ปัญญาประดิษฐ์
การพัฒนาการให้เหตุผลของ AI: จากห่วงโซ่ไปสู่กลยุทธ์แบบวนซ้ำและแบบลำดับชั้น
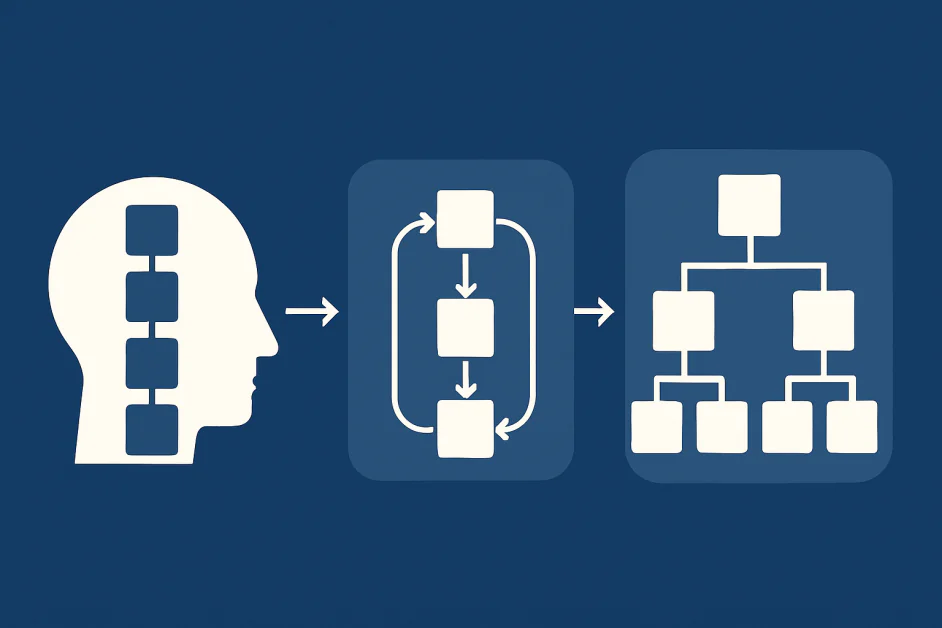
ในช่วงไม่กี่ปีที่ผ่านมา การกระตุ้นห่วงโซ่ความคิด ได้กลายเป็นวิธีการหลักสำหรับการให้เหตุผลในโมเดลภาษาขนาดใหญ่ โดยการกระตุ้นให้โมเดล “คิดออกเสียง” นักวิจัยพบว่าอธิบายขั้นตอนเป็นขั้นตอนสามารถปรับปรุงความแม่นยำในด้านต่างๆ เช่น คณิตศาสตร์และตรรกะ อย่างไรก็ตาม เมื่อ任务มีความซับซ้อนมากขึ้น ข้อจำกัดของ CoT ก็จะชัดเจนขึ้น การพึ่งพา CoT ต่อการคัดเลือกตัวอย่างการให้เหตุผลอย่างรอบคอบทำให้ยากที่จะจัดการกับงานที่ง่ายเกินไปหรือยากเกินกว่าตัวอย่างเหล่านั้น ในขณะที่ CoT นำการคิดที่มีโครงสร้างมาให้กับโมเดลภาษา สาขานี้ต้องการแนวทางใหม่ที่สามารถจัดการกับปัญหาหลายขั้นตอนที่ซับซ้อนและมีความซับซ้อนที่แตกต่างกัน ดังนั้น นักวิจัยจึงกำลังสำรวจกลยุทธ์ใหม่ๆ เช่น การให้เหตุผลแบบวนซ้ำและแบบลำดับชั้น วิธีการเหล่านี้มีเป้าหมายที่จะทำให้การให้เหตุผลลึกซึ้ง มีประสิทธิภาพ และแข็งแกร่งยิ่งขึ้น บทความนี้อธิบายข้อจำกัดของ CoT ตรวจสอบวิวัฒนาการของ CoT และมองหาการใช้งาน ความท้าทาย และทิศทางในอนาคตสำหรับการปรับขนาดการให้เหตุผลของ AI
ข้อจำกัดของห่วงโซ่ความคิด
การให้เหตุผลของ CoT ช่วยให้โมเดลสามารถจัดการกับงานที่ซับซ้อนโดยการแบ่งงานออกเป็นขั้นตอนเล็กๆ ความสามารถนี้ไม่เพียงแต่ ปรับปรุง ผลลัพธ์ของการประเมินในงานคณิตศาสตร์ ปัญหาเชิงตรรกะ และงานโปรแกรมมิ่ง แต่ยังให้ความโปร่งใสบางอย่างโดยการเปิดเผยขั้นตอนกลางๆ ด้วยความเสียใจ อย่างไรก็ตาม CoT ไม่ได้ปราศจากความท้าทาย การวิจัยแสดงให้เห็นว่า CoT ทำงานได้ดีที่สุดในงานที่ต้องการการให้เหตุผลเชิงสัญลักษณ์หรือการคำนวณที่แม่นยำ อย่างไรก็ตาม สำหรับคำถามที่เปิดกว้าง การให้เหตุผลเชิงรู้สึกหรือการเรียกคืนข้อเท็จจริง มักจะเพิ่ม เล็กน้อย หรือแม้กระทั่งลดความแม่นยำ
