Künstliche Intelligenz
Nein, sie haben Claude nicht gewürgt – es war sogar noch schlimmer

Okay, lasst uns darüber reden, was passiert ist mit Claude, denn wenn Sie es im letzten Monat verwendet haben, ist Ihnen wahrscheinlich aufgefallen, dass etwas nicht stimmte.
In den letzten sechs Wochen haben die Claude-Benutzer den Verstand verloren. Seit Anfang August Beschwerden überschwemmten Reddit, X und EntwicklerforenDie Probleme waren vielfältig:
- Code, der vorher perfekt funktionierte, war plötzlich kaputt
- Claude behauptete, es habe Änderungen an Dateien vorgenommen, obwohl dies nicht der Fall war.
- Zufällige thailändische oder chinesische Zeichen erscheinen in englischen Antworten
- Anweisungen werden völlig ignoriert
- Dieselbe Eingabeaufforderung liefert völlig unterschiedliche Qualitätsantworten
- Claude Code-Benutzer sagen, es fühle sich im Vergleich zu vorher „lobotomisiert“ an
Die Beschwerden wurden so heftig, dass man Ende August davon überzeugt war, dass Anthropic Claude heimlich drosselte, um Geld zu sparen. Verschwörungstheorien kursierten überall – vielleicht reduzierten sie die Qualität während der Spitzenzeiten, vielleicht hatten sie heimlich ein günstigeres Modell eingebaut, vielleicht handelte es sich um eine absichtliche Verschlechterung, um die Serverkosten zu senken.
Benutzer zahlten für Claude Pro und bekam etwas, das sich wie Claude Lite anfühlte. Entwickler, die Workflows rund um Claude aufgebaut hatten, sahen plötzlich ihre Produktivität sinken. Allerdings hatten einige Benutzer überhaupt keine Probleme, was die Sache noch verwirrender machte.
Anthropic gibt endlich zu: Ja, wir hatten Probleme
Nach wochenlangen Beschwerden der Benutzer und wachsender Frustration Anthropic hat gerade eine umfangreiche technische Obduktion veröffentlicht das im Wesentlichen besagt: „Du hattest Recht. Claude war am Boden zerstört. Folgendes ist passiert.“
Und die Antwort ist interessant.
Es stellte sich heraus, dass es nicht nur ein Problem war. Es waren drei völlig unabhängige Infrastrukturfehler, die alle gleichzeitig auftraten und einen regelrechten Sturm der KI-Verschlechterung auslösten. Sie drosselten nicht. Sie sparten nicht an der Qualität. Es waren einfach drei verschiedene Dinge gleichzeitig kaputtgegangen, und sie brauchten sechs Wochen, um die Ursache vollständig zu verstehen und zu beheben.
Lassen Sie mich genau aufschlüsseln, was schiefgelaufen ist, denn dies ist tatsächlich ein hilfreicher Einblick in die Art und Weise, wie diese KI-Systeme auf eine Weise versagen können, die niemand vorhersieht.
Der Dreifach-Bug-Zusammenbruch: Eine Zeitleiste des Chaos
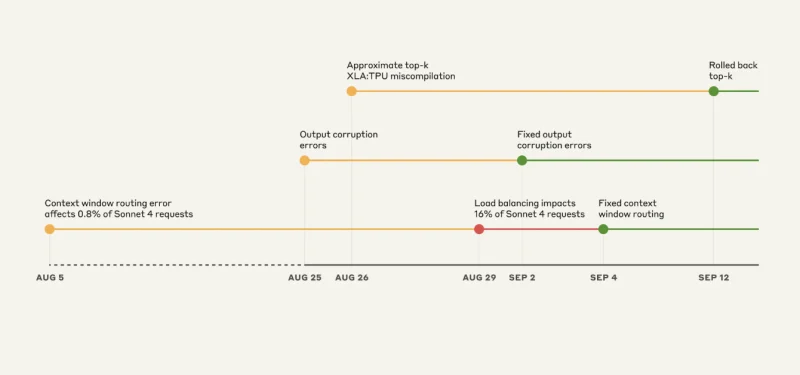
Quelle: Anthropisch
Fehler Nr. 1: Das Problem mit dem falschen Server
Das ist fast schon lustig, wenn man es nicht selbst erlebt hat. Claude Sonnet 4 wurde für die Verarbeitung von 200,000 Token-Kontexten entwickelt. Doch ab dem 5. August wurden einige Anfragen an Server weitergeleitet, die für eine Million Token-Kontexte konfiguriert waren.
