Künstliche Intelligenz
Wie Text-to-3D-KI-Generation funktioniert: Meta 3D Gen, OpenAI Shap-E und mehr
Von
Aayush Mittal Mittal
Die Fähigkeit, 3D-Digitalassets aus Textprompts zu generieren, stellt eine der aufregendsten jüngsten Entwicklungen in der KI und Computergrafik dar. Da der Markt für 3D-Digitalassets von 28,3 Milliarden Dollar im Jahr 2024 auf 51,8 Milliarden Dollar im Jahr 2029 wachsen soll, sind Text-to-3D-KI-Modelle bereit, eine wichtige Rolle bei der Revolutionierung der Content-Erstellung in Branchen wie Gaming, Film, E-Commerce und mehr zu spielen. Aber wie funktionieren diese KI-Systeme genau? In diesem Artikel werden wir uns mit den technischen Details hinter der Text-to-3D-Generierung auseinandersetzen.

Die Herausforderung der 3D-Generierung
Die Generierung von 3D-Assets aus Text ist eine wesentlich komplexere Aufgabe als die Generierung von 2D-Bildern. Während 2D-Bilder im Wesentlichen Gitter von Pixeln sind, erfordern 3D-Assets die Darstellung von Geometrie, Texturen, Materialien und oft Animationen im dreidimensionalen Raum. Diese zusätzliche Dimensionalität und Komplexität macht die Generierungsaufgabe viel herausfordernder.
Einige Schlüsselherausforderungen bei der Text-to-3D-Generierung sind:
- Darstellung von 3D-Geometrie und Struktur
- Generierung konsistenter Texturen und Materialien über die 3D-Oberfläche
- Sicherstellung der physikalischen Plausibilität und Kohärenz aus mehreren Blickwinkeln
- Erfassung feiner Details und globaler Struktur gleichzeitig
- Generierung von Assets, die leicht gerendert oder 3D-gedruckt werden können
Um diese Herausforderungen zu meistern, nutzen Text-to-3D-Modelle mehrere Schlüsseltechnologien und -techniken.
Schlüsselkomponenten von Text-to-3D-Systemen
Die meisten State-of-the-Art-Text-to-3D-Generierungssysteme teilen einige Kernkomponenten:
- Textcodierung: Umwandlung des Eingabetextprompts in eine numerische Darstellung
- 3D-Darstellung: Eine Methode zur Darstellung von 3D-Geometrie und Erscheinungsbild
- Generatives Modell: Das Kern-KI-Modell für die Generierung des 3D-Assets
- Rendering: Umwandlung der 3D-Darstellung in 2D-Bilder für die Visualisierung
Lassen Sie uns jedes davon genauer betrachten.
Textcodierung
Der erste Schritt besteht darin, den Eingabetextprompt in eine numerische Darstellung umzuwandeln, die das KI-Modell verarbeiten kann. Dies geschieht normalerweise mit Hilfe von großen Sprachmodellen wie BERT oder GPT.
3D-Darstellung
Es gibt mehrere gängige Methoden zur Darstellung von 3D-Geometrie in KI-Modellen:
- Voxel-Gitter: 3D-Arrays von Werten, die die Besetzung oder Merkmale darstellen
- Punktwolken: Mengen von 3D-Punkten
- Netze: Vertices und Flächen, die eine Oberfläche definieren
- Implizite Funktionen: Kontinuierliche Funktionen, die eine Oberfläche definieren (z. B. signierte Distanzfunktionen)
- Neuronale Strahlungsfelder (NeRFs): Neuronale Netze, die Dichte und Farbe im 3D-Raum darstellen
Jede hat Kompromisse in Bezug auf Auflösung, Speicherbedarf und Erzeugungsgeschwindigkeit. Viele aktuelle Modelle verwenden implizite Funktionen oder NeRFs, da sie hochwertige Ergebnisse mit vernünftigen Rechenanforderungen ermöglichen.
Beispielsweise können wir eine einfache Kugel als signierte Distanzfunktion darstellen:
import numpy as np
<p>def sphere_sdf(x, y, z, radius=1.0):</p>