CoT เป็นลักษณะ เชิงเส้น ในธรรมชาติของมัน โมเดลสร้างลำดับขั้นตอนเดียวที่นำไปสู่คำตอบ สิ่งนี้ทำงานได้ดีสำหรับปัญหาเล็กๆ ที่กำหนดไว้ดี แต่ต้องดิ้นรนเมื่อ任务ต้องการ การสำรวจลึก นอกจากนี้ การให้เหตุผลที่ซับซ้อนมักเกี่ยวข้องกับการแบ่งสาขา การถอยหลัง และการตรวจสอบสมมติฐานอีกครั้ง ห่วงโซ่เชิงเส้นเดียวไม่สามารถจับข้อมูลนี้ได้ หากโมเดลทำข้อผิดพลาดในตอนต้น ขั้นตอนต่อไปทั้งหมดจะล่มสลาย แม้ว่าการให้เหตุผลจะถูกต้อง ผลลัพธ์เชิงเส้นก็ไม่สามารถปรับให้เข้ากับข้อมูลใหม่หรือตรวจสอบสมมติฐานก่อนหน้านี้ได้ การให้เหตุผลในโลกแห่งความเป็นจริงต้องการความยืดหยุ่นที่ CoT ไม่สามารถให้ได้
นักวิจัยยังเน้น ปัญหาการปรับขนาด เมื่อโมเดลเผชิญกับงานที่ยากขึ้น ห่วงโซ就会ยาวขึ้นและเปราะบางขึ้น การตัวอย่างห่วงโซ่หลายๆ อันสามารถช่วยได้ แต่ก็จะไม่มีประสิทธิภาพในไม่ช้า คำถามคือว่าจะย้ายจากการให้เหตุผลแบบเส้นเดียวไปสู่กลยุทธ์ที่มีความยืดหยุ่นมากขึ้นได้อย่างไร
การให้เหตุผลแบบวนซ้ำเป็นขั้นตอนถัดไป
ทิศทางที่มีแนวโน้มหนึ่งคือ การวนซ้ำ แทนที่จะสร้างคำตอบสุดท้ายในหนึ่งครั้ง โมเดลมีส่วนร่วมในรอบการให้เหตุผล การประเมิน และการปรับปรุง สิ่งนี้สะท้อนถึงวิธีที่มนุษย์แก้ปัญหาที่ยากโดยการวางแผนการแก้ปัญหา ตรวจสอบ และปรับปรุงขั้นตอนต่อไป
วิธีการแบบวนซ้ำช่วยให้โมเดลสามารถกู้คืนจากข้อผิดพลาดและสำรวจวิธีแก้ปัญหาแบบอื่น วิธีการเหล่านี้สร้างวงจรการให้ข้อมูลย้อนกลับโดยที่โมเดลวิพากษ์วิจารณ์การให้เหตุผลของตัวเอง หรือที่โมเดลหลายตัววิพากษ์วิจารณ์กันเอง แนวคิดที่มีพลังหนึ่งคือ ความสอดคล้องภายใน แทนที่จะเชื่อใจห่วงโซ่ความคิดเดียว โมเดลจะสุ่มเส้นทางการให้เหตุผลหลายเส้นทางแล้วเลือกคำตอบที่พบบ่อยที่สุด สิ่งนี้เลียนแบบนักเรียนที่พยายามแก้ปัญหาหลายวิธีก่อนที่จะเชื่อใจคำตอบ การวิจัย แสดงให้เห็นว่าการรวมเส้นทางการให้เหตุผลหลายเส้นทางสามารถปรับปรุงความน่าเชื่อถือได้ งานวิจัยล่าสุด ขยายแนวคิดนี้ไปสู่การวนซ้ำแบบมีโครงสร้างโดยที่ผลลัพธ์จะถูกตรวจสอบ ตรวจสอบความถูกต้อง และขยายซ้ำๆ
