ปัญญาประดิษฐ์
การเพิ่มประสิทธิภาพโมเดลภาษาขนาดใหญ่ด้วยการทำนายโทเค็นหลายตัว

โมเดลภาษาขนาดใหญ่ (LLMs) เช่น GPT, LLaMA และอื่นๆ ได้สร้างความตื่นตะลึงด้วยความสามารถที่น่าประทับใจในการเข้าใจและสร้างข้อความที่เหมือนมนุษย์ อย่างไรก็ตาม尽管ความสามารถที่น่าประทับใจ แต่วิธีการฝึกอบรมมาตรฐานของโมเดลเหล่านี้ที่เรียกว่า “การทำนายโทเค็นต่อไป” มีข้อจำกัดที่ชัดเจน
ในการทำนายโทเค็นต่อไป โมเดลจะถูกฝึกให้ทำนายคำถัดไปในลำดับโดยพิจารณาจากคำก่อนหน้า แม้ว่าวิธีการนี้จะพิสูจน์แล้วว่าประสบความสำเร็จ แต่ก็สามารถนำไปสู่โมเดลที่ต้องดิ้นรนกับการพึ่งพาที่มีระยะยาวและงานที่ซับซ้อน เช่นเดียวกับการไม่ตรงกันระหว่างการฝึกอบรมแบบ “การบังคับของครู” และกระบวนการสร้างแบบ “การสร้างแบบอัตโนมัติ” ระหว่างการอนุมานสามารถส่งผลให้ประสิทธิภาพไม่ดีได้
งานวิจัยล่าสุดโดย Gloeckle et al. (2024) จาก Meta AI ได้แนะนำรูปแบบการฝึกอบรมใหม่ที่เรียกว่า “การทำนายโทเค็นหลายตัว” ที่มีเป้าหมายในการแก้ไขข้อจำกัดเหล่านี้และเพิ่มประสิทธิภาพโมเดลภาษาขนาดใหญ่ ในบทความนี้ เราจะเจาะลึกแนวคิดหลัก รายละเอียดทางเทคนิค และผลกระทบที่อาจเกิดขึ้นของการวิจัยที่เป็นนวัตกรรมนี้
การทำนายโทเค็นตัวเดียว: วิธีการแบบดั้งเดิม
ก่อนที่จะเจาะลึกรายละเอียดของการทำนายโทเค็นหลายตัว มันเป็นเรื่องสำคัญที่จะต้องเข้าใจวิธีการแบบดั้งเดิมที่ได้ใช้มาเป็นปีในการฝึกอบรมโมเดลภาษาขนาดใหญ่ – การทำนายโทเค็นตัวเดียว หรือที่เรียกว่าการทำนายโทเค็นต่อไป
รูปแบบการทำนายโทเค็นต่อไป
ในรูปแบบการทำนายโทเค็นต่อไป โมเดลภาษาจะถูกฝึกให้ทำนายคำถัดไปในลำดับโดยพิจารณาจากคำก่อนหน้า โดย形式แล้ว โมเดลจะถูกมอบหมายให้เพิ่มความน่าจะเป็นของโทเค็นต่อไป xt+1 โดยพิจารณาจากโทเคันก่อนหน้า x1, x2, …, xt ซึ่งทำได้โดยการลดความสูญเสียของเอนโทรปี
L = -Σt log P(xt+1 | x1, x2, …, xt)
วัตถุประสงค์การฝึกอบรมที่เรียบง่ายแต่ทรงพลังนี้เป็นพื้นฐานของโมเดลภาษาขนาดใหญ่ที่ประสบความสำเร็จหลายรุ่น เช่น GPT (Radford et al., 2018), BERT (Devlin et al., 2019) และรุ่นผู้สืบทอด
การบังคับของครูและการสร้างแบบอัตโนมัติ
