Künstliche Intelligenz
Neue Deepfake-Methode löst das ‘Face-Host’-Problem

Trotz mehrerer Jahre medialer Übertreibung über das Potenzial von Deepfake-Bildern, unsere langjährige Überzeugung von der Authentizität von Videoaufnahmen zu untergraben, basieren alle derzeit populären Methoden auf der Suche nach ‘Face-Hosts’, die in Form und Größe dem Zielgesicht ähneln.
Wo das Originalvideo ein breites Gesicht zeigt, aber das Zielsubjekt ein schmales Gesicht hat, waren die Ergebnisse immer problematisch, da ein solcher Transfer das Abschneiden eines Teils des Originalgesichts und die Rekonstruktion des nun sichtbaren Hintergrunds beinhaltet. Aktuelle Pakete wie DeepFaceLab und FaceSwap können begrenzte Ergebnisse erzielen, wenn die Konfiguration umgekehrt ist (schmal > breit), aber sie haben keine Möglichkeit, diese Szene überzeugend zu meistern.
Jetzt hat eine Zusammenarbeit zwischen Tencent und der Xiamen-Universität in China einen neuen Ansatz entwickelt, der als HifiFace bezeichnet wird und darauf abzielt, diese Lücke zu schließen.

Zwei HifiFace-Deepfakes, der erste von Anne Hathaway, bei dem trotz unkompatibler Host-Gesichtsform eine gute Ähnlichkeit erzielt wird. HifiFace funktioniert auch gut bei Zielen mit Brillen, traditionell ein Hindernis bei Deepfakes. Quelle: https://arxiv.org/pdf/2106.09965.pdf
Umgestaltung eines Deepfake-Gesichts
Frühere Ansätze, wie 2019 Subject Agnostic Face Swapping and Reenactment (FSGAN), haben auf 3DMM-Fitting (3D-Morphable-Modelle) oder andere Methoden basierend auf Gesichtsmerkmal-Erkennung oder -Transformation gesetzt, bei denen die Gesichtsmerkmale des zu “überschreibenden” Gesichts mehr oder weniger die Grenzen des Austauschs diktierten:

3DMM-Gesichtsmerkmal-Erkennung. Quelle: https://github.com/Yinghao-Li/3DMM-fitting
Obwohl konkurrierende Methoden Merkmale aus Gesichtserkennungsnetzwerken verwendet haben, sind diese hauptsächlich darauf ausgerichtet, Texturen anstelle von Strukturen zu rekonstruieren und produzieren ähnlich eine “maskenartige” Wirkung in Fällen, in denen das Host-Gesicht nicht vollständig kompatibel ist (d. h. die Grenzen und Form von Haaransatz, Kinnlinie und Wangenknochen).
Um diese Probleme zu lösen, entwickelten die chinesischen Forscher, die im Media Analytics and Computing Lab der Universität im Department of Artificial Intelligence tätig sind, ein End-to-End-Netzwerk, das die Koeffizienten des Ziel- und des Quellgesichts unter Verwendung eines 3D-Rekonstruktionsmodells regressiert, das dann als Forminformation rekombiniert und mit Identitätsvektorinformationen aus einem Gesichtserkennungsnetzwerk verkettet wird.
Diese geometrischen Daten werden dann als Strukturinformation in ein Encoder-Decoder-Modell eingegeben, das mit dem Ausdruck und der Disposition des Zielgesichts vermischt, die als Hilfsquellen für eine genaue Übertragung genutzt werden.

Semantische Gesichtsverschmelzung
Darüber hinaus enthält HifiFace eine Komponente zur semantischen Gesichtsverschmelzung (SFF), die ein niedriges Merkmal im Encoder verwendet, um räumliche und Texturinformationen zu erhalten, ohne die Identität des Zielbildes zu opfern. Merkmale aus dem Encoder und Decoder werden in eine gelernte adaptive Maske integriert und die Hintergrundinformationen durch die gelernte Gesichtsmaske in die Ausgabe gemischt.

HifiFace in Aktion. Quelle: https://johann.wang/HifiFace/
Auf diese Weise weicht HifiFace von der Verwendung der ursprünglichen Materialgesichtsgrenzen als harte Grenze ab, indem es eine dilatierte Gesichtssemantik-Segmentierung verwendet, bei der das Modell eine bessere adaptive Verschmelzung an den Kanten des Gesichts durchführen kann.
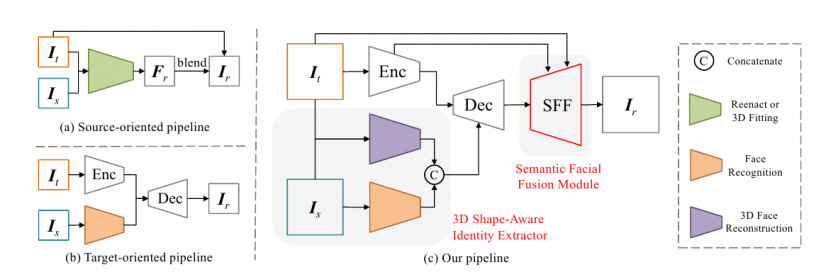
Zwei vorherige Ansätze (oben links und unten links) und die neue HifiFace-Architektur, die aus einem Encoder, Decoder, 3D-Form-Identitäts-Extraktor und SFF-Modul besteht.

In einem Vergleich mit früheren Methoden FSGAN, SimSwap und FaceShifter zeigt HifiFace eine überlegene Rekonstruktion der Gesichtsform, da es nicht “Geister”-Elemente approximiert, wo die Gesichtsgrenzen die Identitäts-Identitäts-Zuordnung verwirren, sondern sie definitiv rekonstruiert.

Testen
Die Forscher implementierten das System mit den VGGFace2– und DeepGlint-Asian-Celeb-Datensätzen. Gesichter wurden über 5 äußere Landmarken ausgerichtet und auf 256×256 Pixel zugeschnitten. Ein Portrait-Verbesserungsnetzwerk wurde auch verwendet, um eine 512×512-Pixel-Version zu generieren, für ein zusätzliches hochauflösendes Modell. Das Modell wurde unter Adam trainiert.

Obwohl FaceShifter die Identität gut bewahrt, kann es Probleme wie Ausdruck, Farbe und Verdeckung nicht so effektiv wie HifiFace angehen und hat eine komplexere Netzwerkstruktur. FSGAN hat Probleme beim Übertragen der Beleuchtung von der Quelle zum Ziel.
Die Forscher verwenden FaceForensics++ für quantitative Vergleiche, indem sie zehn Frames jedes in einer Charge von konvertierten Videos über die konkurrierenden Methoden auswählen und feststellen, dass HifiFace einen überlegenen ID-Rückgewinnungsscore erzielt. Bei der Überprüfung einer Reihe anderer Faktoren, wie Bildqualität, fanden die Forscher auch, dass ihre Methode die konkurrierenden Methoden übertraf.

Benedict Cumberbatchs Gesichtsmerkmale werden treu wiedergegeben.
Die Arbeit stellt einen weiteren Schritt in Richtung Abstraktion des Quellenmaterials dar, sodass es nur noch ein grobes Template ist, in das genaue Identitäten übertragen werden können. Einige der aktuellen FOSS-Pakete, einschließlich DeepFaceLab, verfügen über eine Keimfunktion für die vollständige Kopfersetzung, aber wie HifiFace berücksichtigen sie nicht das Haar und sind effektiver darin, ein Gesicht “aufzubauen”, als es zu meißeln, um es an eine gewünschte Zielquelle anzupassen.












