Künstliche Intelligenz
KI hilft nervösen Rednern, das ‘Zimmer zu lesen’ während Videokonferenzen

Im Jahr 2013 ergab eine Umfrage über häufige Phobien, dass die Aussicht auf öffentliches Sprechen für die Mehrheit der Befragten schlimmer war als die Aussicht auf den Tod. Das Syndrom ist als Glossophobie bekannt.
Die durch COVID ausgelöste Migration von “persönlichen” Treffen zu Online-Zoom-Konferenzen auf Plattformen wie Zoom und Google Spaces hat überraschenderweise die Situation nicht verbessert. Wenn die Besprechung eine große Anzahl von Teilnehmern enthält, werden unsere natürlichen Bedrohungsbeurteilungsfähigkeiten durch die niedrige Auflösung der Teilnehmerreihen und -symbole sowie die Schwierigkeit, subtile visuelle Signale von Gesichtsausdruck und Körpersprache zu lesen, beeinträchtigt. Skype zum Beispiel wurde als schlechte Plattform für die Übermittlung nicht-verbaler Hinweise befunden.
Die Auswirkungen auf die Leistung des öffentlichen Sprechens durch wahrgenommene Interesse und Responsivität sind inzwischen gut dokumentiert und intuitiv offensichtlich für die meisten von uns. Eine undurchsichtige Zuhörerreaktion kann dazu führen, dass Redner zögern und auf Füllwörter zurückgreifen, ohne zu wissen, ob ihre Argumente auf Zustimmung, Verachtung oder Desinteresse stoßen, was oft zu einem unangenehmen Erlebnis für sowohl den Redner als auch seine Zuhörer führt.
Unter dem Druck der unerwarteten Verschiebung hin zu Online-Videokonferenzen, inspiriert durch COVID-Beschränkungen und Vorsichtsmaßnahmen, verschlechtert sich das Problem möglicherweise, und eine Reihe von Verbesserungsvorschlägen für Zuhörer-Feedback-Systeme wurde in den letzten beiden Jahren in den Computer-Vision- und Affect-Forschungsgemeinschaften vorgeschlagen.
Hardware-orientierte Lösungen
Die meisten davon erfordern jedoch zusätzliche Ausrüstung oder komplexe Software, die Datenschutz- oder Logistikprobleme aufwerfen können – relativ teure oder anderweitig ressourcenbeschränkte Ansätze, die die Pandemie vorausgehen. Im Jahr 2001 schlug das MIT den Galvactivator vor, ein handgetragenes Gerät, das den emotionalen Zustand des Zuhörers ableitet, der während eines eintägigen Symposiums getestet wurde.

Von 2001, MIT’s Galvactivator, der die Hautleitfähigkeitsreaktion misst, um Zuhörer-Stimmung und Engagement zu verstehen. Quelle: https://dam-prod.media.mit.edu/x/files/pub/tech-reports/TR-542.pdf
Eine große Menge akademischer Energie wurde auch der möglichen Bereitstellung von “Klickern” als Audience Response System (ARS) gewidmet, eine Maßnahme, um die aktive Teilnahme der Zuhörer zu erhöhen (was automatisch die Engagement steigert, da es den Zuhörer in die Rolle eines aktiven Feedback-Knotens zwingt), aber auch als Mittel zur Redner-Ermunterung vorgeschlagen.
Andere Versuche, Redner und Zuhörer zu “verbinden”, umfassten Herzfrequenz-Überwachung, den Einsatz komplexer Körper-getragener Ausrüstung, um Elektroenzephalographie zu nutzen, “Beifall-Meter”, computer-vision-basierte Emotions-Erkennung für arbeitsplatzgebundene Mitarbeiter und den Einsatz von Zuhörer-gesendeten Emoticons während der Rede des Redners.

Von 2017, der EngageMeter, ein gemeinsames akademisches Forschungsprojekt von LMU München und der Universität Stuttgart. Quelle: http://www.mariamhassib.net/pubs/hassib2017CHI_3/hassib2017CHI_3.pdf
Als Teilbereich des lukrativen Bereichs der Zuhörer-Analytik hat der private Sektor ein besonderes Interesse an Blickschätzung und -verfolgung – Systemen, bei denen jeder Zuhörer (der möglicherweise selbst einmal sprechen wird), einer Ocular-Verfolgung unterzogen wird, als Index von Engagement und Billigung.
All diese Methoden sind ziemlich reibungslos. Viele davon erfordern spezielle Hardware, Laborumgebungen, spezielle und maßgeschneiderte Software-Frameworks und Abonnements teurer kommerzieller APIs – oder eine Kombination dieser einschränkenden Faktoren.
Daher ist die Entwicklung minimalistischer Systeme, die auf nicht mehr als den gängigen Tools für Videokonferenzen basieren, in den letzten 18 Monaten von Interesse geworden.
