और वे अपने वजन को समायोजित करके ऐसा करती हैं। एक गहरे तंत्रिका नेटवर्क के वजन कैसे समायोजित किए जाते हैं? वे एक प्रक्रिया के माध्यम से समायोजित किए जाते हैं जिसे बैकप्रोपेगेशन कहा जाता है। बैकप्रोपेगेशन के बिना, गहरे तंत्रिका नेटवर्क छवियों को पहचानने और प्राकृतिक भाषा की व्याख्या जैसे कार्यों को नहीं कर पाएंगे। बैकप्रोपेगेशन के काम करने के तरीके को समझना गहरे तंत्रिका नेटवर्क को समझने के लिए महत्वपूर्ण है, इसलिए आइए बैकप्रोपेगेशन पर चर्चा करें और देखें कि यह प्रक्रिया नेटवर्क के वजन को कैसे समायोजित करती है।
बैकप्रोपेगेशन को समझना मुश्किल हो सकता है, और बैकप्रोपेगेशन को करने के लिए उपयोग किए जाने वाले गणनाएं बहुत जटिल हो सकती हैं। यह लेख आपको बैकप्रोपेगेशन की एक सहज समझ देने का प्रयास करेगा, जिसमें जटिल गणित का उपयोग नहीं किया जाएगा।
बैकप्रोपेगेशन का उद्देश्य
बैकप्रोपेगेशन के उद्देश्य को परिभाषित करने से शुरू करें। एक गहरे तंत्रिका नेटवर्क के वजन तंत्रिका नेटवर्क के इकाइयों के बीच कनेक्शन की ताकत होते हैं। जब तंत्रिका नेटवर्क स्थापित किया जाता है, तो यह माना जाता है कि एक परत की इकाइयां कैसे जुड़ी हुई हैं जो इसके साथ जुड़ी हुई हैं। जब डेटा तंत्रिका नेटवर्क के माध्यम से गुजरता है, तो वजन की गणना की जाती है और धारणाएं की जाती हैं। जब डेटा नेटवर्क की अंतिम परत तक पहुंचता है, तो डेटासेट में विशेषताओं और वर्गों के बीच संबंध के बारे में एक भविष्यवाणी की जाती है। भविष्यवाणी किए गए मानों और वास्तविक मानों के बीच का अंतर हानि/त्रुटि है, और बैकप्रोपेगेशन का उद्देश्य हानि को कम करना है। यह नेटवर्क के वजन को समायोजित करके किया जाता है, जिससे धारणाएं वास्तविक संबंधों के समान हो जाती हैं।
एक गहरे तंत्रिका नेटवर्क को प्रशिक्षित करना
बैकप्रोपेगेशन को एक तंत्रिका नेटवर्क पर करने से पहले, तंत्रिका नेटवर्क का नियमित/आगे का प्रशिक्षण पास करना होगा। जब एक तंत्रिका नेटवर्क बनाया जाता है, तो एक वजन सेट को आरंभ किया जाता है। वजन का मान नेटवर्क के प्रशिक्षण के दौरान बदल जाएगा। तंत्रिका नेटवर्क का आगे का प्रशिक्षण पास तीन विभिन्न चरणों में विभाजित किया जा सकता है: न्यूरॉन सक्रियण, न्यूरॉन ट्रांसफर, और आगे का प्रसार।
एक गहरे तंत्रिका नेटवर्क को प्रशिक्षित करते समय, हमें कई गणितीय कार्यों का उपयोग करने की आवश्यकता होती है। एक गहरे तंत्रिका नेटवर्क में न्यूरॉन्स आगमन डेटा और एक सक्रियण कार्य से बने होते हैं, जो नोड को सक्रिय करने के लिए आवश्यक मान को निर्धारित करता है। न्यूरॉन का सक्रियण मान कई घटकों के योग के रूप में गणना किया जाता है, जो आगमन का एक भारित योग है। वजन और इनपुट मान नोड्स के सूचकांक पर निर्भर करते हैं जो सक्रियण मान की गणना के लिए उपयोग किए जाते हैं। एक और संख्या को भी ध्यान में रखना होगा जब सक्रियण मान की गणना की जाती है, एक पूर्वाग्रह मान। पूर्वाग्रह मान नहीं बदलते हैं, इसलिए वे वजन और इनपुट के साथ गुणा नहीं किए जाते हैं, वे बस जोड़े जाते हैं। इसका मतलब है कि निम्नलिखित समीकरण का उपयोग सक्रियण मान की गणना के लिए किया जा सकता है:
सक्रियण = योग(वजन * इनपुट) + पूर्वाग्रह
एक बार न्यूरॉन सक्रिय हो जाने के बाद, एक सक्रियण कार्य का उपयोग न्यूरॉन के वास्तविक आउटपुट का निर्धारण करने के लिए किया जाता है। विभिन्न सक्रियण कार्य विभिन्न सीखने कार्यों के लिए उपयुक्त होते हैं, लेकिन सामान्य रूप से उपयोग किए जाने वाले सक्रियण कार्यों में सिग्मॉइड कार्य, टैन्ह कार्य, और रीलू कार्य शामिल हैं।