ความสามารถนี้ยังช่วยให้โมเดลสามารถใช้ เครื่องมือภายนอก ได้ การวนซ้ำทำให้ง่ายต่อการรวมเครื่องมือค้นหา ตัวแก้ปัญหา หรือระบบหน่วยความจำเข้าในวงจร แทนที่จะยึดติดกับคำตอบเดียว โมเดลสามารถค้นหาทรัพยากรภายนอก 重新พิจารณาการให้เหตุผลของมัน และแก้ไขขั้นตอนของมัน การวนซ้ำเปลี่ยนการให้เหตุผลให้เป็นกระบวนการที่มีการเปลี่ยนแปลงอยู่เสมอ แทนที่จะเป็นห่วงโซ่ที่คงที่
แนวทางแบบลำดับชั้นในการจัดการความซับซ้อน
การวนซ้ำเพียงอย่างเดียวไม่เพียงพอเมื่อ任务มีขนาดใหญ่มาก สำหรับปัญหาที่ต้องการระยะเวลานานหรือการวางแผนหลายขั้นตอน การใช้ลำดับชั้นจึงจำเป็น มนุษย์ใช้การให้เหตุผลแบบลำดับชั้นทุกครั้ง เราแบ่งงานออกเป็นปัญหาย่อย ตั้งเป้าหมาย และทำงานผ่านพวกมันในระดับที่มีโครงสร้าง โมเดลต้องการความสามารถเดียวกัน
วิธีการแบบลำดับชั้น ช่วยให้โมเดลสามารถแบ่งงานออกเป็นขั้นตอนเล็กๆ และแก้ไขพวกมันพร้อมๆ กันหรือตามลำดับ การวิจัยเกี่ยวกับ โปรแกรมความคิด และ ต้นไม้ความคิด เน้นย้ำทิศทางนี้ แทนที่จะเป็นห่วงโซ่แบบแบน การให้เหตุผลจะถูกจัดระเบียบเป็นต้นไม้หรือกราฟโดยที่เส้นทางหลายเส้นทางสามารถถูกสำรวจและตัดทอนได้ สิ่งนี้ทำให้สามารถค้นหาและเลือกกลยุทธ์ที่มีแนวโน้มมากที่สุดได้ ในทิศทางนี้ การพัฒนาที่ใหม่คือ Forest-of-Thought ซึ่งปล่อย “ต้นไม้” การให้เหตุผลหลายต้นพร้อมๆ กัน และใช้การร่วมมือและการแก้ไขข้อผิดพลาดระหว่างพวกมัน ต้นไม้แต่ละต้นสามารถสำรวจเส้นทางที่แตกต่างกัน ต้นไม้ที่ดูไม่น่าสนใจจะถูกตัดทอน ในขณะที่กลไกการแก้ไขข้อผิดพลาดช่วยให้โมเดลสามารถระบุและแก้ไขข้อผิดพลาดในแต่ละสาขาได้ โดยการรวมการลงคะแนนจากต้นไม้ทั้งหมด โมเดลตัดสินใจโดยรวม
