Yapay Zekâ 101
Bayes Teoremi Nedir?
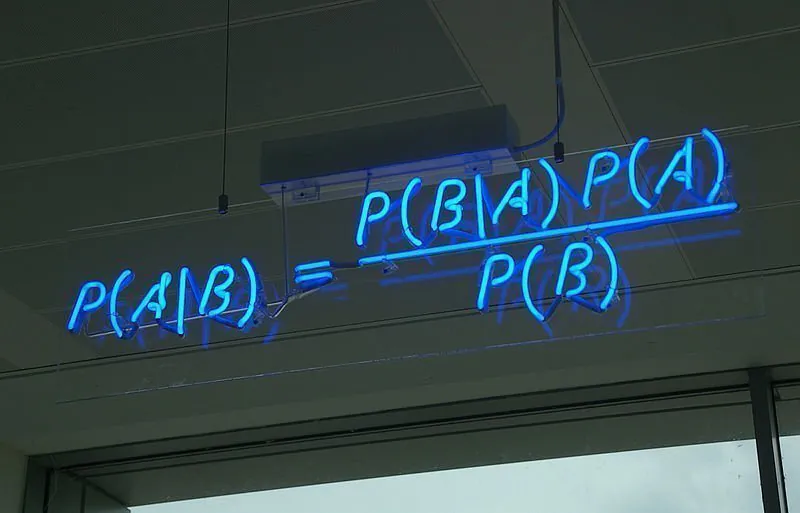
Veri bilimini veya makine öğrenimini öğreniyorsanız, muhtemelen daha önce “Bayes Teoremi” veya “Bayes sınıflandırıcı” terimlerini duymuşsunuzdur. Bu kavramlar, geleneksel, frequentist istatistik perspektifinden olasılık düşünmek alışkanlığınız yoksa biraz karmaşık olabilir. Bu makale, Bayes Teoremi’nin arkasındaki ilkeleri ve makine öğreniminde nasıl kullanıldığını açıklamaya çalışacaktır.
Bayes Teoremi Nedir?
Bayes Teoremi, koşullu olasılığın hesaplanmasına yönelik bir yöntemdir. Koşullu olasılığın geleneksel hesaplanma yöntemi, koşullu olasılık formülünü kullanmaktır; yani bir olayın başka bir olayın meydana gelmesi durumunda meydana gelme olasılığını hesaplamak için, iki olayın aynı anda meydana gelme olasılığını hesaplar ve sonra ikinci olayın meydana gelme olasılığına böler. Ancak, koşullu olasılık Bayes Teoremi kullanılarak slightly farklı bir şekilde de hesaplanabilir.
Bayes teoremi ile koşullu olasılık hesaplanırken, aşağıdaki adımlar kullanılır:
- Koşul B’nin doğru olduğu varsayıldığında, koşul A’nın doğru olma olasılığını belirleyin.
- Olay A’nın doğru olma olasılığını belirleyin.
- İki olasılığı birbirleriyle çarpın.
- Olay B’nin meydana gelme olasılığına bölün.
Bu, Bayes Teoremi formülünün aşağıdaki gibi ifade edilebileceği anlamına gelir:
P(A|B) = P(B|A)*P(A) / P(B)
Koşullu olasılığı bu şekilde hesaplamak, özellikle ters koşullu olasılığın kolayca hesaplanabildiği veya joint olasılığın hesaplanması çok zor olduğu durumlarda oldukça faydalıdır.
Bayes Teoremi Örneği
Bu, Bayes mantığı ve Bayes Teoremi’nin nasıl uygulanacağını gösteren bir örneğe bakarak daha kolay anlaşılabilir. Diyelim ki, birden fazla katılımcının size bir hikaye anlattığı ve sizin bu katılımcıların hangisinin yalan söylediğini belirlemeniz gereken bir oyun oynuyorsunuz. Bayes Teoremi denklemine bu senaryodaki değişkenleri doldurarak başlayalım.