Zunächst waren nur 0.8 % der Anfragen betroffen. Keine große Sache, oder? Falsch.
Am 29. August verwandelte ein routinemäßiges Update des Load Balancers dieses kleine Problem in ein großes. Plötzlich gingen in der Spitze 16 % der Sonnet 4-Anfragen an die falschen Server. Und das Routing war „klebrig“. Wer einmal falsch geroutet wurde, wurde immer wieder falsch geroutet.
Der Aufprall:
- Bei etwa 30 % der Claude Code-Benutzer, die während des Zeitfensters aktiv waren, wurde mindestens eine Anfrage fehlgeleitet.
- Reaktionszeiten für betroffene Benutzer stark verkürzt
- Bei demselben Benutzer trat das Problem wiederholt auf, während bei anderen keinerlei Probleme auftraten.
Fehler Nr. 2: Der Zufallszeichengenerator
Am 25. August führte Anthropic eine Fehlkonfiguration seiner TPU-Server durch. Die Folge war, dass Claude begann, willkürlich thailändische und chinesische Zeichen in englische Antworten einzufügen.
Stellen Sie sich vor, Sie bitten Claude, Ihren Python-Code zu debuggen und erhalten Folgendes:
def calculate_total(items):
total = 0
for item in items:
總計 += item.price # <- What?
return ผลรวม
Dies betraf:
- Opus 4.1 und Opus 4: 25.–28. August
- Sonett 4: 25. August – 2. September
Die technische Ursache war ein Fehler bei der Token-Generierung, der Zeichen, die dort nichts zu suchen hatten, eine hohe Wahrscheinlichkeit zuwies. Dadurch wurde der grundlegende Mechanismus, mit dem Claude sein nächstes Wort auswählt, buchstäblich zerstört.
Fehler Nr. 3: Der unsichtbare Compiler-Fehler
Aus technischer Sicht ist das der beängstigendste Fall. Es gab einen latenten Fehler im XLA-Compiler von Google, der lange Zeit ungenutzt herumlag. Als Anthropic am 25. August Code zur Verbesserung der Token-Auswahl einsetzte, löste das Unternehmen diesen Fehler versehentlich aus.
Dieser Fehler war wirklich bizarr: Er führte dazu, dass Claude beim Generieren von Text unbeabsichtigt das wahrscheinlichste Token ausschloss. Claude kannte die richtige Antwort, konnte sie aber physisch nicht aussprechen.
Und das Schlimmste daran? Sie hatten diesen Fehler im Dezember 2024 tatsächlich umgangen, ohne es zu merken. Als sie im August die vermeintliche Ursache „behoben“, entfernten sie die Problemumgehung und lösten damit das eigentliche Problem aus.
Warum die Behebung sechs Wochen dauerte
Sie fragen sich vielleicht: Wie kann ein Unternehmen wie Anthropic mit seinen erstklassigen Ingenieuren sechs Wochen brauchen, um das herauszufinden?
Die Antwort zeigt, wie komplex diese Systeme tatsächlich sind:
1. Datenschutzkontrollen blockierten das Debuggen
„Unsere internen Datenschutz- und Sicherheitskontrollen beschränken, wie und wann Ingenieure auf Benutzerinteraktionen mit Claude zugreifen können, insbesondere wenn uns diese Interaktionen nicht als Feedback gemeldet werden.“
Sie konnten buchstäblich nicht erkennen, was kaputt war, es sei denn, die Benutzer meldeten es ausdrücklich per Feedback. Gut für den Datenschutz, schrecklich für die Fehlerbehebung.
2. Die Käfer haben sich versteckt
Claude konnte sich oft von einzelnen Fehlern erholen, sodass die Verschlechterung eher wie eine normale Varianz als wie ein systematisches Versagen aussah. Ihre Benchmarks und Bewertungen erkannten dies nicht, da sich das Modell gerade so weit selbst korrigierte, dass es die Tests bestand.
