Yapay Zekâ 101
Aşırı Uyum Nedir?
Aşırı Uyum Nedir?
Bir sinir ağı eğittiğinizde, aşırı uyuma karşı dikkatli olmalısınız. Aşırı uyum makine öğrenimi ve istatistiklerde bir modelin eğitim veri kümesinin kalıplarını çok iyi öğrenmesi ve eğitim veri kümesini mükemmel bir şekilde açıklaması ancak diğer veri kümelerine öngörücü gücünü genelleştirememesi vấnudur.
Bunu başka bir şekilde söylemek gerekirse, aşırı uyuma sahip bir model genellikle eğitim veri kümesi üzerinde çok yüksek doğruluk gösterir ancak gelecekte model aracılığıyla toplanan ve çalıştırılan veriler üzerinde düşük doğruluk gösterir. Bu, aşırı uyuma hızlı bir tanımdır, ancak aşırı uyuma kavramını daha ayrıntılı olarak inceleyelim. Aşırı uyuma nasıl oluştuğunu ve nasıl önlenebileceğini görelim.
“Uyum” ve Aşırı Uyum Anlamak
Aşırı uyumu tartışırken, “uyum” ve aşırı uyuma genel olarak bakmak faydalıdır. Bir modeli eğittiğimizde, bir çerçeve geliştirmeye çalışıyoruz ve bu, bir veri kümesindeki öğelerin doğasını veya sınıfını, bu öğeleri tanımlayan özelliklere dayanarak tahmin edebiliyor. Bir model, bir veri kümesindeki bir kalıbı açıklamalı ve bu kalıba dayanarak gelecekteki veri noktalarının sınıflarını tahmin edebilmelidir. Model, eğitim kümesinin özellikleri arasındaki ilişkiyi ne kadar iyi açıklarsa, modelimiz o kadar “uygun” olur.

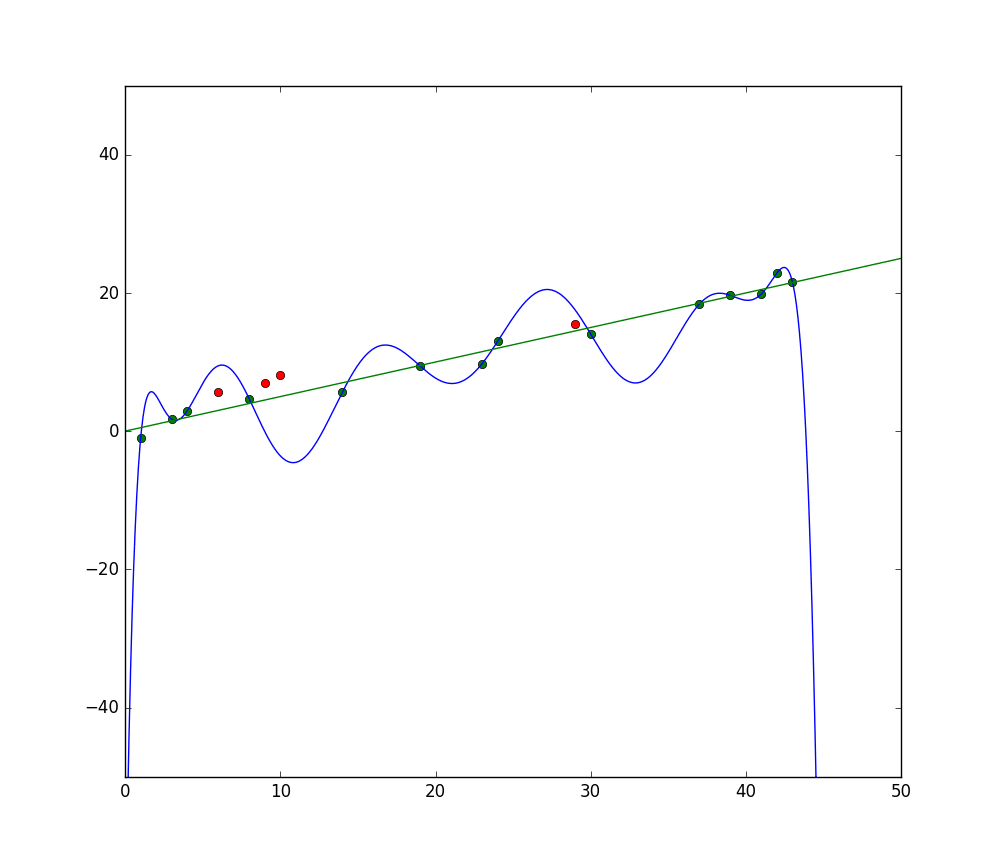
Mavi çizgi, bir modelin aşırı uyumsuzluğunu temsil ederken, yeşil çizgi daha iyi bir uyum modelini temsil etmektedir. Foto: Pep Roca via Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Eğitim verilerini ve因此 fails to accurately classify future data examples is underfitting the training data. Eğer bir underfitting modelinin predicted relationship grafikleseydik, predictions would veer off the mark. Eğer eğitim kümesinin gerçek değerlerini etiketleyerek bir grafik çizseydik, aşırı underfitting bir model çoğu veri noktasını kaçırır. Daha iyi bir uyum modeli, veri noktalarının merkezinden geçen bir yol izler ve bireysel veri noktaları öngörülen değerlerden sadece biraz farklı olur.
