Künstliche Intelligenz
Umgestaltung von Gesichtern in Videos mit Machine Learning

Eine Forschungskooperation zwischen China und dem Vereinigten Königreich hat eine neue Methode entwickelt, um Gesichter in Videos umzugestalten. Die Technik ermöglicht eine überzeugende Verbreiterung und Verengung der Gesichtsstruktur, mit hoher Konsistenz und ohne Artefakte.
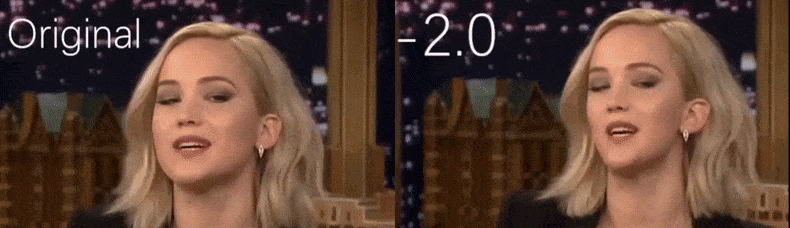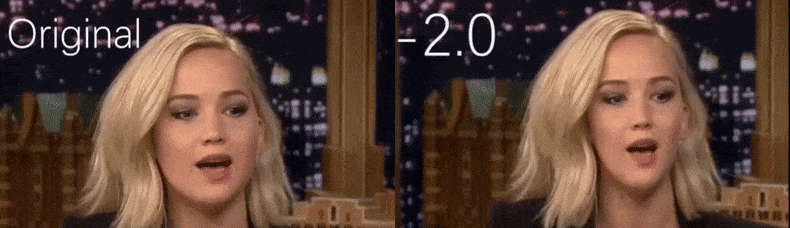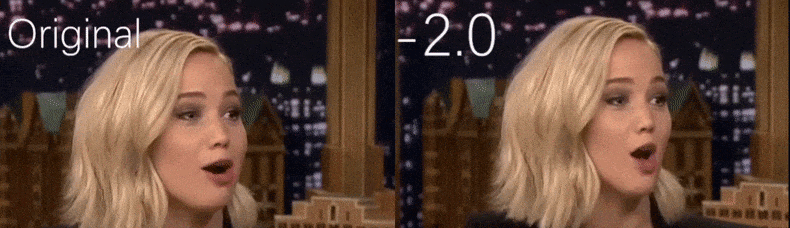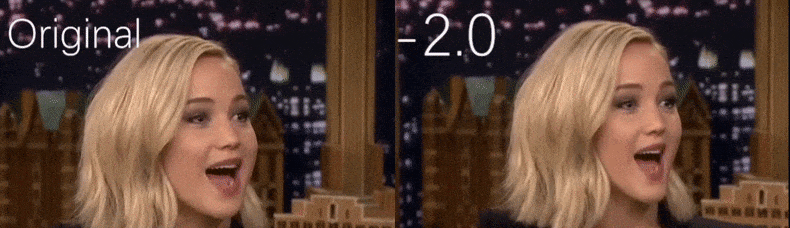
Aus einem YouTube-Video, das von den Forschern als Quellenmaterial verwendet wurde, erscheint die Schauspielerin Jennifer Lawrence als eine mehr hohlwangige Persönlichkeit (rechts). Siehe das begleitende Video am Ende des Artikels für viele weitere Beispiele in besserer Auflösung. Quelle: https://www.youtube.com/watch?v=tA2BxvrKvjE
Diese Art von Transformation ist normalerweise nur durch traditionelle CGI-Methoden möglich, die das Gesicht vollständig neu erstellen müssten, indem sie detaillierte und teure Motion-Capping-, Rigging- und Texturierungsverfahren verwenden.
Stattdessen wird die CGI in der Technik in eine neuronale Pipeline integriert, indem parametrizierte 3D-Gesichtsinformationen verwendet werden, die anschließend als Grundlage für einen Machine-Learning-Workflow dienen.

