
จริยธรรม
แนวทางปฏิบัติของ AI ในปัจจุบันสามารถเปิดใช้งาน Trolls ลิขสิทธิ์รุ่นใหม่ได้

ความร่วมมือด้านการวิจัยครั้งใหม่ระหว่าง Huawei และสถาบันการศึกษาชี้ให้เห็นว่าการวิจัยในปัจจุบันที่สำคัญที่สุดจำนวนมากในด้านปัญญาประดิษฐ์และการเรียนรู้ของเครื่องจักรอาจต้องเผชิญกับการดำเนินคดีทันทีที่มีความโดดเด่นในเชิงพาณิชย์ เนื่องจากชุดข้อมูลที่ทำให้ความก้าวหน้าเป็นไปได้นั้นถูกแจกจ่ายอย่างไม่ถูกต้อง ใบอนุญาตที่ไม่เคารพข้อกำหนดดั้งเดิมของโดเมนสาธารณะที่ได้รับข้อมูล
ผลที่ได้คือผลลัพธ์ที่เป็นไปได้เกือบสองประการที่เกือบจะหลีกเลี่ยงไม่ได้: อัลกอริทึม AI ที่ประสบความสำเร็จในเชิงพาณิชย์ซึ่งเป็นที่รู้จักว่าใช้ชุดข้อมูลดังกล่าวจะกลายเป็นเป้าหมายในอนาคตของพวกฉวยโอกาสสิทธิบัตรซึ่งไม่เคารพลิขสิทธิ์เมื่อข้อมูลของพวกเขาถูกคัดลอก; และองค์กรและบุคคลจะสามารถใช้ช่องโหว่ทางกฎหมายเดียวกันนี้เพื่อประท้วงการปรับใช้หรือการแพร่กระจายของเทคโนโลยีแมชชีนเลิร์นนิงที่พวกเขาเห็นว่าไม่เหมาะสม
พื้นที่ กระดาษ มีบรรดาศักดิ์ ฉันสามารถใช้ชุดข้อมูลสาธารณะนี้เพื่อสร้างซอฟต์แวร์ AI เชิงพาณิชย์ได้หรือไม่ ส่วนใหญ่จะไม่และเป็นความร่วมมือระหว่าง Huawei Canada และ Huawei China ร่วมกับ York University ในสหราชอาณาจักร และ University of Victoria ในแคนาดา
ชุดข้อมูลโอเพ่นซอร์สห้าในหก (ยอดนิยม) ใช้ไม่ได้ตามกฎหมาย
สำหรับการวิจัย ผู้เขียนได้ขอให้แผนกต่างๆ ของ Huawei เลือกชุดข้อมูลโอเพ่นซอร์สที่ต้องการมากที่สุดที่พวกเขาต้องการใช้ประโยชน์ในโครงการเชิงพาณิชย์ และเลือกชุดข้อมูลที่ได้รับการร้องขอมากที่สุด XNUMX ชุดจากคำตอบ: ซิฟาร์ -10 (ส่วนย่อยของ 80 ล้านภาพขนาดเล็ก ชุดข้อมูลตั้งแต่ การถอดถอน สำหรับ 'คำที่เสื่อมเสีย' และ 'รูปภาพที่ไม่เหมาะสม' แม้ว่าอนุพันธ์ของมันจะมีจำนวนมากขึ้น); อิมเมจเน็ต; ภาพเมือง (ซึ่งประกอบด้วยเนื้อหาต้นฉบับเท่านั้น); FFHQ; วีจีจีเฟซ2และ สพป.