Zuhörer-Billigung diskret melden
Zu diesem Zweck bietet eine neue Forschungszusammenarbeit zwischen der Universität Tokyo und der Carnegie Mellon University ein neuartiges System, das auf standardmäßigen Videokonferenz-Tools (wie Zoom) aufsetzen kann, indem es nur eine web-kamera-aktivierte Website verwendet, auf der leichte Blick- und Pose-Schätzung-Software läuft. Auf diese Weise wird sogar die Notwendigkeit lokaler Browser-Plugins vermieden.
Die Nicken und die geschätzte Blick-Aufmerksamkeit des Benutzers werden in repräsentative Daten übersetzt, die dem Redner visualisiert werden, um einen “Live”-Litmustest dafür zu ermöglichen, in welchem Maße der Inhalt das Publikum anspricht – und auch zumindest einen vagen Hinweis auf Perioden der Rede, in denen der Redner das Interesse des Publikums verlieren könnte.
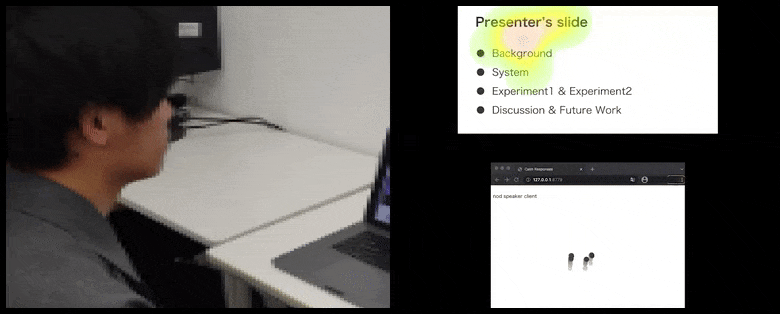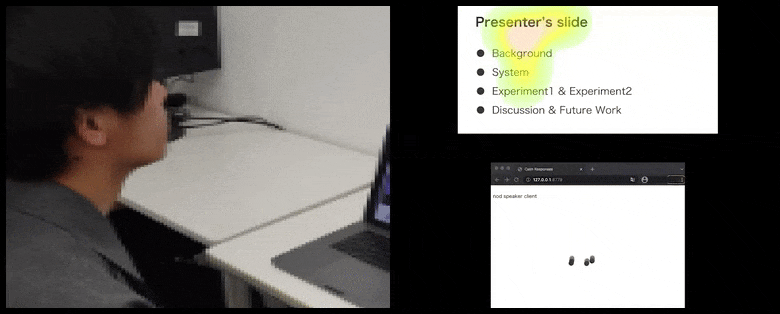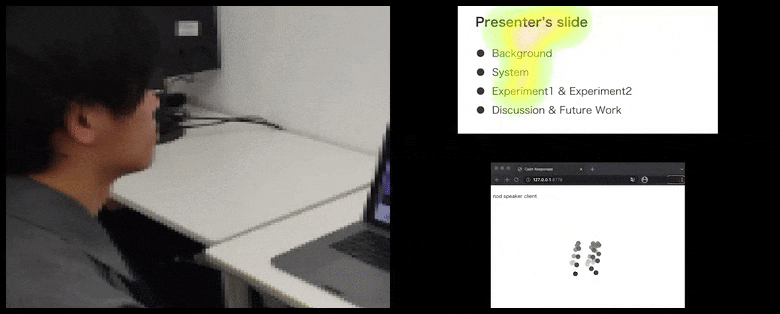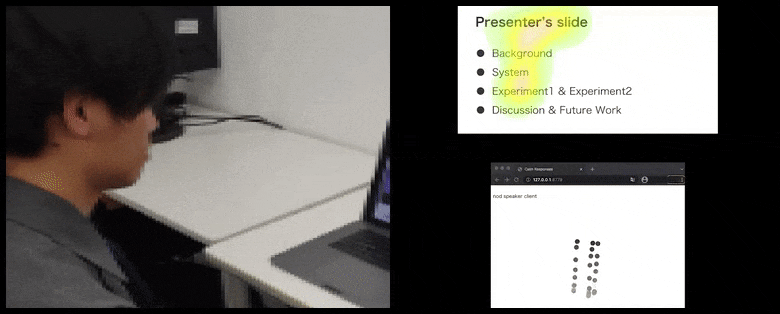
Mit CalmResponses wird die Aufmerksamkeit und das Nicken des Benutzers zu einem Pool von Zuhörer-Feedback hinzugefügt und in eine visuelle Darstellung übersetzt, die dem Redner zugute kommen kann. Siehe eingebettetes Video am Ende des Artikels für weitere Details und Beispiele. Quelle: https://www.youtube.com/watch?v=J_PhB4FCzk0
In vielen akademischen Situationen, wie Online-Vorlesungen, können die Studenten möglicherweise vom Redner nicht gesehen werden, da sie ihre Kameras nicht eingeschaltet haben, weil sie sich über ihren Hintergrund oder ihr aktuelles Aussehen unsicher fühlen. CalmResponses kann dieses Hindernis für Redner-Feedback angehen, indem es meldet, was es über die Art und Weise weiß, wie der Redner auf den Inhalt schaut, und ob er nickt, ohne dass der Zuhörer seine Kamera aktivieren muss.
