Погляд Anderson
Чому атакування зображень є серйозною проблемою
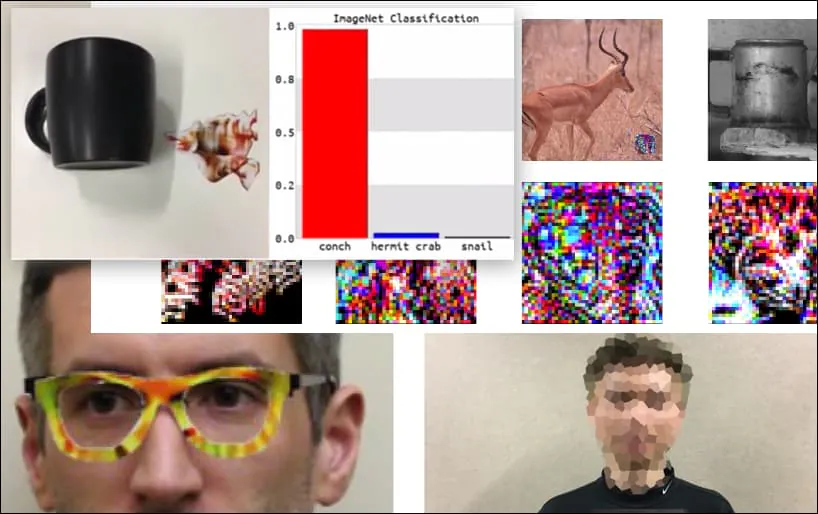
Атакування систем розпізнавання зображень за допомогою спеціально створених зображень було розглянуто як забавна, але тривіальна демонстрація концепції протягом останніх п’яти років. Однак нове дослідження в Австралії свідчить про те, що необдумане використання дуже популярних наборів даних зображень для комерційних проектів штучного інтелекту може створити тривалу нову проблему безпеки.
already рік група вчених з Університету Аделаїди намагається пояснити щось дуже важливе про майбутнє систем розпізнавання зображень на основі штучного інтелекту.
Це щось, що було б складно (і дуже дорого) виправити зараз, і що буде абсолютно недопустимо дорогим для виправлення, коли поточні тенденції в дослідженнях розпізнавання зображень будуть повністю розроблені в комерційних і промислових розгортаннях через 5-10 років.
Перед тим, як ми перейдемо до цього, давайте розглянемо квітку, класифіковану як президент Барак Обама, з однієї з шести відео, які команда опублікувала на сторінці проекту:
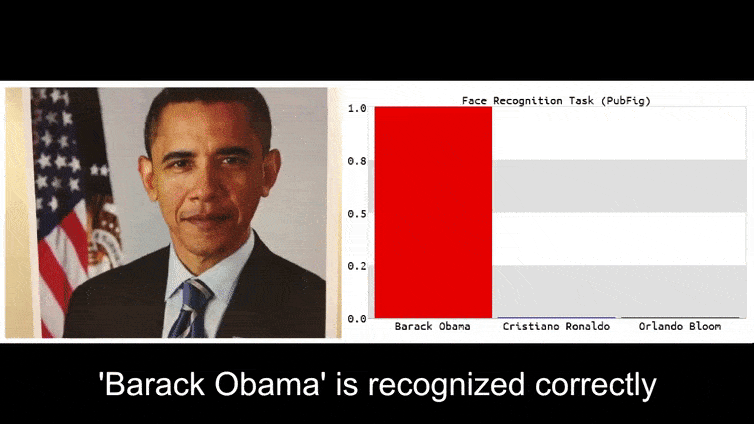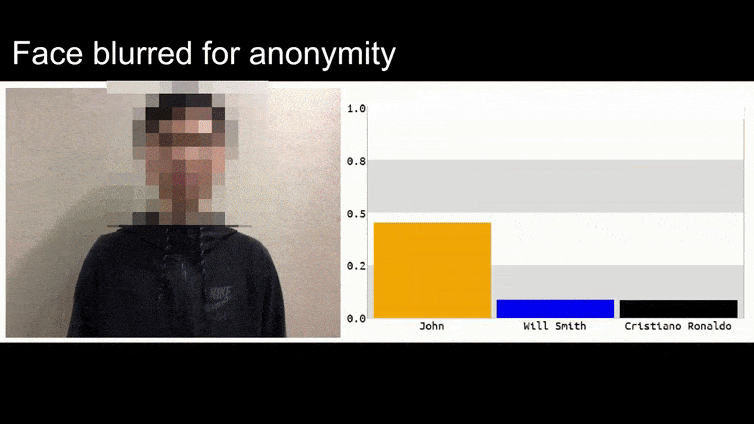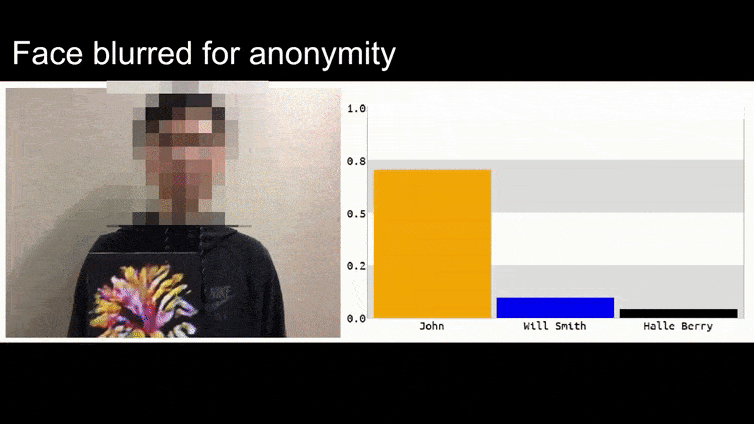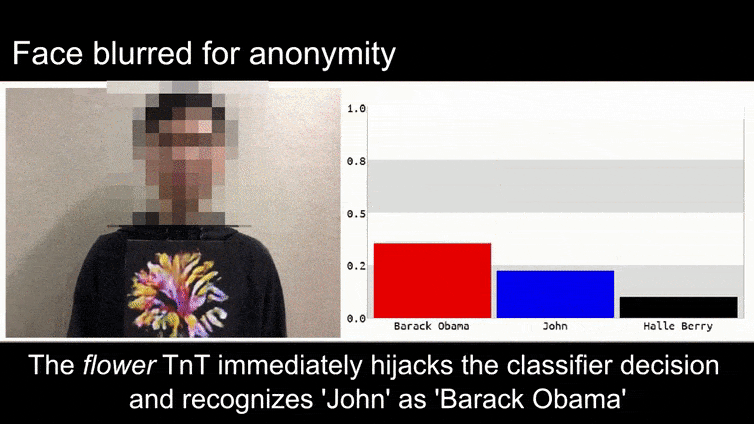
Джерело: https://www.youtube.com/watch?v=Klepca1Ny3c
У вищезазначеному зображенні система розпізнавання облич, яка явно знає, як розпізнавати Барака Обаму, обманюється на 80% впевненості, що анонімізований чоловік, який тримає спеціально створене, надруковане зображення квітки, також є Бараком Обамою. Система навіть не звертає уваги на те, що “фальшиве обличчя” знаходиться на грудях суб’єкта, а не на його плечах.
Хоча це вражаюче, що дослідники змогли досягти такого роду ідентифікації, генеруючи узгоджене зображення (квітку) замість звичайного випадкового шуму, здається, що такі глупі експлойти з’являються досить часто в дослідженнях безпеки комп’ютерного бачення. Наприклад, ті дивні плямисті окуляри, які могли обманути розпізнавання облич у 2016 році, або спеціально створені зображення, які спробують переписати дорожні знаки.