เพื่อวิเคราะห์ว่าชุดข้อมูลที่เลือกนั้นเหมาะสมสำหรับการใช้ทางกฎหมายในโครงการเชิงพาณิชย์หรือไม่ ผู้เขียนได้พัฒนาไปป์ไลน์ใหม่เพื่อติดตามย้อนกลับห่วงโซ่ของใบอนุญาตเท่าที่เป็นไปได้สำหรับแต่ละชุด แม้ว่าพวกเขามักจะต้องใช้การจับภาพเว็บอาร์ไคฟ์เพื่อ ค้นหาใบอนุญาตจากโดเมนที่หมดอายุแล้ว และในบางกรณีต้อง 'เดา' สถานะใบอนุญาตจากข้อมูลที่มีอยู่ที่ใกล้ที่สุด
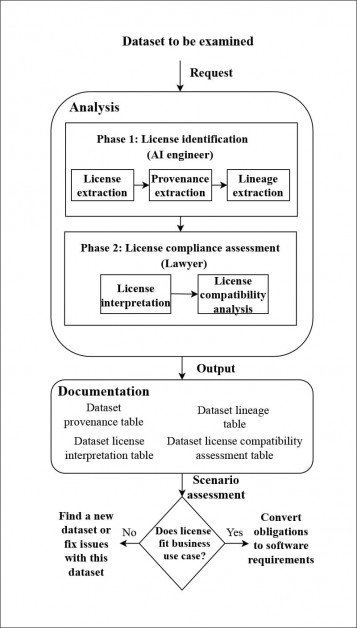
สถาปัตยกรรมสำหรับระบบการติดตามแหล่งที่มาที่พัฒนาโดยผู้เขียน ที่มา: https://arxiv.org/pdf/2111.02374.pdf
ผู้เขียนพบว่าใบอนุญาตสำหรับห้าในหกชุดข้อมูล 'มีความเสี่ยงที่เกี่ยวข้องกับบริบทการใช้งานเชิงพาณิชย์อย่างน้อยหนึ่งรายการ':
'[เรา] สังเกตว่า ยกเว้น MS COCO ไม่มีใบอนุญาตที่ศึกษาใดที่อนุญาตให้ผู้ปฏิบัติงานมีสิทธิ์ในเชิงพาณิชย์สำหรับแบบจำลอง AI ที่ได้รับการฝึกฝนจากข้อมูล หรือแม้แต่ผลลัพธ์ของแบบจำลอง AI ที่ได้รับการฝึกฝน ผลลัพธ์ดังกล่าวยังช่วยป้องกันไม่ให้ผู้ปฏิบัติงานใช้แบบจำลองที่ผ่านการฝึกอบรมล่วงหน้าซึ่งได้รับการฝึกฝนในชุดข้อมูลเหล่านี้ได้อย่างมีประสิทธิภาพ ชุดข้อมูลที่เปิดเผยต่อสาธารณะและโมเดล AI ที่ได้รับการฝึกอบรมล่วงหน้า ได้แก่ ใช้ในเชิงพาณิชย์อย่างแพร่หลาย.' *
ผู้เขียนทราบเพิ่มเติมว่าชุดข้อมูลที่ศึกษา XNUMX ใน XNUMX ชุดอาจส่งผลให้มีการละเมิดใบอนุญาตในผลิตภัณฑ์เชิงพาณิชย์เพิ่มเติมหากมีการแก้ไขชุดข้อมูล เนื่องจากมีเพียง MS-COCO เท่านั้นที่อนุญาต แต่การเพิ่มข้อมูลและชุดข้อมูลย่อยและชุดข้อมูลขนาดใหญ่ที่มีอิทธิพลถือเป็นแนวทางปฏิบัติทั่วไป
ในกรณีของ CIFAR-10 คอมไพเลอร์ต้นฉบับไม่ได้สร้างรูปแบบใบอนุญาตแบบเดิมใดๆ เลย เพียงแต่ต้องการให้โครงการที่ใช้ชุดข้อมูลรวมการอ้างอิงถึงเอกสารต้นฉบับที่มาพร้อมกับการเผยแพร่ชุดข้อมูล ซึ่งเป็นอุปสรรคเพิ่มเติมในการสร้าง สถานะทางกฎหมายของข้อมูล
นอกจากนี้ เฉพาะชุดข้อมูล CityScapes เท่านั้นที่มีเนื้อหาที่สร้างขึ้นโดยผู้สร้างชุดข้อมูลโดยเฉพาะ แทนที่จะเป็น 'การดูแลจัดการ' (คัดลอก) จากแหล่งที่มาของเครือข่าย โดย CIFAR-10 และ ImageNet จะใช้แหล่งข้อมูลหลายแหล่ง ซึ่งแต่ละแหล่งจะต้องได้รับการตรวจสอบ และตรวจสอบย้อนหลังเพื่อสร้างกลไกทางลิขสิทธิ์ประเภทใดก็ได้ (หรือแม้แต่การปฏิเสธความรับผิดชอบที่มีความหมาย)