การทำนายโทเค็นต่อไปพึ่งพาเทคนิคการฝึกอบรมที่เรียกว่า “การบังคับของครู” โดยที่โมเดลจะได้รับคำตอบที่ถูกต้องสำหรับโทเค็นต่อไปในระหว่างการฝึกอบรม ซึ่งช่วยให้โมเดลเรียนรู้จากบริบทและลำดับที่ถูกต้องได้อย่างมีประสิทธิภาพ
อย่างไรก็ตาม ระหว่างการอนุมาน โมเดลจะทำงานในลักษณะการสร้างแบบอัตโนมัติ โดยทำนายโทเค็นตัวเดียวต่อครั้งโดยพิจารณาจากโทเค่ที่สร้างขึ้นก่อนหน้า การไม่ตรงกันระหว่างการฝึกอบรม (การบังคับของครู) และการอนุมาน (การสร้างแบบอัตโนมัติ) สามารถนำไปสู่ความไม่สอดคล้องกันและประสิทธิภาพที่ไม่ดีได้ โดยเฉพาะสำหรับลำดับที่ยาวหรืองานที่ต้องใช้เหตุผลที่ซับซ้อน
ข้อจำกัดของการทำนายโทเค็นต่อไป
แม้ว่าการทำนายโทเค็นต่อไปจะประสบความสำเร็จอย่างน่าประทับใจ แต่ก็มีข้อจำกัดที่ชัดเจน:
- การมุ่งเน้นที่ระยะสั้น: โดยการทำนายโทเค็นตัวเดียว โมเดลอาจต้องดิ้นรนกับการจับข้อพึ่งพาที่มีระยะยาวและโครงสร้างโดยรวมของข้อความ ซึ่งอาจนำไปสู่ความไม่สอดคล้องกันหรือการสร้างข้อความที่ไม่สอดคล้องกัน
- การยึดติดกับรูปแบบท้องถิ่น: โมเดลการทำนายโทเค็นต่อไปสามารถยึดติดกับรูปแบบท้องถิ่นในข้อมูลฝึกอบรม ทำให้การสร้างแบบสำหรับสถานการณ์ที่ไม่เหมือนกันหรืองานที่ต้องใช้เหตุผลที่เป็นนามธรรมเป็นเรื่องที่ท้าทาย
- ความสามารถในการให้เหตุผล: สำหรับงานที่ต้องใช้เหตุผลหลายขั้นตอน การคิดเชิงอัลกอริทึม หรือการดำเนินการเชิงตรรกะที่ซับซ้อน การทำนายโทเค็นต่อไปอาจไม่ให้ความน่าจะเป็นเชิงอุปนัยหรือการแสดงผลที่เพียงพอเพื่อสนับสนุนความสามารถเหล่านี้อย่างมีประสิทธิภาพ
- ความไม่มีประสิทธิภาพของตัวอย่าง: เนื่องจากรูปแบบการทำนายโทเค็นต่อไป โมเดลอาจต้องใช้ตัวอย่างฝึกอบรมที่ใหญ่ขึ้นเพื่อได้รับความรู้และความสามารถในการให้เหตุผลที่จำเป็น ซึ่งนำไปสู่ความไม่มีประสิทธิภาพของตัวอย่าง
ข้อจำกัดเหล่านี้ได้กระตุ้นให้นักวิจัยสำรวจรูปแบบการฝึกอบรมทางเลือก เช่น การทำนายโทเค็นหลายตัว ซึ่งมีเป้าหมายในการแก้ไขข้อบกพร่องบางอย่างและปลดล็อกความสามารถใหม่สำหรับโมเดลภาษาขนาดใหญ่
โดยการเปรียบเทียบการทำนายโทเค็นต่อไปแบบดั้งเดิมกับการทำนายโทเค็นหลายตัว ผู้อ่านสามารถเข้าใจแรงจูงใจและประโยชน์ที่เป็นไปได้ของวิธีการหลังได้ดีขึ้น ซึ่งจะนำไปสู่การสำรวจการวิจัยที่เป็นนวัตกรรมนี้อย่างลึกซึ้งยิ่งขึ้น
อะไรคือการทำนายโทเค็นหลายตัว?
