AI Models & Platforms
Zero123++: A Single Image to Consistent Multi-view Diffusion Base Model

The past few years has witnessed a rapid advancement in the performance, efficiency, and generative capabilities of emerging novel AI generative models that leverage extensive datasets, and 2D diffusion generation practices. Today, generative AI models are extremely capable of generating different forms of 2D, and to some extent, 3D media content including text, images, videos, GIFs, and more.
In this article, we will be talking about the Zero123++ framework, an image-conditioned diffusion generative AI model with the aim to generate 3D-consistent multiple-view images using a single view input. To maximize the advantage gained from prior pretrained generative models, the Zero123++ framework implements numerous training and conditioning schemes to minimize the amount of effort it takes to finetune from off-the-shelf diffusion image models. We will be taking a deeper dive into the architecture, working, and the results of the Zero123++ framework, and analyze its capabilities to generate consistent multiple-view images of high quality from a single image. So let’s get started.
Zero123 and Zero123++: An Introduction
The Zero123++ framework is an image-conditioned diffusion generative AI model that aims to generate 3D-consistent multiple-view images using a single view input. The Zero123++ framework is a continuation of the Zero123 or Zero-1-to-3 framework that leverages zero-shot novel view image synthesis technique to pioneer open-source single-image -to-3D conversions. Although the Zero123++ framework delivers promising performance, the images generated by the framework have visible geometric inconsistencies, and it’s the main reason why the gap between 3D scenes, and multi-view images still exists.
The Zero-1-to-3 framework serves as the foundation for several other frameworks including SyncDreamer, One-2-3-45, Consistent123, and more that add extra layers to the Zero123 framework to obtain more consistent results when generating 3D images. Other frameworks like ProlificDreamer, DreamFusion, DreamGaussian, and more follow an optimization-based approach to obtain 3D images by distilling a 3D image from various inconsistent models. Although these techniques are effective, and they generate satisfactory 3D images, the results could be improved with the implementation of a base diffusion model capable of generating multi-view images consistently. Accordingly, the Zero123++ framework takes the Zero-1 to-3, and finetunes a new multi-view base diffusion model from Stable Diffusion.
In the zero-1-to-3 framework, each novel view is independently generated, and this approach leads to inconsistencies between the views generated as diffusion models have a sampling nature. To tackle this issue, the Zero123++ framework adopts a tiling layout approach, with the object being surrounded by six views into a single image, and ensures the correct modeling for the joint distribution of an object’s multi-view images.
Another major challenge faced by developers working on the Zero-1-to-3 framework is that it underutilizes the capabilities offered by Stable Diffusion that ultimately leads to inefficiency, and added costs. There are two major reasons why the Zero-1-to-3 framework cannot maximize the capabilities offered by Stable Diffusion
- When training with image conditions, the Zero-1-to-3 framework does not incorporate local or global conditioning mechanisms offered by Stable Diffusion effectively.
- During training, the Zero-1-to-3 framework uses reduced resolution, an approach in which the output resolution is reduced below the training resolution that can reduce the quality of image generation for Stable Diffusion models.
To tackle these issues, the Zero123++ framework implements an array of conditioning techniques that maximizes the utilization of resources offered by Stable Diffusion, and maintains the quality of image generation for Stable Diffusion models.
Improving Conditioning and Consistencies
In an attempt to improve image conditioning, and multi-view image consistency, the Zero123++ framework implemented different techniques, with the primary objective being reusing prior techniques sourced from the pretrained Stable Diffusion model.
Multi-View Generation
The indispensable quality of generating consistent multi-view images lies in modeling the joint distribution of multiple images correctly. In the Zero-1-to-3 framework, the correlation between multi-view images is ignored because for every image, the framework models the conditional marginal distribution independently and separately. However, in the Zero123++ framework, developers have opted for a tiling layout approach that tiles 6 images into a single frame/image for consistent multi-view generation, and the process is demonstrated in the following image.
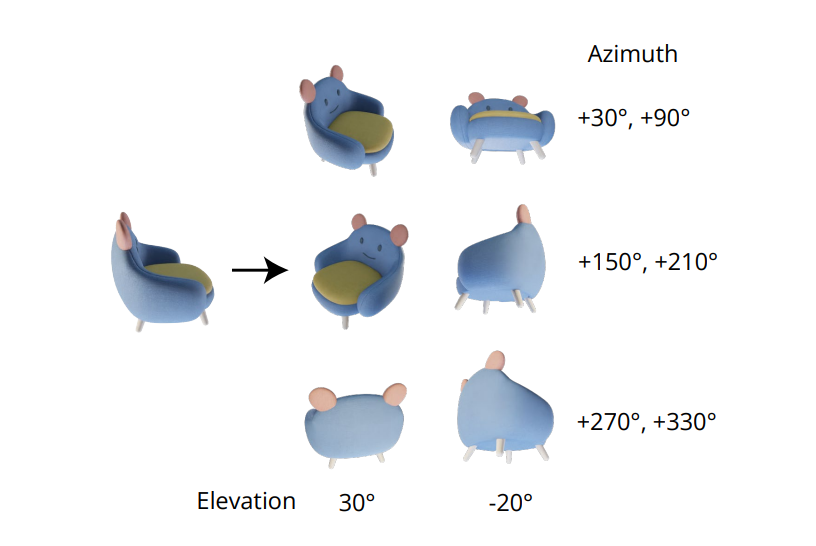