Way Out ไม่มี
มีสามปัจจัยที่บริษัท AI เชิงพาณิชย์ดูเหมือนจะพึ่งพาเพื่อปกป้องพวกเขาจากการฟ้องร้องเกี่ยวกับผลิตภัณฑ์ที่ใช้เนื้อหาที่มีลิขสิทธิ์จากชุดข้อมูลอย่างอิสระและไม่ได้รับอนุญาต เพื่อฝึกอัลกอริทึม AI ไม่มีสิ่งเหล่านี้ให้ความคุ้มครองระยะยาวที่เชื่อถือได้มากนัก (หรือไม่มีเลย):
1: กฎหมายแห่งชาติ Laissez Faire
แม้ว่ารัฐบาลทั่วโลกจะถูกบังคับให้ผ่อนคลายกฎหมายเกี่ยวกับการขูดข้อมูล เพื่อไม่ให้ต้องถอยกลับในการแข่งขันเพื่อมุ่งสู่ AI ที่มีประสิทธิภาพ (ซึ่งอาศัยข้อมูลในโลกแห่งความจริงในปริมาณมาก ซึ่งการปฏิบัติตามลิขสิทธิ์และการออกใบอนุญาตตามปกติจะไม่สมจริง) เท่านั้น สหรัฐอเมริกาเสนอความคุ้มกันอย่างเต็มที่ในส่วนนี้ภายใต้ หลักคำสอนเรื่องการใช้งานที่เหมาะสม – นโยบายที่ให้สัตยาบันในปี 2015 กับ ข้อสรุป ของ Authors Guild v. Google, Inc. ซึ่งยืนยันว่ายักษ์ใหญ่ด้านการค้นหาสามารถนำเข้าเนื้อหาที่มีลิขสิทธิ์ได้อย่างอิสระสำหรับโครงการ Google หนังสือ โดยไม่ถูกกล่าวหาว่าละเมิดลิขสิทธิ์
หากนโยบายหลักคำสอนเรื่องการใช้งานที่เหมาะสมมีการเปลี่ยนแปลง (เช่น เพื่อตอบสนองต่อกรณีสำคัญอื่นที่เกี่ยวข้องกับองค์กรหรือองค์กรที่มีอำนาจสูงเพียงพอ) ก็อาจได้รับการพิจารณาว่าเป็น priori ระบุในแง่ของการใช้ประโยชน์จากฐานข้อมูลปัจจุบันที่ละเมิดลิขสิทธิ์ ปกป้องการใช้งานในอดีต แต่ไม่ ต่อเนื่อง การใช้และการพัฒนาระบบที่เปิดใช้งานผ่านเนื้อหาที่มีลิขสิทธิ์โดยไม่มีข้อตกลง
สิ่งนี้ทำให้การคุ้มครองในปัจจุบันของหลักคำสอนเรื่องการใช้งานที่เหมาะสมอยู่บนพื้นฐานชั่วคราว และในสถานการณ์นั้นอาจจำเป็นต้องมีอัลกอริทึมการเรียนรู้ของเครื่องที่จัดตั้งขึ้นในเชิงพาณิชย์เพื่อหยุดการดำเนินการในกรณีที่ต้นกำเนิดถูกเปิดใช้งานโดยเนื้อหาที่มีลิขสิทธิ์ แม้แต่ในกรณีที่ ของรุ่น น้ำหนัก ตอนนี้จัดการกับเนื้อหาที่ได้รับอนุญาตเท่านั้น แต่ได้รับการฝึกฝน (และทำให้มีประโยชน์โดย) เนื้อหาที่คัดลอกอย่างผิดกฎหมาย