การลำดับชั้นยังช่วยให้สามารถประสานงานได้ งานขนาดใหญ่สามารถกระจายไปทั่วตัวแทนหลายตัวที่จัดการส่วนต่างๆ ของปัญหา ตัวแทนหนึ่งตัวอาจมุ่งเน้นไปที่การวางแผน อีกตัวหนึ่งในการคำนวณ และอีกตัวหนึ่งในการยืนยันผลลัพธ์สามารถรวมเข้าด้วยกันเป็นคำตอบเดียวที่สอดคล้องกัน การทดลองเบื้องต้นใน การให้เหตุผลแบบหลายตัวแทน แสดงให้เห็นว่าการแบ่งงานดังกล่าวสามารถเอาชนะวิธีการแบบห่วงโซ่เดียวได้
การตรวจสอบและความน่าเชื่อถือ
จุดแข็งอีกประการหนึ่งของกลยุทธ์แบบวนซ้ำและแบบลำดับชั้นคือสามารถตรวจสอบได้อย่างเป็นธรรมชาติ ห่วงโซ่ความคิดเปิดเผยขั้นตอนการให้เหตุผล แต่ไม่ได้รับประกันความถูกต้องของขั้นตอนเหล่านั้น ด้วยการวนซ้ำ โมเดลสามารถตรวจสอบขั้นตอนของตัวเองหรือให้โมเดลอื่นตรวจสอบได้ ด้วยการลำดับชั้น ระดับที่แตกต่างกันสามารถถูกตรวจสอบได้อย่างอิสระ
สิ่งนี้เปิดโอกาสให้ใช้ การประเมินแบบลำดับ ตัวอย่างเช่น โมเดลอาจสร้างคำตอบที่เป็นไปได้ที่ระดับล่าง ในขณะที่ตัวควบคุมระดับสูงเลือกหรือปรับปรุงคำตอบเหล่านั้น หรือตัวตรวจสอบภายนอกสามารถทดสอบผลลัพธ์เทียบกับข้อจำกัดก่อนที่จะยอมรับได้ กลไกเหล่านี้ทำให้การให้เหตุผลน้อย脆弱และน่าเชื่อถือมากขึ้น
การตรวจสอบไม่เพียงแต่เกี่ยวกับความแม่นยำเท่านั้น แต่ยังช่วยให้ การทำความเข้าใจที่ดีขึ้น ด้วยการจัดระเบียบการให้เหตุผลเป็นชั้นๆ หรือการวนซ้ำ นักวิจัยสามารถตรวจสอบจุดที่เกิดความล้มเหลวได้ง่ายขึ้น สิ่งนี้สนับสนุนการแก้ปัญหาและจัดตำแหน่งให้เหมาะสม ทำให้นักพัฒนามีอำนาจควบคุมการให้เหตุผลของโมเดลมากขึ้น
การประยุกต์ใช้
กลยุทธ์การให้เหตุผลที่ซับซ้อนกำลังถูกนำไปใช้ในหลายสาขา ในด้านวิทยาศาสตร์ ช่วยให้สามารถแก้ปัญหาได้ในคณิตศาสตร์ที่ซับซ้อนและแม้แต่ช่วยในการสร้างข้อเสนอการวิจัย ในด้านการเขียนโปรแกรม โมเดลสามารถทำงานได้ดีในการเขียนโค้ดที่มีการแข่งขัน การแก้ปัญหา และการสร้างซอฟต์แวร์แบบเต็มรูปแบบ