एक बार न्यूरॉन के आउटपुट की गणना सक्रियण मान को वांछित सक्रियण कार्य के माध्यम से चलाने के बाद की जाती है, तो आगे का प्रसार किया जाता है। आगे का प्रसार केवल एक परत के आउटपुट को अगली परत के इनपुट के रूप में लेना है। नए इनपुट का उपयोग करके नए सक्रियण कार्यों की गणना की जाती है, और इस ऑपरेशन का आउटपुट अगली परत में पारित किया जाता है। यह प्रक्रिया तंत्रिका नेटवर्क के अंत तक जारी रहती है।
नेटवर्क में बैकप्रोपेगेशन
बैकप्रोपेगेशन प्रक्रिया मॉडल के प्रशिक्षण पास के अंतिम निर्णयों को लेती है, और फिर यह निर्णयों में त्रुटियों का निर्धारण करती है। त्रुटियों की गणना नेटवर्क के आउटपुट/निर्णयों और नेटवर्क के अपेक्षित/वांछित आउटपुट के बीच के अंतर के द्वारा की जाती है।
एक बार नेटवर्क के निर्णयों में त्रुटियों की गणना की जाती है, तो यह जानकारी नेटवर्क के माध्यम से पीछे की ओर प्रसारित की जाती है और नेटवर्क के पैरामीटर्स को रास्ते में बदल दिया जाता है। नेटवर्क के वजन को अपडेट करने के लिए उपयोग की जाने वाली विधि कैलकुलस में आधारित है, विशेष रूप से यह श्रृंखला नियम में आधारित है। हालांकि, बैकप्रोपेगेशन के पीछे के विचार को समझने के लिए कैलकुलस की समझ की आवश्यकता नहीं है। बस यह जानें कि जब एक न्यूरॉन से आउटपुट मान प्राप्त किया जाता है, तो आउटपुट मान की ढलान की गणना एक ट्रांसफर कार्य के साथ की जाती है, जो एक व्युत्पन्न आउटपुट का उत्पादन करती है। बैकप्रोपेगेशन करते समय, एक विशिष्ट न्यूरॉन के लिए त्रुटि की गणना निम्नलिखित सूत्र के अनुसार की जाती है:
त्रुटि = (अपेक्षित_आउटपुट – वास्तविक_आउटपुट) * न्यूरॉन के आउटपुट मान की ढलान
जब आउटपुट परत के न्यूरॉन्स पर काम किया जाता है, तो अपेक्षित मान के रूप में वर्ग मान का उपयोग किया जाता है। एक बार त्रुटि की गणना की जाती है, तो त्रुटि को छिपी हुई परत के न्यूरॉन्स के लिए इनपुट के रूप में उपयोग किया जाता है, जिसका अर्थ है कि छिपी हुई परत के लिए त्रुटि आउटपुट परत के न्यूरॉन्स में त्रुटियों का एक भारित योग है। त्रुटि गणना नेटवर्क के माध्यम से पीछे की ओर यात्रा करती है, वजन के साथ।
एक बार नेटवर्क के लिए त्रुटियों की गणना की जाती है, तो नेटवर्क के वजन को अपडेट करना होगा। जैसा कि उल्लेख किया गया है, त्रुटि की गणना में आउटपुट मान की ढलान का निर्धारण शामिल है। एक बार ढलान की गणना की जाती है, तो ग्रेडिएंट डिसेंट नामक एक प्रक्रिया का उपयोग नेटवर्क के वजन को समायोजित करने के लिए किया जा सकता है। एक ग्रेडिएंट एक ढलान है, जिसका कोण/तीव्रता को मापा जा सकता है। ढलान की गणना “y over” या “राइज” को “रन” के साथ plot करके की जाती है। न्यूरल नेटवर्क और त्रुटि दर के मामले में, “y” गणना की गई त्रुटि है, जबकि “x” नेटवर्क के पैरामीटर हैं। नेटवर्क के पैरामीटर का त्रुटि मानों के साथ एक संबंध है, और जब नेटवर्क के वजन को समायोजित किया जाता है, तो त्रुटि बढ़ जाती है या घट जाती है।
“ग्रेडिएंट डिसेंट” वजन को अपडेट करने की प्रक्रिया है ताकि त्रुटि दर कम हो जाए। बैकप्रोपेगेशन न्यूरल नेटवर्क के पैरामीटर और त्रुटि दर के बीच संबंध की भविष्यवाणी करने के लिए उपयोग किया जाता है, जो नेटवर्क को ग्रेडिएंट डिसेंट के लिए तैयार करता है। एक नेटवर्क को ग्रेडिएंट डिसेंट के साथ प्रशिक्षित करने में वजन की गणना आगे के प्रसार के माध्यम से, त्रुटि को पीछे की ओर प्रसारित करना, और फिर नेटवर्क के वजन को अपडेट करना शामिल है।








