
ปัญญาประดิษฐ์
มุ่งสู่มนุษย์ AI แบบเรียลไทม์ด้วยการแสดงผลด้วย Lumigraph ระบบประสาท

แม้จะมีกระแสความสนใจใน Neural Radiance Fields (เนอาร์เอฟ) ซึ่งเป็นเทคโนโลยีที่สามารถสร้างสภาพแวดล้อมและวัตถุ 3 มิติที่สร้างโดย AI วิธีการใหม่ในการใช้เทคโนโลยีการสังเคราะห์ภาพนี้ยังต้องใช้เวลาฝึกฝนอย่างมาก และขาดการนำไปใช้งานที่ช่วยให้สามารถใช้งานอินเทอร์เฟซแบบเรียลไทม์ที่ตอบสนองสูงได้
อย่างไรก็ตาม การทำงานร่วมกันระหว่างชื่อที่น่าประทับใจในอุตสาหกรรมและสถาบันการศึกษาทำให้เกิดความท้าทายใหม่นี้ (เรียกโดยทั่วไปว่า Novel View Synthesis หรือ NVS)
การวิจัย กระดาษมีสิทธิ์ เรนเดอร์ลูมิกราฟประสาทอ้างว่ามีการปรับปรุงความล้ำสมัยประมาณสองลำดับความสำคัญ ซึ่งแสดงถึงหลายขั้นตอนในการเรนเดอร์ CG แบบเรียลไทม์ผ่านไปป์ไลน์การเรียนรู้ของเครื่อง

Neural Lumigraph Rendering (ขวา) ให้ความละเอียดที่ดีขึ้นในการผสมวัตถุ และการจัดการการบดเคี้ยวที่ดีขึ้นกว่าวิธีการก่อนหน้านี้ ที่มา: https://www.youtube.com/watch?v=maVF-7×9644
แม้ว่าเครดิตสำหรับบทความนี้จะอ้างอิงเฉพาะมหาวิทยาลัยสแตนฟอร์ดและบริษัทเทคโนโลยีการแสดงผลโฮโลแกรม Raxium (ปัจจุบันดำเนินงานใน โหมดซ่อนตัว) ผู้ร่วมให้ข้อมูลรวมถึงแมชชีนเลิร์นนิงหลัก สถาปนิก ที่ Google ซึ่งเป็นคอมพิวเตอร์ นักวิทยาศาสตร์ ที่ Adobe และ CTO at ไฟล์เรื่องราว (ซึ่งทำให้ พาดหัวข่าว เมื่อเร็ว ๆ นี้ด้วยเวอร์ชัน AI ของ William Shatner)
เกี่ยวกับการประชาสัมพันธ์แบบสายฟ้าแลบล่าสุดของ Shatner StoryFile ดูเหมือนว่าจะใช้ NLR ในกระบวนการใหม่สำหรับการสร้างเอนทิตีแบบโต้ตอบที่สร้างโดย AI ตามลักษณะและเรื่องเล่าของแต่ละคน

StoryFile มองเห็นการใช้เทคโนโลยีนี้ในการจัดแสดงของพิพิธภัณฑ์ เรื่องเล่าเชิงโต้ตอบออนไลน์ การแสดงภาพโฮโลกราฟิก ความจริงเสริม (AR) และเอกสารมรดก และดูเหมือนว่าจะมองหาแอปพลิเคชันใหม่ที่มีศักยภาพของ NLR ในการสัมภาษณ์รับสมัครงานและแอปพลิเคชันหาคู่เสมือนจริง:

การใช้งานที่เสนอจากวิดีโอออนไลน์โดย StoryFile ที่มา: https://www.youtube.com/watch?v=2K9J6q5DqRc
การจับภาพเชิงปริมาตรสำหรับนวนิยายดูอินเทอร์เฟซการสังเคราะห์และวิดีโอ
หลักการของการจับเชิงปริมาตรในเอกสารต่างๆ ที่สะสมอยู่ในเรื่องคือแนวคิดในการถ่ายภาพนิ่งหรือวิดีโอของเรื่อง และใช้แมชชีนเลิร์นนิงเพื่อ 'เติมเต็ม' มุมมองที่ต้นฉบับไม่ครอบคลุม อาร์เรย์ของกล้อง
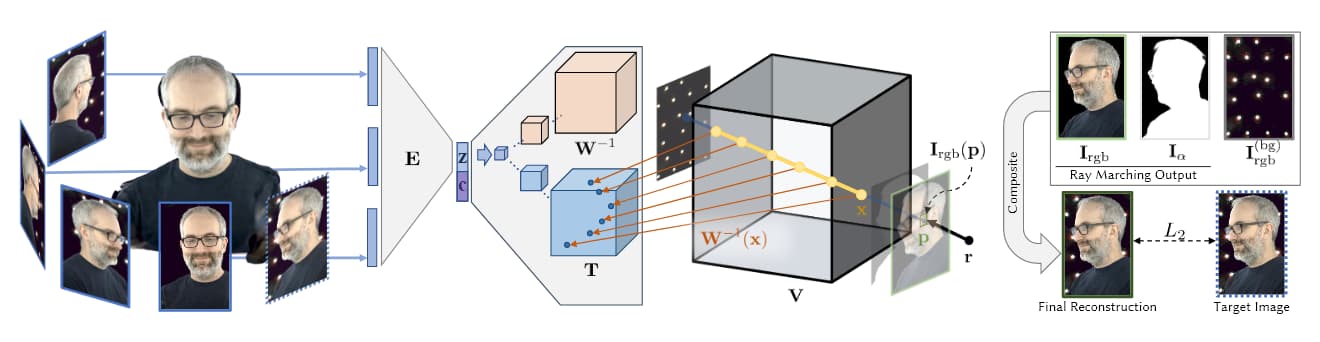
ที่มา: https://research.fb.com/wp-content/uploads/2019/06/Neural-Volumes-Learning-Dynamic-Renderable-Volumes-from-Images.pdf
ในภาพด้านบน ซึ่งนำมาจากการวิจัย AI 2019 AI ของ Facebook (ดูด้านล่าง) เราเห็นสี่ขั้นตอนของการจับภาพเชิงปริมาตร: กล้องหลายตัวรับภาพ/ฟุตเทจ สถาปัตยกรรมตัวเข้ารหัส/ตัวถอดรหัส (หรือสถาปัตยกรรมอื่นๆ) คำนวณและเชื่อมโยงสัมพัทธภาพของมุมมองเข้าด้วยกัน อัลกอริธึมการเดินขบวนด้วยรังสีคำนวณ ว็อกเซล (หรือหน่วยเรขาคณิตเชิงพื้นที่ XYZ อื่นๆ) ของแต่ละจุดในปริภูมิปริมาตร และการฝึกอบรม (ในเอกสารล่าสุด) เกิดขึ้นเพื่อสังเคราะห์เอนทิตีที่สมบูรณ์ที่สามารถจัดการได้แบบเรียลไทม์
ระยะนี้มักเป็นขั้นตอนการฝึกอบรมที่กว้างขวางและใช้ข้อมูลจำนวนมาก ซึ่งจนถึงวันนี้ ทำให้การสังเคราะห์มุมมองใหม่อยู่นอกขอบเขตของการจับภาพแบบเรียลไทม์หรือการตอบสนองสูง
ข้อเท็จจริงที่ว่า Novel View Synthesis สร้างแผนที่ 3 มิติที่สมบูรณ์ของพื้นที่เชิงปริมาตร หมายความว่ามันเป็นเรื่องเล็กน้อยที่จะต่อจุดเหล่านี้เข้าด้วยกันเป็นตาข่ายที่สร้างขึ้นด้วยคอมพิวเตอร์แบบดั้งเดิม จับภาพและประกบมนุษย์ CGI (หรือวัตถุที่มีขอบเขตค่อนข้างอื่นๆ) ได้อย่างมีประสิทธิภาพบน- แมลงวัน
แนวทางที่ใช้ NeRF อาศัยพอยต์คลาวด์และแผนที่เชิงลึกเพื่อสร้างการแก้ไขระหว่างมุมมองที่กระจัดกระจายของอุปกรณ์จับภาพ:

NeRF สามารถสร้างความลึกเชิงปริมาตรผ่านการคำนวณแผนที่ความลึก แทนที่จะสร้างตาข่าย CG ที่มา: https://www.youtube.com/watch?v=JuH79E8rdKc
แม้ว่า NeRF จะเป็น สามารถ ในการคำนวณตาข่าย การใช้งานส่วนใหญ่ไม่ได้ใช้สิ่งนี้เพื่อสร้างฉากเชิงปริมาตร
ในทางตรงกันข้าม Implicit Differentiable Renderer (รูเปียอินโดนีเซีย) เข้าใกล้, การตีพิมพ์ โดยสถาบันวิทยาศาสตร์ Weizmann ในเดือนตุลาคม 2020 ขึ้นอยู่กับการใช้ประโยชน์จากข้อมูลตาข่าย 3 มิติที่สร้างขึ้นโดยอัตโนมัติจากอาร์เรย์การจับภาพ:

ตัวอย่างของการบันทึก IDR กลายเป็นตาข่าย CGI แบบโต้ตอบ ที่มา: https://www.youtube.com/watch?v=C55y7RhJ1fE
ในขณะที่ NeRF ไม่มีความสามารถของ IDR ในการประมาณรูปร่าง แต่ IDR ไม่สามารถเทียบเคียงกับคุณภาพของรูปภาพของ NeRF ได้ และทั้งคู่ต้องการทรัพยากรมากมายในการฝึกอบรมและเปรียบเทียบ (แม้ว่านวัตกรรมล่าสุดใน NeRF นั้น การเริ่มต้น ไปยัง ที่อยู่นี้).