นอกสหรัฐอเมริกา ดังที่ผู้เขียนได้บันทึกไว้ในรายงานฉบับใหม่ นโยบายมักผ่อนปรนน้อยกว่า สหราชอาณาจักรและแคนาดาชดใช้ค่าเสียหายเฉพาะการใช้ข้อมูลที่มีลิขสิทธิ์เพื่อวัตถุประสงค์ที่ไม่ใช่เชิงพาณิชย์ ในขณะที่กฎหมายเหมืองข้อความและข้อมูลของสหภาพยุโรป (ซึ่งไม่ได้ถูกแทนที่ทั้งหมดโดย ข้อเสนอล่าสุด สำหรับกฎระเบียบ AI ที่เป็นทางการมากขึ้น) ยังไม่รวมการใช้ประโยชน์เชิงพาณิชย์สำหรับระบบ AI ที่ไม่เป็นไปตามข้อกำหนดลิขสิทธิ์ของข้อมูลต้นฉบับ
การจัดการอย่างหลังนี้หมายความว่าองค์กรสามารถบรรลุสิ่งที่ยิ่งใหญ่ด้วยข้อมูลของผู้อื่น สูงสุดแต่ไม่รวมจุดที่จะทำเงินจากข้อมูลนั้น ในขั้นตอนนั้น ผลิตภัณฑ์อาจถูกเปิดเผยอย่างถูกกฎหมาย หรือต้องมีการเตรียมการกับผู้ถือลิขสิทธิ์หลายล้านราย ซึ่งหลายคนไม่สามารถติดตามได้ในขณะนี้เนื่องจากธรรมชาติที่เปลี่ยนแปลงของอินเทอร์เน็ต ซึ่งเป็นโอกาสที่เป็นไปไม่ได้และราคาย่อมเยา
2: คำเตือน Emptor
ในกรณีที่องค์กรที่ละเมิดลิขสิทธิ์หวังที่จะเลี่ยงการตำหนิ เอกสารฉบับใหม่ยังสังเกตว่าใบอนุญาตจำนวนมากสำหรับชุดข้อมูลโอเพ่นซอร์สที่ได้รับความนิยมสูงสุดจะชดใช้ค่าเสียหายโดยอัตโนมัติจากการอ้างสิทธิ์ในการละเมิดลิขสิทธิ์:
'ตัวอย่างเช่น ใบอนุญาตของ ImageNet กำหนดให้ผู้ประกอบวิชาชีพต้องชดใช้ค่าเสียหายแก่ทีม ImageNet จากการเรียกร้องใด ๆ ที่เกิดขึ้นจากการใช้ชุดข้อมูล ชุดข้อมูล FFHQ, VGGFace2 และ MS COCO กำหนดให้แสดงชุดข้อมูลภายใต้ใบอนุญาตเดียวกัน หากแจกจ่ายหรือแก้ไข
สิ่งนี้บังคับให้ผู้ที่ใช้ชุดข้อมูล FOSS ยอมรับความผิดในการใช้เนื้อหาที่มีลิขสิทธิ์ เมื่อเผชิญกับการฟ้องร้องในที่สุด (แม้ว่าจะไม่จำเป็นต้องปกป้องคอมไพเลอร์ดั้งเดิมในกรณีที่สภาพแวดล้อมปัจจุบันของ 'ท่าเรือปลอดภัย' ประกอบอยู่ด้วย)
3: การชดใช้ผ่านความสับสน
ลักษณะการทำงานร่วมกันของชุมชนแมชชีนเลิร์นนิงทำให้ค่อนข้างยากที่จะใช้ลัทธิลึกลับขององค์กรเพื่อบดบังการมีอยู่ของอัลกอริทึมที่ได้รับประโยชน์จากชุดข้อมูลที่ละเมิดลิขสิทธิ์ โครงการเชิงพาณิชย์ระยะยาวมักจะเริ่มต้นในสภาพแวดล้อม FOSS แบบเปิด ซึ่งการใช้ชุดข้อมูลเป็นเรื่องของการบันทึก ที่ GitHub และฟอรัมสาธารณะอื่น ๆ ที่เข้าถึงได้ หรือที่จุดเริ่มต้นของโครงการได้รับการตีพิมพ์ในเอกสารก่อนพิมพ์หรือเอกสารที่ผ่านการตรวจสอบโดยผู้เชี่ยวชาญ
