ปัญญาประดิษฐ์
AudioSep : แยกสิ่งใดก็ตามที่คุณอธิบาย
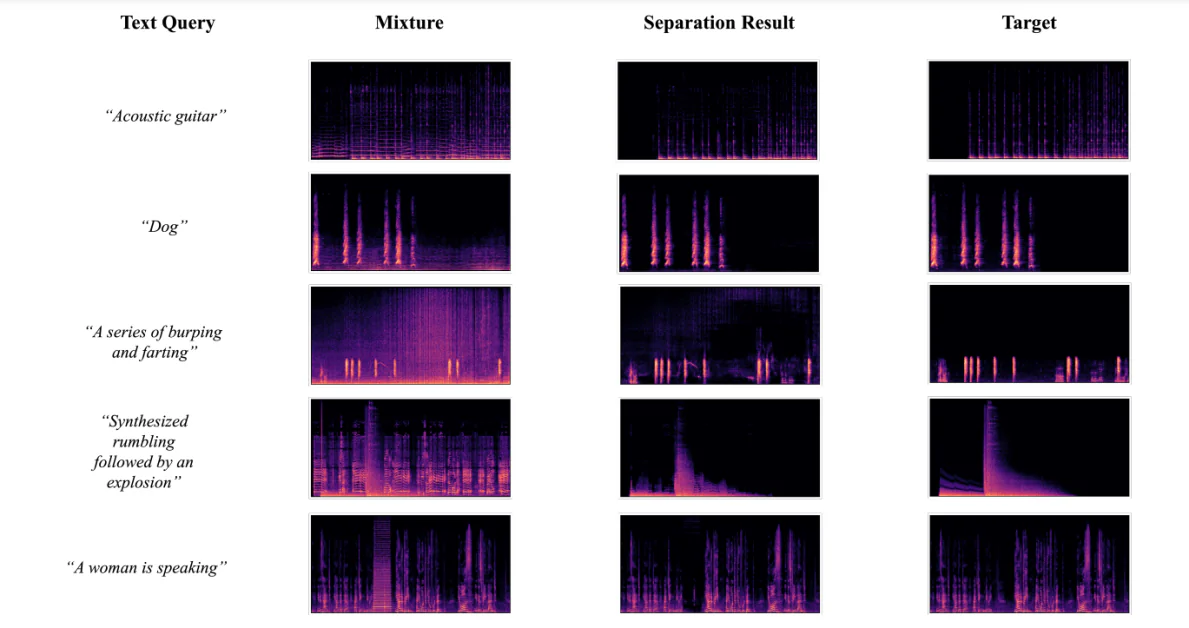
LASS หรือ Language-queried Audio Source Separation เป็นรูปแบบใหม่สำหรับ CASA หรือ Computational Auditory Scene Analysis ที่มีเป้าหมายในการแยกเสียงเป้าหมายออกจากเสียงผสมโดยใช้คำถามภาษาธรรมชาติที่ให้インターフェซที่ยืดหยุ่นและใช้งานได้สำหรับงานและแอปพลิเคชันเสียงดิจิทัล แม้ว่าโครงสร้าง LASS จะมีการปรับปรุงอย่างมากในช่วงไม่กี่ปีที่ผ่านมาในด้านการทำงานที่ต้องการบนแหล่งเสียงเฉพาะ เช่น เครื่องดนตรี แต่ก็ไม่สามารถแยกเสียงเป้าหมายในโดเมนเปิดได้
AudioSep เป็นโมเดลพื้นฐานที่มีเป้าหมายในการแก้ไขข้อจำกัดของโครงสร้าง LASS โดยการทำให้สามารถแยกเสียงเป้าหมายโดยใช้คำถามภาษาธรรมชาติได้ ผู้พัฒนาโครงสร้าง AudioSep ได้ฝึกอบรมโมเดลอย่างกว้างขวางบนชุดข้อมูลหลายรูปแบบขนาดใหญ่ และได้ประเมินผลการทำงานของโครงสร้างบนงานเสียงหลายอย่าง รวมถึงการแยกเครื่องดนตรี, การแยกเหตุการณ์เสียง และการปรับปรุงเสียงพูด เป็นต้น ผลการทำงานเบื้องต้นของ AudioSep เป็นที่น่าพอใจ เนื่องจากแสดงให้เห็นถึงความสามารถในการเรียนรู้แบบ zero-shot ที่น่าประทับใจ และส่งมอบผลการแยกเสียงที่แข็งแกร่ง
ในบทความนี้ เราจะมาดูการทำงานของโครงสร้าง AudioSep อย่างลึกซึ้ง โดยเราจะประเมินโครงสร้างของโมเดล, ชุดข้อมูลที่ใช้ในการฝึกอบรมและประเมินผล, และแนวคิดที่สำคัญที่เกี่ยวข้องกับการทำงานของโมเดล AudioSep ดังนั้น มาเริ่มต้นด้วยการแนะนำพื้นฐานเกี่ยวกับโครงสร้าง CASA กันก่อน
CASA, USS, QSS, LASS โครงสร้าง : พื้นฐานสำหรับ AudioSep
โครงสร้าง CASA หรือ Computational Auditory Scene Analysis เป็นโครงสร้างที่นักพัฒนใช้ในการออกแบบระบบการฟังของเครื่องที่สามารถรับรู้สภาพแวดล้อมเสียงที่ซับซ้อนได้เหมือนกับวิธีที่มนุษย์รับรู้เสียงโดยใช้ระบบการฟังของตนเอง การแยกเสียง โดยเฉพาะการแยกเสียงเป้าหมาย เป็นพื้นที่การวิจัยที่สำคัญภายในโครงสร้าง CASA และมีเป้าหมายในการแก้ปัญหา “cocktail party problem” หรือการแยกการบันทึกเสียงจริงออกจากแหล่งเสียงอื่น ๆ
การทำงานส่วนใหญ่เกี่ยวกับการแยกเสียงที่ทำในอดีตมุ่งเน้นไปที่การแยกแหล่งเสียงหนึ่งหรือหลายแหล่ง เช่น การแยกเสียงดนตรีหรือเสียงพูด โมเดลใหม่ที่มีชื่อว่า USS หรือ Universal Sound Separation มีเป้าหมายในการแยกเสียงใดๆ ในการบันทึกเสียงจริง แต่เป็นงานที่ท้าทายและจำกัดในการแยกแหล่งเสียงทุกแหล่งออกจากเสียงผสม เนื่องจากมีแหล่งเสียงที่หลากหลายในโลก ซึ่งเป็นสาเหตุหลักที่ทำให้ USS ไม่เหมาะสมสำหรับการใช้งานจริง