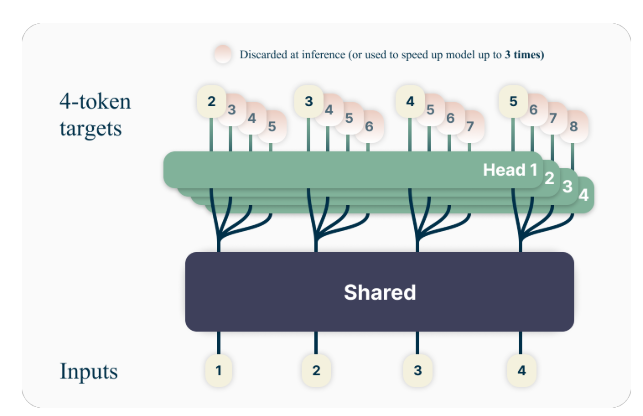
แนวคิดหลักของการทำนายโทเค็นหลายตัวคือการฝึกโมเดลภาษาให้ทำนายโทเค็นต่อไปหลายตัวพร้อมกัน ไม่ใช่แค่โทเค็นตัวเดียวเท่านั้น โดยเฉพาะอย่างยิ่งระหว่างการฝึกอบรม โมเดลจะถูกมอบหมายให้ทำนาย n โทเค็นต่อไปที่แต่ละตำแหน่งในคอร์ปัสฝึกอบรม โดยใช้ n หัวเอาต์พุตอิสระที่ทำงานบนส่วนกลางของโมเดลร่วมกัน
ตัวอย่างเช่น ด้วยการทำนาย 4 โทเค็น โมเดลจะถูกฝึกให้ทำนาย 4 โทเค็นต่อไปพร้อมกัน โดยพิจารณาจากบริบทก่อนหน้า วิธีการนี้กระตุ้นให้โมเดลจับข้อพึ่งพาที่มีระยะยาวและเข้าใจโครงสร้างและความสอดคล้องกันของข้อความโดยรวมได้ดีขึ้น
ตัวอย่างเล็กๆ
เพื่อเข้าใจแนวคิดของการทำนายโทเค็นหลายตัวได้ดีขึ้น ลองพิจารณาตัวอย่างง่ายๆ:
“The quick brown fox jumps over the lazy dog.”
ในแบบการทำนายโทเค็นต่อไปแบบดั้งเดิม โมเดลจะถูกฝึกให้ทำนายคำถัดไปโดยพิจารณาจากบริบทก่อนหน้า ตัวอย่างเช่น โดยพิจารณาจากบริบท “The quick brown fox jumps over the” โมเดลจะถูกมอบหมายให้ทำนายคำถัดไป “lazy”
ด้วยการทำนายโทเค็นหลายตัว โมเดลจะถูกฝึกให้ทำนายหลายคำต่อไปพร้อมกัน ตัวอย่างเช่น ถ้าเราเซต n=4 โมเดลจะถูกฝึกให้ทำนาย 4 คำต่อไปพร้อมกัน โดยพิจารณาจากบริบท “The quick brown fox jumps over the” โมเดลจะถูกมอบหมายให้ทำนายลำดับ “lazy dog ” (รวมพื้นที่หลัง “dog” เพื่อแสดงจุดสิ้นสุดของประโยค)
โดยการฝึกโมเดลให้ทำนายหลายคำต่อไปพร้อมกัน โมเดลจะถูกกระตุ้นให้จับข้อพึ่งพาที่มีระยะยาวและเข้าใจโครงสร้างและความสอดคล้องกันของข้อความโดยรวมได้ดีขึ้น
รายละเอียดทางเทคนิค
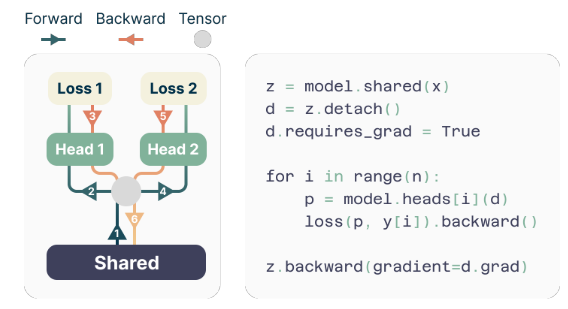
ผู้เขียนเสนอโครงสร้างที่เรียบง่ายแต่มีประสิทธิภาพสำหรับการนำการทำนายโทเค็นหลายตัวไปใช้ โมเดลประกอบด้วยส่วนกลางของทรานส์ฟอร์เมอร์ที่สร้างการแสดงผลแบบแฝงของบริบทอินพุต ตามด้วย n หัวเอาต์พุตทรานส์ฟอร์เมอร์อิสระ (หัวเอาต์พุต) ที่ทำนายโทเค็นต่อไปแต่ละตัว
ระหว่างการฝึกอบรม การไปข้างหน้าและถอยหลังจะถูกจัดทำอย่างรอบคอบเพื่อลดการใช้หน่วยความจำ GPU ส่วนกลางจะคำนวณการแสดงผลแบบแฝง และจากนั้นหัวเอาต์พุตแต่ละตัวจะทำการไปข้างหน้าและถอยหลังทีละตัว โดยสะสมเกรเดียนท์ที่ระดับส่วนกลาง วิธีการนี้หลีกเลี่ยงการสร้างเวกเตอร์โลจิตและเกรเดียนท์ทั้งหมดพร้อมกัน ลดการใช้หน่วยความจำ GPU สูงสุดจาก O(nV + d) เป็น O(V + d) โดยที่ V คือขนาดของพจนานุกรม และ d คือมิติของการแสดงผลแบบแฝง