อุปกรณ์กล้องแบบกำหนดเองของ NLR ที่มีกล้อง GoPro HERO16 7 ตัวและกล้อง Back-Bone H6PRO ส่วนกลาง 7 ตัว สำหรับการเรนเดอร์ 'เรียลไทม์' สิ่งเหล่านี้ทำงานที่ขั้นต่ำ 60fps ที่มา: https://arxiv.org/pdf/2103.11571.pdf
แต่จะใช้ Neural Lumigraph Rendering แทน ไซเรน (Sinusoidal Representation Networks) เพื่อรวมจุดแข็งของแต่ละแนวทางไว้ในกรอบการทำงานของตนเอง ซึ่งมีจุดประสงค์เพื่อสร้างเอาต์พุตที่ใช้งานได้โดยตรงในไปป์ไลน์กราฟิกแบบเรียลไทม์ที่ยังหลงเหลืออยู่
ไซเรนถูกนำมาใช้สำหรับ การใช้งานที่คล้ายกัน ในปีที่ผ่านมาและตอนนี้เป็นตัวแทนของก การเรียก API ยอดนิยม สำหรับมือสมัครเล่น Colabs ในชุมชนการสังเคราะห์ภาพ อย่างไรก็ตาม นวัตกรรมของ NLR คือการใช้ SIREN กับการควบคุมภาพหลายมุมมองแบบสองมิติ ซึ่งเป็นปัญหาเนื่องจากขอบเขตที่ SIREN สร้างผลลัพธ์ที่เกินพอดีมากกว่าเอาต์พุตทั่วไป
หลังจากแยกเมช CG ออกจากภาพอาร์เรย์แล้ว เมชจะถูกแรสเตอร์ผ่าน OpenGL และตำแหน่งจุดยอดของเมชจะถูกแมปกับพิกเซลที่เหมาะสม หลังจากนั้นจึงคำนวณการผสมของแมปต่างๆ
ตาข่ายผลลัพธ์มีลักษณะทั่วไปและเป็นตัวแทนมากกว่าของ NeRF (ดูภาพด้านล่าง) ต้องการการคำนวณน้อยกว่า และไม่ใช้รายละเอียดมากเกินไปกับพื้นที่ (เช่น ผิวหน้าที่เรียบเนียน) ที่ไม่สามารถได้รับประโยชน์จากมัน:

ที่มา: https://arxiv.org/pdf/2103.11571.pdf
ในด้านลบ NLR ยังไม่มีความสามารถในการให้แสงไดนามิกหรือ แสงสว่างและเอาต์พุตจะจำกัดเฉพาะแผนที่เงาและการพิจารณาแสงอื่นๆ ที่ได้รับ ณ เวลาที่จับภาพ นักวิจัยตั้งใจที่จะแก้ไขปัญหานี้ในการทำงานในอนาคต
นอกจากนี้ กระดาษยังยอมรับว่ารูปร่างที่สร้างโดย NLR นั้นไม่แม่นยำเท่าแนวทางอื่น เช่น การเลือกมุมมองตามพิกเซลสำหรับสเตอริโอหลายมุมมองที่ไม่มีโครงสร้างหรือการวิจัยของ Weizmann Institute ที่กล่าวถึงก่อนหน้านี้
การเพิ่มขึ้นของการสังเคราะห์ภาพเชิงปริมาตร
แนวคิดในการสร้างเอนทิตี 3 มิติจากชุดภาพถ่ายจำนวนจำกัดที่มีโครงข่ายประสาทเทียมมีมาก่อน NeRF โดยมีเอกสารเกี่ยวกับวิสัยทัศน์ย้อนไปถึงปี 2007 หรือก่อนหน้านั้น ในปี 2019 แผนกวิจัย AI ของ Facebook ได้จัดทำรายงานผลการวิจัยขั้นสุดท้าย Neural Volumes: การเรียนรู้ไดนามิก Renderable Volumes จากรูปภาพซึ่งเป็นครั้งแรกที่เปิดใช้งานอินเทอร์เฟซที่ตอบสนองสำหรับมนุษย์สังเคราะห์ที่สร้างโดยการจับปริมาตรตามการเรียนรู้ของเครื่อง

การวิจัยในปี 2019 ของ Facebook ทำให้สามารถสร้างส่วนต่อประสานผู้ใช้ที่ตอบสนองได้สำหรับบุคคลจำนวนมาก ที่มา: https://research.fb.com/publications/neural-volumes-learning-dynamic-renderable-volumes-from-images/