Das Paper ist betitelt CalmResponses: Displaying Collective Audience Reactions in Remote Communication und ist eine gemeinsame Arbeit von zwei Forschern der UoT und einem Forscher der Carnegie Mellon.
Die Autoren bieten eine Live-Web-Demo an und haben den Quellcode auf GitHub veröffentlicht.
Das CalmResponses-Framework
CalmResponses’ Interesse an Nicken, im Gegensatz zu anderen möglichen Kopfbewegungen, basiert auf Forschung (einige davon reichen bis in die Ära von Darwin zurück), die zeigt, dass mehr als 80% aller Zuhörer-Kopfbewegungen aus Nicken bestehen (auch wenn sie Uneinigkeit ausdrücken). Gleichzeitig wurde gezeigt, dass Blickbewegungen ein zuverlässiger Index von Interesse oder Engagement sind.
CalmResponses wird mit HTML, CSS und JavaScript implementiert und besteht aus drei Subsystemen: einem Zuhörer-Client, einem Redner-Client und einem Server. Der Zuhörer-Client übermittelt Blick- oder Kopfbewegungsdaten des Benutzers von der Webcam über WebSockets auf die Cloud-Anwendungsplattform Heroku.

Zuhörer-Nicken werden rechts in einer animierten Bewegung unter CalmResponses visualisiert. In diesem Fall ist die Bewegungsvisualisierung nicht nur für den Redner, sondern für das gesamte Publikum verfügbar. Quelle: https://arxiv.org/pdf/2204.02308.pdf
Für den Blick-Verfolgungsteil des Projekts verwendeten die Forscher WebGazer, ein leichtes, JavaScript-basiertes Browser-basiertes Blick-Verfolgungs-Framework, das mit niedriger Latenz direkt von einer Website aus laufen kann (siehe Link oben für die eigene web-basierte Implementierung der Forscher).
Da die Notwendigkeit einer einfachen Implementierung und einer groben, aggregierten Reaktionserkennung die Notwendigkeit hoher Genauigkeit bei Blick- und Pose-Schätzung überwiegt, werden die Eingabedaten vor der Berücksichtigung für die Gesamtreaktionsschätzung gemittelt.
Die Nicken-Aktion wird über die JavaScript-Bibliothek clmtrackr ausgewertet, die Gesichtsmodelle auf erkannte Gesichter in Bildern oder Videos durch regulierte Landmarken-Mittelwert-Verfolgung anpasst. Aus Gründen der Wirtschaftlichkeit und niedriger Latenz wird nur das erkannte Landmark für die Nase aktiv überwacht, da dies ausreicht, um Nicken-Aktionen zu verfolgen.
Die Bewegung der Nasenspitze des Benutzers erzeugt eine Spur, die zum Pool von Zuhörer-Feedback im Zusammenhang mit Nicken beiträgt, das in einer aggregierten Weise allen Teilnehmern visualisiert wird.
Heatmap
Während die Nicken-Aktivität durch dynamische bewegliche Punkte dargestellt wird (siehe Bilder oben und Video am Ende), wird die visuelle Aufmerksamkeit in Form einer Heatmap gemeldet, die dem Redner und dem Publikum zeigt, wo der allgemeine Fokus der Aufmerksamkeit auf dem gemeinsamen Präsentationsbildschirm oder der Videokonferenz-Umgebung liegt.

Alle Teilnehmer können sehen, wo die allgemeine Benutzer-Aufmerksamkeit fokussiert ist. Das Paper erwähnt nicht, ob diese Funktionalität verfügbar ist, wenn der Benutzer eine ‘Galerie’ anderer Teilnehmer sehen kann, was eine scheinbare Fokussierung auf einen bestimmten Teilnehmer aus verschiedenen Gründen aufdecken könnte.
Tests
Zwei Testumgebungen wurden für CalmResponses in Form einer stillschweigenden Ablationsstudie formuliert, die drei verschiedene Umstände verwendet: in ‘Bedingung B’ (Basislinie) replizierten die Autoren eine typische Online-Studentenvorlesung, bei der die meisten Studenten ihre Webkameras ausgeschaltet hatten und der Redner keine Möglichkeit hatte, die Gesichter des Publikums zu sehen; in ‘Bedingung CR-E’ konnte der Redner Blick-Rückmeldungen (Heatmaps) sehen; in ‘Bedingung CR-N’ konnte der Redner sowohl Nicken- als auch Blick-Aktivitäten des Publikums sehen.