Traditionelle parametrizierte Gesichter werden zunehmend als Richtlinien für transformative Prozesse verwendet, die AI anstelle von CGI verwenden. Quelle: https://arxiv.org/pdf/2205.02538.pdf
Die Autoren erklären:
‘Unser Ziel ist es, hochwertige Portrait-Videos mit einer Bearbeitung der Gesamtförmigkeit der Portrait-Gesichter entsprechend der natürlichen Gesichtsdeformation in der realen Welt zu erzeugen. Dies kann für Anwendungen wie die Erzeugung von Gesichtsformen für die Verschönerung und die Überbetonung von Gesichtszügen für visuelle Effekte verwendet werden.’
Obwohl 2D-Gesichtsverzerrung und -verformung seit dem Aufkommen von Photoshop (und zu seltsamen und oft unannehmbaren Subkulturen um Gesichtsverzerrung und Körperschematismus geführt hat), ist es ein schwieriger Trick, dies in Videos ohne CGI zu erreichen.

Mark Zuckerbergs Gesichtsdimensionen wurden mit der neuen chinesisch-britischen Technik erweitert und verengt.
Körperumgestaltung ist derzeit ein Bereich von intensivem Interesse im Bereich der Computer-Vision, hauptsächlich aufgrund seines Potenzials im Fashion-E-Commerce, obwohl es derzeit eine beachtliche Herausforderung ist, jemanden größer oder skelettartig vielfältiger erscheinen zu lassen.
Ebenso ist die Änderung der Form eines Kopfes in Videoaufnahmen auf konsistente und überzeugende Weise Gegenstand von vorherigen Arbeiten der Forscher des neuen Papiers, obwohl diese Umsetzung unter Artefakten und anderen Einschränkungen litt. Die neue Methode erweitert die Fähigkeit dieser vorherigen Forschung von statischen zu Video-Ausgaben.
Das neue System wurde auf einem Desktop-PC mit einem AMD Ryzen 9 3950X und 32 GB Speicher trainiert und verwendet einen optischen Fluss-Algorithmus aus OpenCV für Bewegungskarten, die durch den StructureFlow-Rahmen geglättet werden; das Facial Alignment Network (FAN) für die Landmarkenschätzung, das auch in den beliebten Deepfake-Paketen verwendet wird; und den Ceres Solver, um Optimierungsprobleme zu lösen.

Ein extremes Beispiel für die Verbreiterung des Gesichts mit dem neuen System.
Das Papier trägt den Titel Parametrizierte Umgestaltung von Porträts in Videos und stammt von drei Forschern der Zhejiang-Universität und einem Forscher der Universität Bath.
Über Gesichter
Unter dem neuen System wird das Video in eine Bildsequenz extrahiert und eine starre Pose wird zunächst für jedes Gesicht geschätzt. Dann werden eine repräsentative Anzahl von nachfolgenden Frames gemeinsam geschätzt, um konsistente Identitätsparameter entlang der gesamten Bildsequenz (d. h. die Frames des Videos) zu konstruieren.

Architekturfluss des Gesichtsverformungssystems.
Anschließend wird der Ausdruck ausgewertet, was zu einem Umgestaltungsparameter führt, der durch lineare Regression implementiert wird. Als Nächstes konstruiert ein neuer signierter Abstands-Funktion (SDF)-Ansatz eine dichte 2D-Zuordnung der Gesichtsmerkmale vor und nach der Umgestaltung.
Schließlich wird eine inhaltsbewusste Verformungsoptimierung auf dem Ausgabevideo durchgeführt.
Parametrizierte Gesichter
Der Prozess nutzt ein 3D-Morphable-Face-Modell (3DMM), ein zunehmend beliebtes Hilfsmittel für neuronale und GAN-basierte Gesichtssynthese-Systeme, sowie anwendbar für Deepfake-Erkennungssysteme.