Furthermore, it has been noticed that object orientations tend to disambiguate when training the model on camera poses, and to prevent this disambiguation, the Zero-1-to-3 framework trains on camera poses with elevation angles and relative azimuth to the input. To implement this approach, it is necessary to know the elevation angle of the view of the input that is then used to determine the relative pose between novel input views. In an attempt to know this elevation angle, frameworks often add an elevation estimation module, and this approach often comes at the cost of additional errors in the pipeline.
Noise Schedule
Scaled-linear schedule, the original noise schedule for Stable Diffusion focuses primarily on local details, but as it can be seen in the following image, it has very few steps with lower SNR or Signal to Noise Ratio.


These steps of low Signal to Noise Ratio occur early during the denoising stage, a stage crucial for determining the global low-frequency structure. Reducing the number of steps during the denoising stage, either during interference or training often results in a greater structural variation. Although this setup is ideal for single-image generation it does limit the ability of the framework to ensure global consistency between different views. To overcome this hurdle, the Zero123++ framework finetunes a LoRA model on the Stable Diffusion 2 v-prediction framework to perform a toy task, and the results are demonstrated below.

With the scaled-linear noise schedule, the LoRA model does not overfit, but only whitens the image slightly. Conversely, when working with the linear noise schedule, the LoRA framework generates a blank image successfully irrespective of the input prompt, thus signifying the impact of noise schedule on the ability of the framework to adapt to new requirements globally.
Scaled Reference Attention for Local Conditions
The single view input or the conditioning images in the Zero-1-to-3 framework is concatenated with the noisy inputs in the feature dimension to be noised for image conditioning.
This concatenation leads to an incorrect pixel-wise spatial correspondence between the target image, and the input. To provide proper local conditioning input, the Zero123++ framework makes use of a scaled Reference Attention, an approach in which running a denoising UNet model is referred on an extra reference image, followed by the appendation of value matrices and self-attention key from the reference image to the respective attention layers when the model input is denoised, and it is demonstrated in the following figure.

The Reference Attention approach is capable of guiding the diffusion model to generate images sharing resembling texture with the reference image, and semantic content without any finetuning. With fine tuning, the Reference Attention approach delivers superior results with the latent being scaled.

Global Conditioning : FlexDiffuse
In the original Stable Diffusion approach, the text embeddings are the only source for global embeddings, and the approach employs the CLIP framework as a text encoder to perform cross-examinations between the text embeddings, and the model latents. Resultantly, developers are free to use the alignment between the text spaces, and the resultant CLIP images to use it for global image conditionings.
The Zero123++ framework proposes to make use of a trainable variant of the linear guidance mechanism to incorporate the global image conditioning into the framework with minimal fine-tuning needed, and the results are demonstrated in the following image. As it can be seen, without the presence of a global image conditioning, the quality of the content generated by the framework is satisfactory for visible regions that correspond to the input image. However, the quality of the image generated by the framework for unseen regions witnesses significant deterioration which is mainly because of the model’s inability to infer the object’s global semantics.