Aşırı underfitting, genellikle yeterli veri olmaması veya doğrusal olmayan verilerle doğrusal bir model tasarlamaya çalışmak sonucu oluşabilir. Daha fazla eğitim verisi veya daha fazla özellik genellikle underfittingi azaltabilir.
Peki neden eğitim veri kümesinin her noktasını mükemmel bir şekilde açıklayan bir model yaratamayız? Kesinlikle mükemmel doğruluk isteniyorsa? Eğitim veri kümesinin kalıplarını çok iyi öğrenen bir model yaratmak, aşırı uyuma neden olur. Eğitim veri kümesi ve modelin çalıştırıldığı diğer, gelecekteki veri kümeleri tam olarak aynı olmayacaktır. Birçok yönden benzer olacaklar ancak önemli yönlerden farklı olacaklar. Bu nedenle, eğitim veri kümesini mükemmel bir şekilde açıklayan bir model tasarlamak, diğer veri kümelerine iyi genellemeyen bir özellik arasındaki ilişki hakkında bir teori ile sonuçlanır.
Aşırı Uyum Anlamak
Aşırı uyum, bir modelin eğitim veri kümesinin detaylarını çok iyi öğrenmesi ve dışarıdaki veriler üzerinde tahminlerde bulunma konusunda sıkıntı yaşaması vấnudur. Bu, modelin yalnızca veri kümesinin özelliklerini öğrenmekle kalmayıp, aynı zamanda veri kümesindeki rastgele dalgalanmaları veya gürültüyü de öğrenmesi ve bu rastgele/önemsiz olaylara önem vermesi sonucu oluşabilir.
Aşırı uyum, özellikle doğrusal olmayan modeller kullanıldığında daha olasıdır, çünkü bunlar veri özelliklerini öğrenirken daha esnektir. Parametrik olmayan makine öğrenimi algoritmaları genellikle modelin veri duyarlılığını azaltmak ve aşırı uyumu azaltmak için uygulanabilecek çeşitli parametreler ve teknikler içerir. Örneğin, karar ağacı modelleri aşırı uyuma karşı çok duyarlıdır, ancak bir teknik called pruning, modelin öğrendiği bazı detayları rastgele olarak kaldırarak aşırı uyumu azaltabilir.
Eğer modelin outside veri kümesi üzerindeki tahminlerini X ve Y eksenlerinde grafikleseydik, modelin tüm veri noktalarını açıklamaya çalıştığı için, öngörülerinin zigzag bir şekilde ilerlediğini görürdük.
Aşırı Uyumun Kontrol Edilmesi
Bir modeli eğittiğimizde, ideal olarak modelin hiçbir hatası olmasın istiyoruz. Modelin performansı, eğitim veri kümesindeki tüm veri noktalarını doğru bir şekilde tahmin etmeye yaklaştıkça, uyum daha da iyi hale gelir. İyi bir uyuma sahip bir model, aşırı uyuma düşmeden eğitim veri kümesinin neredeyse tamamını açıklamalıdır.
Modelin performansı, eğitim zamanı ilerledikçe iyileşir. Modelin hata oranı, eğitim zamanı geçtikçe azalır, ancak belirli bir noktaya kadar azalır. Modelin test kümesindeki performansı yeniden artmaya başladığı nokta, genellikle aşırı uyuma başladığı noktadır. Model için en iyi uyumu elde etmek için, modelin eğitimini, eğitim kümesindeki en düşük kaybın olduğu noktada, hata yeniden artmaya başlamadan önce durdurmak istiyoruz. Optimum durdurma noktası, modelin performansı eğitim zamanı boyunca grafiklenerek ve kaybın en düşük olduğu noktada eğitim durdurularak belirlenebilir. Ancak, bu方法la aşırı uyumu kontrol etmenin bir riski, test verisinin eğitim prosedürüne dahil edilmesi ve test verisinin artık tamamen “değişmemiş” veri olarak kabul edilmemesidir.
Aşırı uyumu azaltmak için birkaç farklı yöntem vardır. Aşırı uyumu azaltmanın bir yöntemi, modelin doğruluğunu tahmin eden bir yeniden örnekleme taktiğini kullanmaktır. Ayrıca, test kümesinin yanı sıra bir doğrulama kümesi kullanabilir ve eğitim doğruluğunu test kümesi yerine doğrulama kümesine karşı grafikleyebilirsiniz. Bu, test veri kümenizin görünmez kalmasını sağlar. Popüler bir yeniden örnekleme yöntemi, K-katlı çapraz doğrulamadır. Bu teknik, modeli eğitim için alt kümelerine ayırmanıza ve ardından modelin bu alt kümeler üzerindeki performansı analiz ederek, modelin outside veri üzerinde nasıl performans göstereceğini tahmin etmenize olanak tanır.
Çapraz doğrulamayı kullanmak, bir modelin görünmeyen veriler üzerindeki doğruluğunu tahmin etmenin en iyi yollarından biridir ve bir doğrulama kümesi ile birleştirildiğinde, aşırı uyum genellikle en aza indirilebilir.