Nicht aus dem neuen Papier, sondern ein Beispiel für ein 3D-Morphable-Face-Modell (3DMM) – ein parametriziertes Prototyp-Gesicht, das im neuen Projekt verwendet wird. Oben links, Landmarkenanwendung auf einem 3DMM-Gesicht. Oben rechts, die 3D-Mesh-Vertices eines Isomaps. Unten links zeigt Landmarkenanpassung; unten mittig, ein Isomap der extrahierten Gesichtstextur; und unten rechts, eine resultierende Anpassung und Form. Quelle: http://www.ee.surrey.ac.uk/CVSSP/Publications/papers/Huber-VISAPP-2016.pdf
Der Workflow des neuen Systems muss Fälle von Okklusion berücksichtigen, wie z. B. ein Fall, in dem der Betrachter wegschaut. Dies ist eine der größten Herausforderungen in Deepfake-Software, da FAN-Landmarken wenig Kapazität haben, um diese Fälle zu berücksichtigen, und tendenziell in der Qualität abnehmen, wenn das Gesicht sich abwendet oder okkludiert wird.
Das neue System kann dieser Falle entgehen, indem es eine Kontur-Energie definiert, die in der Lage ist, die Grenze zwischen dem 3D-Gesicht (3DMM) und dem 2D-Gesicht (wie durch FAN-Landmarken definiert) zu entsprechen.
Optimierung
Eine nützliche Bereitstellung für ein solches System wäre, Echtzeit-Deformationen umzusetzen, beispielsweise in Video-Chat-Filtern. Der aktuelle Rahmen ermöglicht dies nicht, und die erforderlichen Rechenressourcen würden eine “Live”-Deformation zu einer beachtlichen Herausforderung machen.
Laut dem Papier und unter der Annahme eines 24-Bildern-pro-Sekunde-Videosziels stellen die pro-Rahmen-Operationen in der Pipeline eine Latenz von 16,344 Sekunden pro Sekunde des Footage dar, mit zusätzlichen Einmal-Kosten für die Identitätsschätzung und die 3D-Gesichtsdeformation (321 ms und 160 ms).
Daher ist die Optimierung entscheidend, um Fortschritte bei der Reduzierung der Latenz zu machen. Da eine gemeinsame Optimierung über alle Frames einen schwerwiegenden Overhead für den Prozess hinzufügen würde und eine init-ähnliche Optimierung (unter der Annahme der konsistenten nachfolgenden Identität des Sprechers aus dem ersten Frame) zu Anomalien führen könnte, haben die Autoren ein sparsames Schema zur Berechnung der Koeffizienten von Frames entwickelt, die in praktischen Abständen abgetastet werden.
Die gemeinsame Optimierung wird dann auf diesem Teilrahmen durchgeführt, was zu einem schlankeren Prozess der Rekonstruktion führt.
Gesichtsverformung
Die Verformungstechnik, die in dem Projekt verwendet wird, ist eine Anpassung der Arbeit der Autoren von 2020 Deep Shapely Portraits (DSP).

Deep Shapely Portraits, ein Beitrag von 2020 zur ACM Multimedia. Das Papier wird von Forschern des ZJU-Tencent Game and Intelligent Graphics Innovation Technology Joint Lab geleitet. Quelle: http://www.cad.zju.edu.cn/home/jin/mm2020/demo.mp4
Die Autoren bemerken ‘Wir erweitern diese Methode von der Umgestaltung eines monokularen Bildes zur Umgestaltung der gesamten Bildsequenz.’
Tests
Das Papier bemerkt, dass es keine vergleichbaren vorherigen Materialien gab, gegen die die neue Methode bewertet werden konnte. Daher verglichen die Autoren Frames des verwandelten Video-Ausgangs mit statischem DSP-Ausgang.

Testen des neuen Systems gegen statische Bilder von Deep Shapely Portraits.
Die Autoren stellen fest, dass Artefakte aus der DSP-Methode resultieren, aufgrund ihrer Verwendung von sparsamer Abbildung – ein Problem, das das neue Framework mit dichter Abbildung löst. Zusätzlich, so behauptet das Papier, zeigt das Video, das von DSP produziert wird, einen Mangel an Glätte und visueller Kohärenz.
Die Autoren erklären:
‘Die Ergebnisse zeigen, dass unser Ansatz robust kohärente umgestaltete Portrait-Videos produzieren kann, während die bildbasierte Methode leicht zu auffälligen Flicker-Artefakten führen kann.’
Sieh dir das begleitende Video unten an, für weitere Beispiele:
Erstveröffentlicht am 9. Mai 2022. Geändert am 6. Mai, um ‘Feld’ durch ‘Funktion’ für SDF zu ersetzen.