Якщо вас цікавить, модель нейронної мережі (CNN), яку атакують у вищезазначеному прикладі, є VGGFace (VGG-16), навчена на наборі даних PubFig Колумбійського університету. Інші зразки атак, розроблені дослідниками, використовували різні ресурси в різних комбінаціях.

Клавіатура перекласифікована як конх, у моделі WideResNet50 на ImageNet. Дослідники також забезпечили, щоб модель не мала упередженості щодо конхів. Дивіться повне відео для розширених і додаткових демонстрацій на https://www.youtube.com/watch?v=dhTTjjrxIcU
Розпізнавання зображень як новий вектор атаки
Багатьма вражаючими атаками, які дослідники описують і ілюструють, не є критикою окремих наборів даних або конкретних архітектур машинного навчання, які їх використовують. Ані не можуть вони бути легко захищені шляхом зміни наборів даних або моделей, повторної навчанням моделей або іншими “легкими” засобами, які викликають у фахівців з машинного навчання зневагу до спорадичних демонстрацій цього роду хитрощів.
Натомість, експлойти команди Аделаїди демонструють центральну слабкість у всій поточній архітектурі розробки штучного інтелекту для розпізнавання зображень; слабкість, яка могла б поставити багато майбутніх систем розпізнавання зображень під легке маніпулювання атакувальниками, і поставити будь-які подальші захисні заходи на задню ногу.
Уявіть собі останні зображення атак (наприклад, квітку вище) як “zero-day експлойти”, які додаються до систем безпеки майбутнього, так само, як поточні антивірусні та анти-шпигунські програми оновлюють свої визначення вірусів щодня.
Потенціал для нових атак на зображення буде вичерпний, оскільки фундаментальна архітектура системи не передбачала подальших проблем, як це сталося з інтернетом, мілленіум-багом і нахилом вежі Пізи.
Як ми створюємо сценарій для цього?
Отримання даних для атаки
Зображення атак, такі як приклад “квітки” вище, генеруються шляхом доступу до наборів даних зображень, які навчали комп’ютерні моделі. Вам не потрібно “привілейований” доступ до навчальних даних (або архітектур моделей), оскільки найбільш популярні набори даних (і багато навчених моделей) широко доступні в потужній і постійно оновлюваній торент-сцені.
Наприклад, величезний набір даних ImageNet доступний для торенту у всіх своїх ітераціях, обходячи звичайні обмеження, і роблячи доступними важливі додаткові елементи, такі як валидційні набори.

Джерело: https://academictorrents.com
Якщо у вас є дані, ви можете (як спостерігають дослідники Аделаїди) ефективно “обернути” будь-який популярний набір даних, такий як CityScapes, або CIFAR.
У випадку з PubFig, набором даних, який дозволив “квітку Обами” у попередньому прикладі, Колумбійський університет звернув увагу на зростаючу тенденцію щодо проблем авторських прав при перерозподілі наборів даних зображень, давши дослідникам інструкції щодо відтворення набору даних через кураторські посилання, а не роблячи компіляцію безпосередньо доступною, спостерігаючи ‘Це здається тим, як інші великі веб-орієнтовані бази даних еволюціонують’.
У більшості випадків це не потрібно: Kaggle оцінює, що десять найпопулярніших наборів даних зображень у комп’ютерному баченні є: CIFAR-10 і CIFAR-100 (обидва безпосередньо завантажуються); CALTECH-101 і 256 (обидва доступні і зараз доступні як торенти); MNIST (офіційно доступний, також на торентах); ImageNet (див. вище); Pascal VOC (доступний, також на торентах); MS COCO (доступний, і на торентах); Sports-1M (доступний); і YouTube-8M (доступний).
Ця доступність також представляє ширший діапазон доступних наборів даних зображень комп’ютерного бачення, оскільки невідомість означає смерть у культурі відкритого джерела “опублікуйте або загиньте”.