<p>return np.sqrt(x**2 + y**2 + z**2) - radius</p>
<p># Auswertung von SDF an einem 3D-Punkt</p>
<p>point = [0.5, 0.5, 0.5]</p>
<p>distance = sphere_sdf(*point)</p>
<p>print(f"Abstand zur Kugeloberfläche: {distance}")</p>
Generatives Modell
Das Kernstück eines Text-to-3D-Systems ist das generative Modell, das die 3D-Darstellung aus dem Textembedding erzeugt. Die meisten State-of-the-Art-Modelle verwenden eine Variation eines Diffusionsmodells, ähnlich wie bei der 2D-Bildgenerierung.
Diffusionsmodelle funktionieren, indem sie allmählich Rauschen zu Daten hinzufügen und dann lernen, diesen Prozess umzukehren. Bei der 3D-Generierung geschieht dies im Raum der gewählten 3D-Darstellung.
Ein vereinfachter Pseudocode für einen Diffusionsmodell-TrainingsSchritt könnte wie folgt aussehen:
def diffusion_training_step(model, x_0, text_embedding):</p> <p># Zufälliger Zeitpunkt auswählen</p> <p>t = torch.randint(0, num_timesteps, (1,))</p> <p># Rauschen zum Eingabe hinzufügen</p> <p>noise = torch.randn_like(x_0)</p> <p>x_t = add_noise(x_0, noise, t)</p> <p># Vorhergesagtes Rauschen</p> <p>predicted_noise = model(x_t, t, text_embedding)</p> <p># Verlust berechnen</p> <p>loss = F.mse_loss(noise, predicted_noise)</p> <p>return loss</p> <p># TrainingsSchleife</p> <p>for batch in dataloader:</p> <p>x_0, text = batch</p> <p>text_embedding = encode_text(text)</p> <p>loss = diffusion_training_step(model, x_0, text_embedding)</p> <p>loss.backward()</p> <p>optimizer.step()</p>
Während der Generierung beginnen wir mit reinem Rauschen und denoisen wir schrittweise, bedingt auf dem Textembedding.
Rendering
Um Ergebnisse zu visualisieren und Verluste während des Trainings zu berechnen, müssen wir unsere 3D-Darstellung in 2D-Bilder umwandeln. Dies geschieht normalerweise mit Hilfe von differenzierbaren Rendering-Techniken, die es ermöglichen, Gradienten durch den Rendering-Prozess zu übertragen.
Für netzartige Darstellungen könnten wir einen Rasterisierungs-Renderer verwenden:
import torch import torch.nn.functional as F import pytorch3d.renderer as pr <p>def render_mesh(vertices, faces, image_size=256):</p> <p># Renderer erstellen</p> <p>renderer = pr.MeshRenderer(</p> <p>rasterizer=pr.MeshRasterizer(),</p> <p>shader=pr.SoftPhongShader()</p> <p>)</p> <p># Kamera einrichten</p> <p>cameras = pr.FoVPerspectiveCameras()</p> <p># Rendern</p> <p>images = renderer(vertices, faces, cameras=cameras)</p> <p>return images</p> <p># Beispielanwendung</p> <p>vertices = torch.rand(1, 100, 3) # Zufällige Vertices</p> <p>faces = torch.randint(0, 100, (1, 200, 3)) # Zufällige Flächen</p> <p>rendered_images = render_mesh(vertices, faces)</p>
Für implizite Darstellungen wie NeRFs verwenden wir normalerweise Ray-Marching-Techniken, um Ansichten zu rendern.
Alles zusammen: Die Text-to-3D-Pipeline
Jetzt, da wir die Schlüsselkomponenten abgedeckt haben, lassen Sie uns durch die typische Text-to-3D-Generierungspipeline gehen:
- Textcodierung: Der Eingabetextprompt wird in eine dichte Vektor-Darstellung umgewandelt, indem ein Sprachmodell verwendet wird.
- Erste Generierung: Ein Diffusionsmodell, bedingt auf dem Textembedding, generiert eine erste 3D-Darstellung (z. B. ein NeRF oder eine implizite Funktion).
- Mehrblick-Konsistenz: Das Modell rendert mehrere Ansichten des generierten 3D-Assets und stellt sicher, dass diese konsistent sind.