ทางเลือกที่เป็นไปได้สำหรับวิธี USS คือ QSS หรือ Query-based Sound Separation ซึ่งมีเป้าหมายในการแยกแหล่งเสียงเป้าหมายออกจากเสียงผสมโดยใช้คำถามเฉพาะ โครงสร้าง QSS ช่วยให้นักพัฒนาและผู้ใช้สามารถแยกแหล่งเสียงที่ต้องการออกจากเสียงผสมตามความต้องการ ซึ่งทำให้ QSS เป็นวิธีที่ใช้ได้จริงสำหรับการใช้งานดิจิทัล เช่น การแก้ไขเนื้อหามัลติมีเดียหรือการแก้ไขเสียง
นอกจากนี้ นักพัฒนายังได้เสนอการขยายโครงสร้าง QSS ซึ่งเป็น LASS หรือ Language-queried Audio Source Separation ซึ่งมีเป้าหมายในการแยกแหล่งเสียงใดๆ ออกจากเสียงผสมโดยใช้คำอธิบายภาษาธรรมชาติของแหล่งเสียงเป้าหมาย โครงสร้าง LASS ช่วยให้ผู้ใช้สามารถแยกแหล่งเสียงเป้าหมายโดยใช้คำถามภาษาธรรมชาติได้ ซึ่งอาจกลายเป็นเครื่องมือที่มีประสิทธิภาพสำหรับการใช้งานเสียงดิจิทัล
ในตอนแรก โครงสร้าง LASS พึ่งพาการเรียนรู้แบบมีคำสั่งซึ่งโมเดลได้รับการฝึกอบรมบนชุดข้อมูลที่มีคำอธิบายภาษาและเสียงคู่กัน แต่ปัญหาหลักของวิธีนี้คือการขาดชุดข้อมูลที่มีคำอธิบายและป้ายกำกับเสียง-ข้อความ เพื่อลดการขึ้นอยู่ของโครงสร้าง LASS กับข้อมูลที่มีคำอธิบายและป้ายกำกับเสียง-ข้อความ ผู้พัฒนาได้ฝึกอบรมโมเดลโดยใช้วิธีการเรียนรู้แบบหลายรูปแบบ
AudioSep : ส่วนประกอบหลักและโครงสร้าง
โครงสร้างของ AudioSep ประกอบด้วยสองส่วนหลัก: ตัวเข้ารหัสข้อความ และโมเดลการแยกเสียง
ตัวเข้ารหัสข้อความ
AudioSep ใช้ตัวเข้ารหัสข้อความของ CLIP หรือ Contrastive Language Image Pre Training หรือ CLAP หรือ Contrastive Language Audio Pre Training เพื่อแยกข้อความออกจากคำถามภาษาธรรมชาติ
โมเดลการแยกเสียง
AudioSep ใช้โมเดลการแยกเสียงในโดเมนความถี่ ResUNet ซึ่งได้รับเสียงผสมเป็นข้อมูลเข้า
ชุดข้อมูลและมาตรฐาน
AudioSep เป็นโมเดลพื้นฐานที่มีเป้าหมายในการแก้ไขข้อจำกัดของ LASS ที่พึ่งพาชุดข้อมูลที่มีคำอธิบายและป้ายกำกับเสียง-ข้อความ
AudioSet
AudioSet เป็นชุดข้อมูลเสียงขนาดใหญ่ที่มีมากกว่า 2 ล้านคลิปเสียง 10 วินาที
VGGSound
VGGSound เป็นชุดข้อมูลเสียงและวิดีโอขนาดใหญ่ที่มีมากกว่า 200,000 คลิปวิดีโอ 10 วินาที
ผลการฝึกอบรม
ระหว่างการฝึกอบรม AudioSep ผู้พัฒนาใช้วิธีการเพิ่มเสียงและฝึกอบรม AudioSep โดยใช้ฟังก์ชันขาดทุน L1 ระหว่างเสียงที่แท้จริงและเสียงที่คาดการณ์
ผลการประเมิน
ผลการประเมินของ AudioSep บนชุดข้อมูลที่เห็นและไม่เห็นแสดงให้เห็นถึงผลการทำงานที่แข็งแกร่งและความสามารถในการเรียนรู้แบบ zero-shot
สรุป
AudioSep เป็นโมเดลพื้นฐานที่มีเป้าหมายในการเป็นโครงสร้างการแยกเสียงที่ใช้คำอธิบายภาษาธรรมชาติสำหรับการแยกเสียง