สาขากฎหมายและธุรกิจได้รับประโยชน์จากการวิเคราะห์สัญญาที่ซับซ้อนและการวางแผนเชิงกลยุทธ์ ระบบ AI ที่มีตัวแทนสามารถรวมการให้เหตุผลเข้ากับการใช้เครื่องมือ โดยจัดการการดำเนินการที่มีขั้นตอนหลายขั้นตอนผ่าน API ฐานข้อมูล และเว็บ ในด้านการศึกษา ระบบการให้คำปรึกษาสามารถอธิบายแนวคิดทีละขั้นตอนและให้คำแนะนำส่วนบุคคล
ความท้าทายและคำถามที่เปิด
尽管วิธีการแบบวนซ้ำและแบบลำดับชั้นมีแนวโน้ม แต่ยังมีความท้าทายที่ต้องเผชิญอยู่ อันหนึ่งคือประสิทธิภาพ การวนซ้ำและการค้นหาแบบต้นไม้สามารถมีค่าใช้จ่ายในการคำนวณสูง การสร้างสมดุลระหว่างความครอบคลุมและความเร็วเป็นปัญหาที่เปิด
ความท้าทายอีกประการหนึ่งคือการควบคุม การรับรองว่าโมเดลจะปฏิบัติตามกลยุทธ์ที่มีประโยชน์แทนที่จะหลุดเข้าสู่วงจรที่ไม่มีประสิทธิภาพนั้นยาก นักวิจัยกำลัง สำรวจ วิธีการชี้นำการให้เหตุผลด้วยการหาคำแนะนำ อัลกอริทึมการวางแผน หรือตัวควบคุมที่ได้รับการเรียนรู้ แต่สาขานี้ยังคงยัง
การประเมินยังเป็น คำถามที่เปิด แพลตฟอร์มการประเมินความแม่นยำแบบดั้งเดิมจับผลลัพธ์เท่านั้น ไม่ใช่คุณภาพของกระบวนการให้เหตุผล แพลตฟอร์มการประเมินใหม่จำเป็นต้องวัดความแข็งแกร่ง ความสามารถในการปรับตัว และความโปร่งใสของกลยุทธ์การให้เหตุผล
สุดท้าย มีความกังวลเกี่ยวกับ การปรับให้เหมาะสม การให้เหตุผลแบบวนซ้ำและแบบลำดับชั้นอาจเพิ่มทั้งจุดแข็งและจุดอ่อนของโมเดล ในขณะที่สามารถทำให้การให้เหตุผลน่าเชื่อถือมากขึ้น แต่ก็ยากที่จะคาดเดาว่าโมเดลจะพฤติกรรมอย่างไรในสถานการณ์ที่เปิดกว้าง การออกแบบและกำกับดูแลอย่างรอบคอบจำเป็นต้องหลีกเลี่ยงความเสี่ยงใหม่ๆ
สรุป
ห่วงโซ่ความคิดเปิดประตูสู่การให้เหตุผลที่มีโครงสร้างใน AI แต่ข้อจำกัดเชิงเส้นของมันชัดเจน อนาคตอยู่ที่กลยุทธ์แบบวนซ้ำและแบบลำดับชั้นที่ทำให้การให้เหตุผลมีความยืดหยุ่น ตรวจสอบได้ และปรับขนาดได้มากขึ้น โดยใช้การวนซ้ำและการแก้ปัญหาแบบชั้นๆ AI สามารถย้ายจากห่วงโซ่ที่เปราะบางไปสู่ระบบการให้เหตุผลที่มีพลังและสามารถจัดการกับความซับซ้อนที่แท้จริงของโลกได้