- Verfeinerung: Zusätzliche Netze können die Geometrie, Texturen oder Details verfeinern.
- Endgültige Ausgabe: Die 3D-Darstellung wird in ein gewünschtes Format (z. B. texturiertes Netz) umgewandelt, um in nachgelagerten Anwendungen verwendet zu werden.
Hier ist ein vereinfachtes Beispiel, wie dies in Code aussehen könnte:
class TextTo3D(nn.Module):</p>
<p>def __init__(self):</p>
<p>super().__init__()</p>
<p>self.text_encoder = BertModel.from_pretrained('bert-base-uncased')</p>
<p>self.diffusion_model = DiffusionModel()</p>
<p>self.refiner = RefinerNetwork()</p>
<p>self.renderer = DifferentiableRenderer()</p>
<p>def forward(self, text_prompt):</p>
<p># Text codieren</p>
<p>text_embedding = self.text_encoder(text_prompt).last_hidden_state.mean(dim=1)</p>
<p># Erste 3D-Darstellung generieren</p>
<p>initial_3d = self.diffusion_model(text_embedding)</p>
<p># Mehrere Ansichten rendern</p>
<p>views = self.renderer(initial_3d, num_views=4)</p>
<p># Basierend auf Mehrblick-Konsistenz verfeinern</p>
<p>refined_3d = self.refiner(initial_3d, views)</p>
<p>return refined_3d</p>
<p># Verwendung</p>
<p>model = TextTo3D()</p>
<p>text_prompt = "Ein roter Sportwagen"</p>
<p>generated_3d = model(text_prompt)</p>
Top-Text-to-3D-Asset-Modelle
3DGen – Meta
3DGen ist dafür ausgelegt, das Problem der Generierung von 3D-Inhalten wie Charakteren, Requisiten und Szenen aus Textbeschreibungen zu lösen.
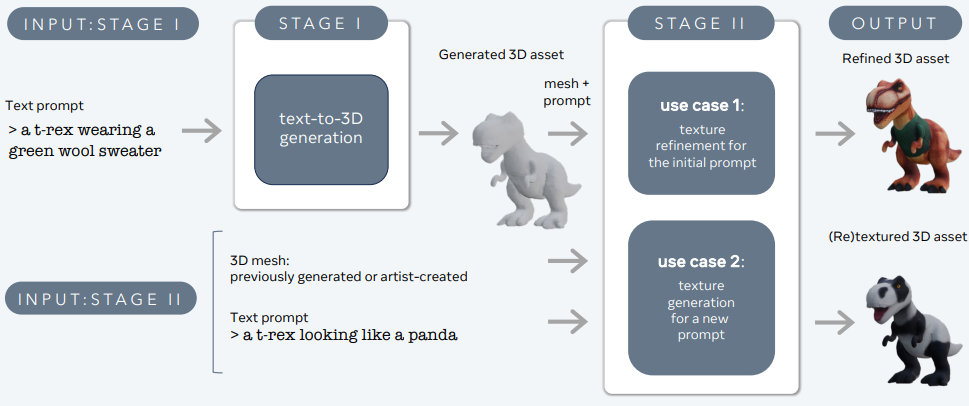
Large Language and Text-to-3D-Modelle – 3d-gen
3DGen unterstützt physikalisch basiertes Rendering (PBR), das für die realistische Beleuchtung von 3D-Assets in realen Anwendungen unerlässlich ist. Es ermöglicht auch die generative Neutexturierung vorher generierter oder von Künstlern erstellter 3D-Formen mithilfe neuer Texteingaben. Die Pipeline integriert zwei Kernkomponenten: Meta 3D AssetGen und Meta 3D TextureGen, die Text-to-3D- und Text-to-Texture-Generierung verarbeiten.
Meta 3D AssetGen
Meta 3D AssetGen (Siddiqui et al., 2024) ist für die erste Generierung von 3D-Assets aus Textprompts verantwortlich. Diese Komponente produziert ein 3D-Netz mit Texturen und PBR-Materialkarten in etwa 30 Sekunden.
Meta 3D TextureGen
Meta 3D TextureGen (Bensadoun et al., 2024) verfeinert die von AssetGen generierten Texturen. Es kann auch verwendet werden, um neue Texturen für bestehende 3D-Netze basierend auf zusätzlichen Textbeschreibungen zu generieren. Diese Phase dauert etwa 20 Sekunden.
Point-E (OpenAI)
Point-E, entwickelt von OpenAI, ist ein weiteres bemerkenswertes Text-to-3D-Generierungsmodell. Im Gegensatz zu DreamFusion, das NeRF-Darstellungen produziert, generiert Point-E 3D-Punktwolken.
Schlüsselmerkmale von Point-E:
a) Zweistufige Pipeline: Point-E generiert zunächst eine synthetische 2D-Ansicht mithilfe eines Text-to-Image-Diffusionsmodells und verwendet dann diese Ansicht, um ein zweites Diffusionsmodell zu konditionieren, das die 3D-Punktwolke produziert.
b) Effizienz: Point-E ist für eine hohe Rechenleistung ausgelegt und kann 3D-Punktwolken in Sekunden auf einem einzelnen GPU generieren.
c) Farbinformation: Das Modell kann farbige Punktwolken generieren und sowohl geometrische als auch Erscheinungsinformationen bewahren.
Einschränkungen:
- Geringere Qualität im Vergleich zu netz- oder NeRF-basierten Ansätzen
- Punktwolken erfordern für viele nachgelagerte Anwendungen zusätzliche Verarbeitung