Bu oyunda her bir bireyin yalan söylediğini veya doğruyu söylediğini tahmin etmeye çalışıyoruz, bu nedenle sizin dışındaki üç oyuncu varsa, kategorik değişkenler A1, A2 ve A3 olarak ifade edilebilir. Bir kişinin yalan söylediğine veya doğruyu söylediğine ilişkin kanıtlar, onların davranışlarıdır. Poker oynarken, bir kişinin yalan söylediğine ilişkin belirli “ipuçları” arar ve bu ipuçlarını tahmininizi bilgilendirmek için kullanırsınız. Ya da onlara soru sormaya izin verilirse, onların hikayesinin tutarsız olduğu herhangi bir kanıt olur. Bir kişinin yalan söylediğine ilişkin kanıtları B olarak temsil edebiliriz.
Açık olmak gerekirse, bir kişinin yalan söylediğini veya doğruyu söylediğini tahmin etmeye çalışıyoruz, yani davranışlarının kanıtlarına dayanarak Probability(A yalan söylemesi / doğruyu söylemesi | davranış kanıtları) değerini hesaplamaya çalışıyoruz. Bunu yapmak için, davranışın meydana gelme olasılığını, yani bir kişinin gerçekten yalan söylemesi veya doğruyu söylemesi durumunda davranışının meydana gelme olasılığını hesaplamak istersiniz. Gördüğünüz davranışın en çok hangi koşullar altında mantıklı olacağını belirlemeye çalışıyorsunuz. Üç davranış gözlemliyorsanız, her bir davranış için bu hesaplamayı yaparsınız. Örneğin, P(B1, B2, B3 | A). Bunu, oyun中的 her bir kişi için, yani kendiniz hariç her bir kişi için yaparsınız. Bu, yukarıdaki denklemin bu kısmıdır:
P(B1, B2, B3 | A) * P(A)
Son olarak, sadece bunu B’nin olasılığına bölün.
Eğer bu denklemdeki gerçek olasılıklar hakkında herhangi bir kanıt alırsanız, olasılık modelimizi güncelleyerek yeni kanıtları hesaba katarız. Bu, öncülleri güncellemek olarak bilinir, yani gözlemlenen olayların öncül olasılıkları hakkında varsayımlarımızı güncellersiniz.
Makine Öğrenimi için Bayes Teoremi Uygulamaları
Bayes teoreminin makine öğrenimindeki en yaygın kullanımı, Naive Bayes algoritmasıdır.
Naive Bayes, ikili ve çok sınıflı veri setlerinin sınıflandırılması için kullanılır. Naive Bayes, tanıkların kanıtlarına/özniteliklerine – P(B1, B2, B3 | A)中的 B’ler – atanmış değerlerin birbirlerinden bağımsız olduğu varsayımı nedeniyle bu ismi almıştır. Bu özniteliklerin birbirlerini etkilemediği varsayılır, böylece model basitleştirilir ve hesaplamalar mümkün hale gelir, bu özniteliklerin birbirleriyle olan ilişkilerini hesaplamak yerine. Bu basitleştirilmiş modele rağmen, Naive Bayes, sınıflandırma algoritması olarak oldukça iyi performans gösterir, genellikle bu varsayım doğru olmasa da (ki bu genellikle böyle olur).
Naive Bayes sınıflandırıcının Multinomial Naive Bayes, Bernoulli Naive Bayes ve Gaussian Naive Bayes gibi varyantları da yaygın olarak kullanılır.
Multinomial Naive Bayes algoritmaları, bir belgenin içindeki kelimelerin sıklığını yorumlama konusunda etkili olduğu için genellikle belgelerin sınıflandırılması için kullanılır.
Bernoulli Naive Bayes algoritması, Multinomial Naive Bayes’e benzer şekilde çalışır, ancak algoritma tarafından yapılan tahminler boolean değerlerdir. Bu, metin sınıflandırma alanında, bir Bernoulli Naive Bayes algoritması bir metin belgesinde bir kelimenin bulunup bulunmadığına göre parametreleri atanır.
Eğer öngörücülerin/özniteliklerin değerleri kesikli değil, sürekli ise, Gaussian Naive Bayes kullanılabilir. Sürekli özniteliklerin değerlerinin bir Gaussian dağılımından örneklenmiş olduğu varsayılır.