แม้ว่าจะไม่เป็นเช่นนั้นก็ตาม การผกผันของแบบจำลอง is มีความสามารถมากขึ้นเรื่อยๆ ของการเปิดเผยลักษณะทั่วไปของชุดข้อมูล (หรือแม้แต่ เอาท์พุทอย่างชัดเจน แหล่งข้อมูลบางส่วน) ไม่ว่าจะเป็นการพิสูจน์ด้วยตัวมันเอง หรือสงสัยว่ามีการละเมิดมากพอที่จะเปิดใช้คำสั่งศาลในการเข้าถึงประวัติของการพัฒนาอัลกอริทึม และรายละเอียดของชุดข้อมูลที่ใช้ในการพัฒนานั้น
สรุป
บทความนี้แสดงให้เห็นการใช้เนื้อหาที่มีลิขสิทธิ์อย่างวุ่นวายและเป็นการเฉพาะกิจที่ได้รับมาโดยไม่ได้รับอนุญาต และชุดของห่วงโซ่ใบอนุญาตซึ่งตามตรรกะไปไกลถึงแหล่งที่มาของข้อมูลดั้งเดิม จะต้องมีการเจรจากับผู้ถือลิขสิทธิ์หลายพันรายที่มีการนำเสนอผลงาน ภายใต้การอุปถัมภ์ของไซต์ที่มีเงื่อนไขการให้สิทธิ์ใช้งานที่หลากหลาย หลายๆ ชิ้นไม่รวมงานเชิงพาณิชย์ที่เป็นอนุพันธ์
ผู้เขียนสรุป:
'ชุดข้อมูลสาธารณะกำลังถูกใช้อย่างแพร่หลายเพื่อสร้างซอฟต์แวร์ AI เชิงพาณิชย์ เราสามารถทำได้หาก [และ] เฉพาะเมื่อใบอนุญาตที่เกี่ยวข้องกับชุดข้อมูลที่เปิดเผยต่อสาธารณะให้สิทธิ์ในการทำเช่นนั้น อย่างไรก็ตาม การตรวจสอบสิทธิ์และภาระผูกพันที่ให้ไว้ในใบอนุญาตที่เกี่ยวข้องกับชุดข้อมูลที่เปิดเผยต่อสาธารณะนั้นไม่ใช่เรื่องง่าย เพราะบางครั้งใบอนุญาตก็ไม่ชัดเจนหรืออาจใช้ไม่ได้'
อีกหนึ่งผลงานใหม่ชื่อ การสร้างชุดข้อมูลทางกฎหมายซึ่งเผยแพร่เมื่อวันที่ 2 พฤศจิกายนจาก Center for Computational Law ที่ Singapore Management University ยังเน้นย้ำถึงความจำเป็นที่นักวิทยาศาสตร์ข้อมูลต้องตระหนักว่ายุคของการรวบรวมข้อมูลเฉพาะกิจแบบ 'ป่าตะวันตก' กำลังใกล้เข้ามา และสะท้อนถึงคำแนะนำของ Huawei กระดาษเพื่อใช้นิสัยและวิธีการที่เข้มงวดมากขึ้นเพื่อให้แน่ใจว่าการใช้ชุดข้อมูลจะไม่เปิดเผยโครงการไปสู่การแตกสาขาทางกฎหมายเมื่อวัฒนธรรมเปลี่ยนไปตามกาลเวลา และในขณะที่กิจกรรมทางวิชาการระดับโลกในปัจจุบันในภาคการเรียนรู้ของเครื่องแสวงหาผลตอบแทนเชิงพาณิชย์จากการลงทุนหลายปี . ผู้เขียนสังเกต *:
'[The] คลังข้อมูลของกฎหมายที่ส่งผลกระทบต่อชุดข้อมูล ML ถูกตั้งค่าให้เติบโต ท่ามกลางความกังวลว่ากฎหมายปัจจุบันเสนอ ไม่เพียงพอ การป้องกัน. ร่าง ก.ค.ศ [พ.ร.บ.ปัญญาประดิษฐ์ของสหภาพยุโรป]หากและเมื่อผ่านไปแล้ว จะเปลี่ยนแปลงภูมิทัศน์ของ AI และการกำกับดูแลข้อมูลอย่างมีนัยสำคัญ เขตอำนาจศาลอื่นๆ อาจปฏิบัติตามกฎหมายของตนเองตามความเหมาะสม '
* การแปลงการอ้างอิงแบบอินไลน์เป็นไฮเปอร์ลิงก์