Shap-E (OpenAI):
Basierend auf Point-E führte OpenAI Shap-E ein, das 3D-Netze anstelle von Punktwolken generiert. Dies behebt einige der Einschränkungen von Point-E, während die Rechenleistung beibehalten wird.
Schlüsselmerkmale von Shap-E:
a) Implizite Darstellung: Shap-E lernt, implizite Darstellungen (signierte Distanzfunktionen) von 3D-Objekten zu generieren.
b) Netzextraktion: Das Modell verwendet einen differenzierbaren Marching-Cubes-Algorithmus, um die implizite Darstellung in ein polygonales Netz umzuwandeln.
c) Texturgenerierung: Shap-E kann auch Texturen für die 3D-Netze generieren, was zu visuell ansprechenderen Ergebnissen führt.
Vorteile:
- Schnelle Generierungszeiten (Sekunden bis Minuten)
- Direktes Netz-Ausgabe, geeignet für Rendering und nachgelagerte Anwendungen
- Fähigkeit, sowohl Geometrie als auch Texturen zu generieren
GET3D (NVIDIA):
GET3D, entwickelt von NVIDIA-Forschern, ist ein weiteres leistungsstarkes Text-to-3D-Generierungsmodell, das sich auf die Produktion von hochwertigen, texturierten 3D-Netzen konzentriert.
Schlüsselmerkmale von GET3D:
a) Explizite Oberflächendarstellung: Im Gegensatz zu DreamFusion oder Shap-E generiert GET3D explizite Oberflächendarstellungen (Netze) ohne Zwischenschritte mit impliziten Darstellungen.
b) Texturgenerierung: Das Modell umfasst eine differenzierbare Rendering-Technik, um hochwertige Texturen für die 3D-Netze zu lernen und zu generieren.
c) GAN-basierte Architektur: GET3D verwendet einen generativen adversativen Netzwerkansatz, der eine schnelle Generierung ermöglicht, sobald das Modell trainiert ist.
Vorteile:
- Hochwertige Geometrie und Texturen
- Schnelle Inferenzzeiten
- Direkte Integration in 3D-Rendering-Engines
Einschränkungen:
- Benötigt 3D-Trainingsdaten, die für einige Objektkategorien knapp sein können
Fazit
Text-to-3D-KI-Generierung stellt einen grundlegenden Wandel in der Art und Weise dar, wie wir 3D-Inhalte erstellen und damit interagieren. Durch den Einsatz fortschrittlicher Deep-Learning-Techniken können diese Modelle komplexe, hochwertige 3D-Assets aus einfachen Textbeschreibungen erzeugen. Da die Technologie weiterentwickelt wird, können wir erwarten, immer komplexere und leistungsfähigere Text-to-3D-Systeme zu sehen, die Branchen von Gaming und Film bis hin zu Produktgestaltung und Architektur revolutionieren werden.
Ich habe die letzten fünf Jahre damit verbracht, mich in die faszinierende Welt des Machine Learning und Deep Learning zu vertiefen. Mein Engagement und meine Expertise haben mich dazu geführt, an über 50 verschiedenen Software-Entwicklungsprojekten mit einem besonderen Fokus auf AI/ML beizutragen. Meine anhaltende Neugier hat mich auch zum Bereich der Natural Language Processing hingezogen, einem Feld, das ich weiter erforschen möchte.

You may like


Der Wettlauf um Künstliche Intelligenz verschärft sich: AMDs strategische Partnerschaft mit OpenAI


OpenAI sichert sich siebenjährige, 38-Milliarden-Dollar-AWS-Cloud-Partnerschaft


Optimierung von Neuralen Radiance-Feldern (NeRF) für Echtzeit-3D-Rendering in E-Commerce-Plattformen


Claudes Model Context Protocol (MCP): Ein Entwickler-Leitfaden


Entwurfsmuster in Python für KI- und LLM-Ingenieure: Ein Praxisleitfaden


Microsoft AutoGen: Multi-Agenten-KI-Workflows mit erweiterter Automatisierung