การนำไปใช้ที่มีประสิทธิภาพด้านหน่วยความจำ
หนึ่งในความท้าทายในการฝึกโมเดลการทำนายโทเค็นหลายตัวคือการลดการใช้หน่วยความจำ GPU ของพวกมัน เนื่องจากขนาดของพจนานุกรม (V) มักจะมากกว่ามิติ (d) ของการแสดงผลแบบแฝง เวกเตอร์โลจิตจึงกลายเป็นปัญหาการใช้หน่วยความจำ GPU
เพื่อแก้ไขความท้าทายนี้ ผู้เขียนเสนอการนำไปใช้ที่มีประสิทธิภาพด้านหน่วยความจำซึ่งปรับลำดับการดำเนินการไปข้างหน้าและถอยหลังอย่างรอบคอบ แทนที่จะสร้างเวกเตอร์โลจิตและเกรเดียนท์ทั้งหมดพร้อมกัน การนำไปใช้นี้คำนวณการไปข้างหน้าและถอยหลังสำหรับหัวเอาต์พุตอิสระแต่ละตัวทีละตัว โดยสะสมเกรเดียนท์ที่ระดับส่วนกลาง
วิธีการนี้หลีกเลี่ยงการเก็บเวกเตอร์โลจิตและเกรเดียนท์ทั้งหมดในหน่วยความจำพร้อมกัน ลดการใช้หน่วยความจำ GPU สูงสุดจาก O(nV + d) เป็น O(V + d) โดยที่ n คือจำนวนโทเค็นต่อไปที่จะทำนาย
ข้อดีของการทำนายโทเค็นหลายตัว
งานวิจัยนำเสนอข้อดีหลายประการของการใช้การทำนายโทเค็นหลายตัวในการฝึกโมเดลภาษาขนาดใหญ่:
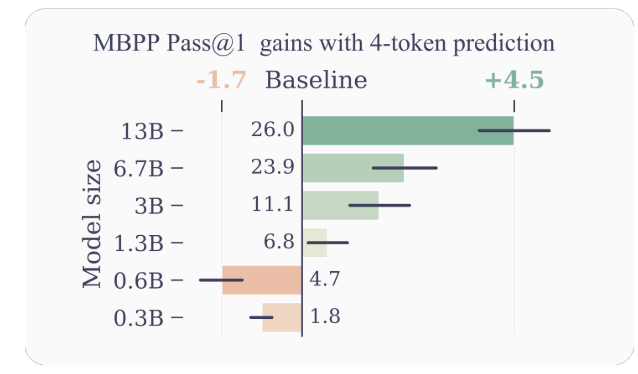
- ประสิทธิภาพตัวอย่างที่ดีขึ้น: โดยการกระตุ้นให้โมเดลทำนายหลายคำต่อไปพร้อมกัน การทำนายโทเค็นหลายตัวช่วยให้โมเดลมีประสิทธิภาพตัวอย่างที่ดีขึ้น ผู้เขียนแสดงให้เห็นถึงการปรับปรุงที่สำคัญในประสิทธิภาพในการทำความเข้าใจและสร้างโค้ด โดยโมเดลที่มีพารามิเตอร์ถึง 13B สามารถแก้ปัญหาได้มากขึ้น 15% ในเฉลี่ย
- การอนุมานที่เร็วขึ้น: หัวเอาต์พุตเพิ่มเติมที่ฝึกอบรมด้วยการทำนายโทเค็นหลายตัวสามารถใช้สำหรับการถอดรหัสแบบ self-speculative ซึ่งเป็นรูปแบบหนึ่งของการถอดรหัสแบบspeculative ที่ช่วยให้สามารถทำนายโทเค็นพร้อมกันได้ ซึ่งนำไปสู่การอนุมานที่เร็วขึ้นถึง 3 เท่าในหลายขนาดแบตช์ แม้กระทั่งสำหรับโมเดลขนาดใหญ่
- การสนับสนุนการพึ่งพาที่มีระยะยาว: การทำนายโทเค็นหลายตัวกระตุ้นให้โมเดลจับข้อพึ่งพาที่มีระยะยาวและรูปแบบในข้อมูล ซึ่งเป็นประโยชน์อย่างยิ่งสำหรับงานที่ต้องเข้าใจและให้เหตุผลในบริบทที่กว้างขึ้น