У будь-якому випадку, нестача керованих нових наборів даних, висока вартість розробки наборів зображень, залежність від “старих улюблених” і тенденція до простого адаптування старих наборів даних ще більше загострюють проблему, викладену в новій статті Аделаїди.
Типові критики методів атак на зображення
Найчастіша і постійна критика інженерів-машинобудівників щодо ефективності останньої техніки атаки на зображення полягає в тому, що атака специфічна для певного набору даних, певної моделі або обох; що вона не “загальновживана” для інших систем; і, як наслідок, представляє лише тривіальну загрозу.
Друга найчастіша скарга полягає в тому, що атака на зображення ‘біла скринька’, тобто вам потрібно прямий доступ до навчального середовища або даних. Це дійсно малоймовірний сценарій у більшості випадків – наприклад, якщо ви хочете використати навчальний процес для систем розпізнавання облич Лондонської міської поліції, вам потрібно буде взломатися в NEC, або з консолі, або з сокирою.
Довгострокове “ДНК” популярних наборів даних комп’ютерного бачення
Відносно першої критики, ми повинні розглянути не тільки те, що лише кілька наборів даних комп’ютерного бачення домінують в галузі рік за роком (тобто ImageNet для різних типів об’єктів, CityScapes для сцен руху, і FFHQ для розпізнавання облич); але також те, що вони є “платформо-агностичними” і високотрансферабельними як прості анотовані дані зображень.
Відповідно до їхніх можливостей, будь-яка архітектура навчання комп’ютерного бачення знайде декілька ознак об’єктів і класів у наборі даних ImageNet. Деякі архітектури можуть знайти більше ознак, ніж інші, або зробити більш корисні зв’язки, ніж інші, але всі повинні знайти хоча б вищі рівні ознак:

Дані ImageNet з мінімально життєздатною кількістю правильних ідентифікацій – ‘вищі рівні’ ознак.
Це “вищі рівні” ознак, які відрізняють і “відбиток” набору даних, і які є надійними “гаками” для довгострокової атаки на зображення, яка може охоплювати різні системи і розвиватися разом з “старим” набором даних.
Більш складна архітектура буде виробляти більш точні і деталізовані ідентифікації, ознаки і класи:

Однак, чим більше атака на зображення залежить від цих нижчих ознак (тобто “Молодий кавказець” замість “Обличчя”), тим менше вона буде ефективною в перехрестних або пізніших архітектурах, які використовують різні версії оригінального набору даних – наприклад, підмножину або фільтровану множину, де багато оригінальних зображень з повного набору даних відсутні:

Атаки на “нульовані”, попередньо навчені моделі
Що стосується випадків, коли ви просто завантажуєте попередньо навчену модель, яка була спочатку навчена на дуже популярному наборі даних, і даєте їй зовсім нові дані?
Модель вже була навчена на (наприклад) ImageNet, і все, що залишилося, це ваги, які могли зайняти тижні або місяці для навчання, і тепер готові допомогти вам ідентифікувати подібні об’єкти до тих, які існували в оригінальних (зараз відсутніх) даних.

З оригінальними даними, видаленими з архітектури навчання, залишається ‘передбачення’ моделі класифікувати об’єкти тим же способом, яким вона спочатку навчилася робити, що фактично спричинить повторне формування багатьох оригінальних ‘підписів’ і знову зробить їх вразливими для тих самих старих методів атаки на зображення.
Ці ваги цінні. Без даних або ваг, у вас фактично порожня архітектура без даних. Вам доведеться навчати її з нуля, із великими витратами часу і обчислювальних ресурсів, як це зробили оригінальні автори (ймовірно, на більш потужному обладнанні і з вищим бюджетом, ніж у вас).
Проблема полягає в тому, що ваги вже досить добре сформовані і стійкі. Хоча вони трохи адаптуються під час навчання, вони будуть поводитися подібно на ваших нових даних, як і на оригінальних даних, виробляючи ознаки, на які система атаки на зображення може знову звернутися.