Model Architecture
The Zero123++ framework is trained with the Stable Diffusion 2v-model as the foundation using the different approaches and techniques mentioned in the article. The Zero123++ framework is pre-trained on the Objaverse dataset that is rendered with random HDRI lighting. The framework also adopts the phased training schedule approach used in the Stable Diffusion Image Variations framework in an attempt to further minimize the amount of fine-tuning required, and preserve as much as possible in the prior Stable Diffusion.
The working or architecture of the Zero123++ framework can be further divided into sequential steps or phases. The first phase witnesses the framework fine-tune the KV matrices of cross-attention layers, and the self-attention layers of Stable Diffusion with AdamW as its optimizer, 1000 warm-up steps and the cosine learning rate schedule maximizing at 7×10-5. In the second phase, the framework employs a highly conservative constant learning rate with 2000 warm up sets, and employs the Min-SNR approach to maximize the efficiency during the training.
Zero123++ : Results and Performance Comparison
Qualitative Performance
To assess the performance of the Zero123++ framework on the basis of its quality generated, it is compared against SyncDreamer, and Zero-1-to-3- XL, two of the finest state of the art frameworks for content generation. The frameworks are compared against four input images with different scope. The first image is an electric toy cat, taken directly from the Objaverse dataset, and it boasts of a large uncertainty on the rear end of the object. Second is the image of a fire extinguisher, and the third one is the image of a dog sitting on a rocket, generated by the SDXL model. The final image is an anime illustration. The required elevation steps for the frameworks are achieved by using the One-2-3-4-5 framework’s elevation estimation method, and background removal is achieved using the SAM framework. As it can be seen, the Zero123++ framework generates high quality multi-view images consistently, and is capable of generalizing to out-of-domain 2D illustration, and AI-generated images equally well.


Quantitative Analysis
To quantitatively compare the Zero123++ framework against state of the art Zero-1-to-3 and Zero-1to-3 XL frameworks, developers evaluate the Learned Perceptual Image Patch Similarity (LPIPS) score of these models on the validation split data, a subset of the Objaverse dataset. To evaluate the model’s performance on multi-view image generation, the developers tile the ground truth reference images, and 6 generated images respectively, and then compute the Learned Perceptual Image Patch Similarity (LPIPS) score. The results are demonstrated below and as it can be clearly seen, the Zero123++ framework achieves the best performance on the validation split set.

Text to Multi-View Evaluation
To evaluate Zero123++ framework’s ability in Text to Multi-View content generation, developers first use the SDXL framework with text prompts to generate an image, and then employ the Zero123++ framework to the image generated. The results are demonstrated in the following image, and as it can be seen, when compared to the Zero-1-to-3 framework that cannot guarantee consistent multi-view generation, the Zero123++ framework returns consistent, realistic, and highly detailed multi-view images by implementing the text-to-image-to-multi-view approach or pipeline.

Zero123++ Depth ControlNet
In addition to the base Zero123++ framework, developers have also released the Depth ControlNet Zero123++, a depth-controlled version of the original framework built using the ControlNet architecture. The normalized linear images are rendered in respect with the subsequent RGB images, and a ControlNet framework is trained to control the geometry of the Zero123++ framework using depth perception.


Conclusion
In this article, we have talked about Zero123++, an image-conditioned diffusion generative AI model with the aim to generate 3D-consistent multiple-view images using a single view input. To maximize the advantage gained from prior pretrained generative models, the Zero123++ framework implements numerous training and conditioning schemes to minimize the amount of effort it takes to finetune from off-the-shelf diffusion image models. We have also discussed the different approaches and enhancements implemented by the Zero123++ framework that helps it achieve results comparable to, and even exceeding those achieved by current state of the art frameworks.
However, despite its efficiency, and ability to generate high-quality multi-view images consistently, the Zero123++ framework still has some room for improvement, with potential areas of research being a
- Two-Stage Refiner Model that might solve Zero123++’s inability to meet global requirements for consistency.
- Additional Scale-Ups to further enhance Zero123++’s ability to generate images of even higher quality.