Die erste experimentelle Szene umfasste Bedingung B und Bedingung CR-E; die zweite umfasste Bedingung B und Bedingung CR-N. Rückmeldungen wurden von sowohl den Rednern als auch dem Publikum erhalten.
In jedem Experiment wurden drei Faktoren ausgewertet: objektive und subjektive Bewertung der Präsentation (einschließlich eines Selbstberichts-Fragebogens des Redners über seine Gefühle darüber, wie die Präsentation verlaufen war); die Anzahl der Ereignisse von “Füllworten”, die auf momentane Unsicherheit und Zögern hinweisen; und qualitative Kommentare. Diese Kriterien sind gemeinsame Schätzer der Sprechqualität und Redner-Angst.
Die Testgruppe bestand aus 38 Personen im Alter von 19-44 Jahren, darunter 29 Männer und neun Frauen mit einem Durchschnittsalter von 24,7 Jahren, alle japanisch oder chinesisch und alle fließend in Japanisch. Sie wurden zufällig in fünf Gruppen von 6-7 Teilnehmern aufgeteilt, und keine der Teilnehmer kannte sich persönlich.
Die Tests wurden auf Zoom durchgeführt, mit fünf Rednern, die in dem ersten Experiment und sechs in dem zweiten Experiment Präsentationen hielten.

Füllbedingungen als orangefarbene Kästchen markiert. Im Allgemeinen sank der Füllinhalt in vernünftigem Verhältnis zur erhöhten Zuhörer-Rückmeldung vom System.
Die Forscher bemerken, dass die Füllwörter eines Redners erheblich abnahmen und dass in ‘Bedingung CR-N’ der Redner nur selten Füllwörter äußerte. Siehe das Paper für die sehr detaillierten und granularen Ergebnisse; jedoch waren die auffälligsten Ergebnisse in der subjektiven Bewertung durch die Redner und Zuhörer.
Kommentare des Publikums umfassten:
‘Ich fühlte mich in die Präsentationen involviert” [AN2], “Ich war mir nicht sicher, ob die Reden der Redner verbessert wurden, aber ich fühlte ein Gefühl der Einheit durch die Visualisierung der Kopfbewegungen der anderen.’ [AN6]
‘Ich war mir nicht sicher, ob die Reden der Redner verbessert wurden, aber ich fühlte ein Gefühl der Einheit durch die Visualisierung der Kopfbewegungen der anderen.’
Die Forscher bemerken, dass das System eine neue Art von künstlicher Pause in die Präsentation des Redners einführt, da der Redner geneigt ist, auf die visuelle Systematik zu verweisen, um Zuhörer-Rückmeldungen zu bewerten, bevor er weitermacht.
Sie bemerken auch einen “Weißkittel-Effekt”, der in experimentellen Umständen schwer zu vermeiden ist, bei dem einige Teilnehmer sich durch die möglichen Sicherheitsimplikationen der Überwachung von biometrischen Daten eingeschränkt fühlten.
Schlussfolgerung
Ein bemerkenswerter Vorteil in einem System wie diesem ist, dass alle nicht-standardmäßigen Zusatztechnologien, die für einen solchen Ansatz erforderlich sind, nach ihrer Verwendung vollständig verschwinden. Es gibt keine verbleibenden Browser-Plugins, die deinstalliert werden müssen, oder die Zweifel in den Köpfen der Teilnehmer aufkommen lassen, ob sie auf ihren jeweiligen Systemen verbleiben sollten; und es gibt keine Notwendigkeit, die Benutzer durch den Prozess der Installation zu führen (obwohl das web-basierte Framework etwa eine Minute oder zwei der initialen Kalibrierung durch den Benutzer erfordert), oder die Möglichkeit zu navigieren, dass Benutzer nicht die erforderlichen Berechtigungen haben, lokale Software zu installieren, einschließlich browser-basierter Add-ons und Erweiterungen.
Obwohl die bewerteten Gesichts- und Ocular-Bewegungen nicht so präzise sind, wie sie in Umständen sein könnten, in denen dedizierte lokale Machine-Learning-Frameworks (wie die YOLO-Serie) verwendet werden, bietet dieser fast reibungslose Ansatz zur Zuhörer-Bewertung ausreichende Genauigkeit für breite Stimmungs- und Haltungsanalyse in typischen Videokonferenz-Szenarien. Vor allem ist es sehr billig.
Siehe das zugehörige Projekt-Video unten für weitere Details und Beispiele.
Erstveröffentlicht am 11. April 2022.