- การให้เหตุผลเชิงอัลกอริทึม: ผู้เขียนนำเสนอการทดลองในงานสังเคราะห์ที่แสดงให้เห็นถึงความเหนือกว่าของการทำนายโทเค็นหลายตัวในการพัฒนาส่วนหัวการให้เหตุผลและความสามารถในการให้เหตุผลเชิงอัลกอริทึม โดยเฉพาะสำหรับขนาดโมเดลที่เล็ก
- ความสอดคล้องและความสอดคล้อง: โดยการฝึกโมเดลให้ทำนายหลายคำต่อไปพร้อมกัน การทำนายโทเค็นหลายตัวกระตุ้นให้โมเดลพัฒนาการแสดงผลที่สอดคล้องกันและสม่ำเสมอ ซึ่งเป็นประโยชน์อย่างยิ่งสำหรับงานที่ต้องสร้างข้อความยาวๆ ที่สอดคล้องกัน เช่น การเล่าเรื่อง การเขียนเชิงสร้างสรรค์ หรือการสร้างคู่มือสอน
- การสร้างแบบที่ดีขึ้น: การทดลองของผู้เขียนในงานสังเคราะห์แนะนำว่าโมเดลการทำนายโทเค็นหลายตัวแสดงให้เห็นถึงความสามารถในการสร้างแบบที่ดีขึ้น โดยเฉพาะในสถานการณ์ที่ไม่เหมือนกัน ซึ่งอาจเป็นเพราะโมเดลสามารถจับพื้นฐานและความสัมพันธ์ที่กว้างขึ้นได้ดีขึ้น

ตัวอย่างและความเข้าใจ
เพื่อให้เข้าใจว่าทำไมการทำนายโทเค็นหลายตัวจึงทำงานได้ดี ลองพิจารณาตัวอย่างเหล่านี้:
- การสร้างโค้ด: ในบริบทของการสร้างโค้ด การทำนายหลายคำต่อไปพร้อมกันสามารถช่วยให้โมเดลเข้าใจและสร้างโครงสร้างโค้ดที่ซับซ้อนได้ดีขึ้น ตัวอย่างเช่น เมื่อสร้างคำจำกัดความของฟังก์ชัน การทำนายหลายคำต่อไปสามารถช่วยให้โมเดลจับข้อพึ่งพาระหว่างชื่อฟังก์ชัน พารามิเตอร์ และประเภทผลลัพธ์
- การให้เหตุผลภาษาธรรมชาติ: พิจารณาสถานการณ์ที่โมเดลภาษาต้องตอบคำถามที่ต้องใช้เหตุผลหลายขั้นตอนหรือใช้ข้อมูลหลายชิ้น การทำนายหลายคำต่อไปพร้อมกันสามารถช่วยให้โมเดลจับข้อพึ่งพาระหว่างส่วนต่างๆ ของกระบวนการให้เหตุผลได้ดีขึ้น
- การสร้างข้อความยาว: เมื่อสร้างข้อความยาวๆ การทำนายหลายคำต่อไปพร้อมกันสามารถช่วยให้โมเดลพัฒนาการแสดงผลที่สอดคล้องกันและสม่ำเสมอ ซึ่งเป็นประโยชน์อย่างยิ่งสำหรับงานที่ต้องสร้างข้อความที่ยาวและซับซ้อน
ข้อจำกัดและทิศทางในอนาคต
แม้ว่าผลลัพธ์ที่นำเสนอในงานวิจัยจะน่าประทับใจ แต่ก็มีข้อจำกัดและคำถามที่ต้องสำรวจเพิ่มเติม:
- จำนวนโทเค็นต่อไปที่เหมาะสม: งานวิจัยสำรวจค่า n ที่แตกต่างกัน (จำนวนโทเค็นต่อไปที่จะทำนาย) และพบว่า n=4 ทำงานได้ดีสำหรับหลายงาน อย่างไรก็ตาม ค่า n ที่เหมาะสมอาจขึ้นอยู่กับงานเฉพาะ คอร์ปัสฝึกอบรม และขนาดโมเดล การพัฒนาวิธีการที่มีหลักการในการกำหนดค่า n ที่เหมาะสมอาจนำไปสู่การปรับปรุงที่ดีขึ้น
- ขนาดพจนานุกรมและโทเค็น: ผู้เขียนสังเกตว่าขนาดพจนานุกรมและกลยุทธ์โทเค็นที่เหมาะสมสำหรับโมเดลการทำนายโทเค็นหลายตัวอาจแตกต่างจากโมเดลการทำนายโทเค็นต่อไป การสำรวจประเด็นนี้อาจนำไปสู่การปรับปรุงการแลกเปลี่ยนระหว่างความยาวลำดับที่บีบอัดและประสิทธิภาพการคำนวณ
- การเสียสูญเสียการทำนายแบบเสริม: ผู้เขียนชี้ให้เห็นว่างานของพวกเขาอาจกระตุ้นให้เกิดความสนใจในการพัฒนาการเสียสูญเสียการทำนายแบบเสริมใหม่ๆ สำหรับโมเดลภาษาขนาดใหญ่ นอกเหนือจากการทำนายโทเค็นต่อไปแบบมาตรฐาน การสำรวจการเสียสูญเสียแบบเสริมเหล่านี้และความสัมพันธ์กับการทำนายโทเค็นหลายตัวเป็นทิศทางการวิจัยที่น่าสนใจ
- ความเข้าใจเชิงทฤษฎี: แม้ว่างานวิจัยจะให้ความเข้าใจและหลักฐานเชิงประจักษ์สำหรับประสิทธิผลของการทำนายโทเค็นหลายตัว ความเข้าใจเชิงทฤษฎีที่ลึกซึ้งยิ่งขึ้นว่าทำไมและวิธีการที่วิธีการนี้ทำงานได้ดีนั้นจึงมีคุณค่า
สรุป
งานวิจัย “โมเดลภาษาขนาดใหญ่ที่ดีขึ้นและเร็วขึ้นผ่านการทำนายโทเค็นหลายตัว” โดย Gloeckle et al. นำเสนอการฝึกอบรมรูปแบบใหม่ที่มีศักยภาพในการปรับปรุงประสิทธิภาพและความสามารถของโมเดลภาษาขนาดใหญ่ โดยการฝึกโมเดลให้ทำนายหลายคำต่อไปพร้อมกัน การทำนายโทเค็นหลายตัวกระตุ้นให้โมเดลพัฒนาการพึ่งพาที่มีระยะยาว ความสามารถในการให้เหตุผลเชิงอัลกอริทึม และประสิทธิภาพตัวอย่างที่ดีขึ้น
การนำไปใช้ทางเทคนิคที่ผู้เขียนเสนอเป็นเรื่องที่เรียบง่ายแต่มีประสิทธิภาพ ทำให้สามารถนำวิธีการนี้ไปใช้กับการฝึกอบรมโมเดลภาษาขนาดใหญ่ได้ นอกจากนี้ การใช้การถอดรหัสแบบ self-speculative สำหรับการอนุมานที่เร็วขึ้นเป็นข้อได้เปรียบที่สำคัญในทางปฏิบัติ
แม้ว่าจะมีคำถามและพื้นที่ที่ต้องสำรวจเพิ่มเติม การวิจัยนี้เป็นขั้นตอนที่น่าตื่นเต้นในด้านโมเดลภาษาขนาดใหญ่ เมื่อความต้องการโมเดลภาษาที่มีความสามารถและประสิทธิภาพมากขึ้นยังคงเติบโต การทำนายโทเค็นหลายตัวอาจกลายเป็นส่วนสำคัญของระบบ AI ที่ทรงพลังเหล่านี้ในอนาคต