У довгостроковій перспективі це також зберігає “ДНК” наборів даних комп’ютерного бачення, які дванадцять або більше років, і могли пройти помітну еволюцію від відкритих джерел через комерційні розгортання – навіть якщо оригінальні навчальні дані були повністю видалені на початку проекту. Деякі з цих комерційних розгортань можуть не відбутися ще протягом років.
Немає потреби в “Білій скриньці”
Відносно другої поширеної критики систем атаки на зображення, автори нової статті виявили, що їхня здатність обманювати системи розпізнавання зображень спеціально створеними зображеннями квіток є високотрансферабельною через кілька архітектур.
Хоча вони спостерігають, що їхній метод “Універсальні натуралістичні патчі” (TnT) є першим, який використовує визнавані зображення (замість випадкового шуму) для обману систем розпізнавання зображень, автори також заявляють:
‘[TnTs] ефективні проти кількох сучасних класифікаторів, починаючи від широко використовуваного WideResNet50 у великій задачі візуального розпізнавання ImageNet до моделей VGG-face у задачі розпізнавання облич PubFig у обох цільових і нецільових атаках.
‘TnTs можуть володіти: i) природністю, досяжною [з використанням] спригів, використовуваних у методах атаки Трояна; і ii) узагальненістю і трансферабельністю адверсарних прикладів до інших мереж.
‘Це викликає питання безпеки щодо вже розгорнутих DNN, а також майбутніх розгортань DNN, де атакувальники можуть використовувати непомітні природні патчі, щоб обманути системи нейронних мереж без порушення моделі і ризику виявлення.’
Автори пропонують, що традиційні контрзаходи, такі як погіршення точності мережі, могли б теоретично забезпечити деякий захист проти патчів TnT, але що ‘TnTs все одно можуть успішно обійти цей захист з найбільшими захисними системами, які досягають 0% стійкості’.
Можливі інші рішення включають федеративне навчання, де походження внесених зображень захищено, і нові підходи, які могли б безпосередньо “зашифрувати” дані під час навчання, такі як один недавно запропонований Нанькінським університетом аеронавтики і астронавтики.
Хоча в цих випадках було б важливо навчатися на дійсно нових даних зображень – зараз зображення і пов’язані з ними анотації в невеликій групі найбільш популярних наборів даних комп’ютерного бачення настільки глибоко вкоренілися в циклах розробки по всьому світу, що нагадують програмне забезпечення, а не дані; програмне забезпечення, яке часто не оновлювалося протягом років.
Висновок
Атаки на зображення стають можливими не тільки завдяки відкритим практикам машинного навчання, але також через корпоративну культуру розробки штучного інтелекту, яка мотивована до повторного використання добре встановлених наборів даних комп’ютерного бачення з кількох причин: вони вже довели свою ефективність; вони значно дешевші, ніж “починати з нуля”; і вони підтримуються і оновлюються передовими розумами і організаціями в академії і промисловості, на рівні фінансування і персоналу, який би був важко повторити для однієї компанії.
Крім того, у багатьох випадках, коли дані не оригінальні (наприклад, CityScapes), зображення були зібрані до недавніх суперечок щодо питань конфіденційності і збору даних, залишаючи ці старіші набори даних у певному роді правового лімбу, який може виглядати як “безпечна гавань” з точки зору компанії.
Атаки TnT! Універсальні натуралістичні патчі проти глибоких нейронних мереж написані Бао Гія Дуаном, Міньхуєм Сюе, Ехсаном Аббаснеджадом, Дамітом С. Ранасінгхе з Університету Аделаїди, разом з Шікінґом Ма з кафедри комп’ютерних наук Рутгерського університету.
Оновлено 1 грудня 2021 року, 7:06 ранку GMT+2 – виправлено друкарську помилку.