3. Multiplattform-Chaos
Claude läuft auf AWS Trainium, NVIDIA GPUs und Google TPUs – drei völlig unterschiedliche Hardwareplattformen. Jeder Fehler manifestierte sich auf jeder Plattform anders:
- AWS Bedrock: 0.18 % der Sonnet 4-Anfragen in der Spitze betroffen
- Google Vertex AI: Weniger als 0.0004 % betroffen
- Direkte API: Bis zu 16 % betroffen
Dadurch sah es eher so aus, als lägen mehrere unabhängige Probleme vor und nicht drei spezifische Fehler.
4. Überlappende Symptome
Da drei Fehler gleichzeitig aktiv waren, traten die Symptome sehr unterschiedlich auf. Ein Benutzer erhielt möglicherweise thailändische Zeichen, ein anderer möglicherweise verschlechterte Antworten, ein dritter konnte möglicherweise eine einwandfreie Leistung feststellen. Es gab kein klares Muster.
Was dies tatsächlich für die Zuverlässigkeit der KI bedeutet
Diese ganze Saga enthüllt etwas Entscheidendes über den aktuellen Zustand von KI-Systemen: Sie sind viel fragiler, als es den Anschein macht.
Wir sprechen nicht nur über das KI-Modell selbst. Wir sprechen über:
- Routing-Infrastruktur, die Anfragen an den falschen Ort senden kann
- Hardwarespezifische Implementierungen, die sich unterschiedlich verhalten
- Compiler-Fehler, die monatelang unentdeckt bleiben können
- Lastverteiler, die kleinere Probleme zu größeren Ausfällen ausweiten können
Eine Fehlkonfiguration, ein Compiler-Fehler, ein Routing-Fehler – und plötzlich vergisst Ihr KI-Assistent das Programmieren oder beginnt, Sprachen zu sprechen, die er nicht sprechen sollte.
Ist es tatsächlich behoben?
Anthropic sagt, dass sie alle drei Probleme bis zum 16. September gelöst habenSie haben:
- Die Routing-Logik wurde korrigiert
- Die problematischen Konfigurationen wurden zurückgesetzt
- Von ungefähren auf exakte Top-k-Operationen umgestellt (wobei die Genauigkeit zu Lasten der Leistung geht).
- Kontinuierliche Produktionsüberwachung hinzugefügt
Doch Benutzer melden immer noch ProblemeEinige Entwickler behaupten, dass sich Claude Code im Vergleich zu seiner früheren Leistung immer noch schlechter anfühlt. Ob das nun daran liegt:
- Nachwirkungen der Bugs
- Neue Probleme, die noch nicht identifiziert wurden
- Psychologische Voreingenommenheit nach wochenlangen Problemen
- Oder tatsächlich fortgesetzte Verschlechterung
…das wissen wir noch nicht.
Fazit
Diese Situation ist ein perfektes Beispiel dafür, wie komplexe KI-Systeme auf völlig unerwartete Weise ausfallen können. Drei separate Fehler, die alle innerhalb weniger Wochen auftraten, erzeugten den Eindruck einer massiven Qualitätsminderung, deren Diagnose und Behebung sechs Wochen dauerte.
Wir müssen Anthropic für seine Transparenz loben. Die Veröffentlichung einer detaillierten technischen Analyse ist mehr, als die meisten Unternehmen tun würden. Es zeigt aber auch, wie viel hinter den Kulissen dieser Systeme, auf die wir uns zunehmend verlassen, schiefgehen kann.
Für alle, die auf Claude oder einem anderen LLM aufbauen: Sie benötigen Redundanz, Validierung und Backup-Pläne. Denn wie wir gerade gesehen haben, können selbst die besten KI-Systeme drei verschiedene Probleme gleichzeitig haben, und es kann Wochen dauern, bis jemand herausfindet, was tatsächlich los ist.
Die Infrastruktur, die diese KI-Modelle unterstützt, ist genauso wichtig wie die Modelle selbst. Und derzeit zeigt diese Infrastruktur einige ernsthafte Wachstumsschmerzen.












