
UA 101
Çfarë është Reduktimi i Dimensionalitetit?
Çfarë është Reduktimi i Dimensionalitetit?
Reduktimi i dimensioneve është një proces që përdoret për të reduktuar dimensionalitetin e një grupi të dhënash, duke marrë shumë veçori dhe duke i përfaqësuar ato si më pak karakteristika. Për shembull, reduktimi i dimensionalitetit mund të përdoret për të reduktuar një grup të dhënash prej njëzet karakteristikash në vetëm disa veçori. Zvogëlimi i dimensioneve përdoret zakonisht në të mësuarit pa mbikëqyrje detyrat për të krijuar automatikisht klasa nga shumë veçori. Për të kuptuar më mirë pse dhe si përdoret reduktimi i dimensionalitetit, do t'i hedhim një vështrim problemeve që lidhen me të dhënat me dimensione të larta dhe metodat më të njohura të reduktimit të dimensionalitetit.
Më shumë dimensione çojnë në mbipërshtatje
Dimensionaliteti i referohet numrit të veçorive/kolonave brenda një grupi të dhënash.
Shpesh supozohet se në mësimin e makinerive më shumë veçori janë më të mira, pasi krijon një model më të saktë. Megjithatë, më shumë veçori nuk përkthehen domosdoshmërisht në një model më të mirë.
Veçoritë e një grupi të dhënash mund të ndryshojnë shumë për sa i përket asaj se sa të dobishme janë ato për modelin, me shumë veçori që kanë pak rëndësi. Përveç kësaj, sa më shumë veçori të përmbajë grupi i të dhënave, aq më shumë mostra nevojiten për të siguruar që kombinimet e ndryshme të veçorive të përfaqësohen mirë brenda të dhënave. Prandaj, numri i mostrave rritet në raport me numrin e veçorive. Më shumë mostra dhe më shumë veçori do të thotë se modeli duhet të jetë më kompleks, dhe ndërsa modelet bëhen më komplekse, ato bëhen më të ndjeshme ndaj përshtatjes së tepërt. Modeli i mëson shumë mirë modelet në të dhënat e trajnimit dhe nuk arrin të përgjithësohet në të dhëna jashtë mostrës.
Reduktimi i dimensionalitetit të një grupi të dhënash ka disa përfitime. Siç u përmend, modelet më të thjeshta janë më pak të prirura ndaj përshtatjes së tepërt, pasi modeli duhet të bëjë më pak supozime në lidhje me atë se si veçoritë lidhen me njëri-tjetrin. Përveç kësaj, më pak dimensione do të thotë që kërkohet më pak fuqi llogaritëse për të trajnuar algoritmet. Në mënyrë të ngjashme, nevojitet më pak hapësirë ruajtëse për një grup të dhënash që ka dimensione më të vogla. Reduktimi i dimensionalitetit të një grupi të dhënash mund t'ju lejojë gjithashtu të përdorni algoritme që janë të papërshtatshme për grupe të dhënash me shumë veçori.
Metodat e zakonshme të reduktimit të dimensioneve
Reduktimi i dimensioneve mund të bëhet nga përzgjedhja e veçorive ose inxhinieria e veçorive. Zgjedhja e veçorive është vendi ku inxhinieri identifikon tiparet më të rëndësishme të grupit të të dhënave, ndërsa inxhinieri tipare është procesi i krijimit të veçorive të reja duke kombinuar ose transformuar veçori të tjera.
Zgjedhja e veçorive dhe inxhinieria mund të bëhet në mënyrë programore ose manuale. Gjatë zgjedhjes manuale dhe inxhinierisë së veçorive, vizualizimi i të dhënave për të zbuluar korrelacionet midis veçorive dhe klasave është tipik. Kryerja e reduktimit të dimensionalitetit në këtë mënyrë mund të jetë mjaft kohë intensive dhe për këtë arsye disa nga mënyrat më të zakonshme të reduktimit të dimensionalitetit përfshijnë përdorimin e algoritmeve të disponueshme në biblioteka si Scikit-learn për Python. Këto algoritme të zakonshme të reduktimit të dimensioneve përfshijnë: Analizën e Komponentit Kryesor (PCA), Zbërthimin e Vlerave Njëjës (SVD) dhe Analizën Diskriminuese Lineare (LDA).
Algoritmet e përdorura në reduktimin e dimensionalitetit për detyrat e mësimit të pambikëqyrur janë zakonisht PCA dhe SVD, ndërsa ato të përdorura për reduktimin e dimensioneve të të mësuarit të mbikëqyrur janë zakonisht LDA dhe PCA. Në rastin e modeleve të mësimit të mbikëqyrur, veçoritë e krijuara rishtazi futen në klasifikuesin e mësimit të makinerive. Kini parasysh se përdorimet e përshkruara këtu janë vetëm raste të përdorimit të përgjithshëm dhe jo kushtet e vetme në të cilat mund të përdoren këto teknika. Algoritmet e reduktimit të dimensioneve të përshkruara më sipër janë thjesht metoda statistikore dhe ato përdoren jashtë modeleve të mësimit të makinerive.
Analiza e Komponentit Kryesor

Foto: Matrica me komponentët kryesorë të identifikuar
Analiza e Komponentit Kryesor (PCA) është një metodë statistikore që analizon karakteristikat/veçoritë e një grupi të dhënash dhe përmbledh tiparet që janë më me ndikim. Tiparet e grupit të të dhënave kombinohen së bashku në paraqitje që ruajnë shumicën e karakteristikave të të dhënave, por shpërndahen në më pak dimensione. Ju mund ta mendoni këtë si "shtrëngim" të të dhënave nga një paraqitje më e lartë e dimensionit në një me vetëm disa dimensione.
Si shembull i një situate ku PCA mund të jetë e dobishme, mendoni për mënyrat e ndryshme që mund të përshkruani verën. Ndërsa është e mundur të përshkruhet verë duke përdorur shumë karakteristika shumë specifike si nivelet e CO2, nivelet e ajrimit, etj., karakteristika të tilla specifike mund të jenë relativisht të padobishme kur përpiqeni të identifikoni një lloj vere specifike. Në vend të kësaj, do të ishte më e kujdesshme të identifikohej lloji bazuar në karakteristika më të përgjithshme si shija, ngjyra dhe mosha. PCA mund të përdoret për të kombinuar veçori më specifike dhe për të krijuar veçori që janë më të përgjithshme, të dobishme dhe më pak të ngjarë të shkaktojnë mbipërshtatje.
PCA kryhet duke përcaktuar se si tiparet hyrëse ndryshojnë nga mesatarja në lidhje me njëra-tjetrën, duke përcaktuar nëse ekziston ndonjë marrëdhënie midis veçorive. Për ta bërë këtë, krijohet një matricë kovariante, duke krijuar një matricë të përbërë nga kovarianca në lidhje me çiftet e mundshme të veçorive të të dhënave. Kjo përdoret për të përcaktuar korrelacionet midis variablave, me një kovariancë negative që tregon një korrelacion të kundërt dhe një korrelacion pozitiv që tregon një korrelacion pozitiv.
Komponentët kryesorë (më me ndikim) të grupit të të dhënave krijohen duke krijuar kombinime lineare të ndryshoreve fillestare, gjë që bëhet me ndihmën e koncepteve të algjebrës lineare të quajtura eigenvalues dhe eigenvectors. Kombinimet krijohen në mënyrë që komponentët kryesorë të jenë të pakorreluar me njëri-tjetrin. Shumica e informacionit të përfshirë në variablat fillestare është i ngjeshur në disa komponentët e parë kryesorë, që do të thotë se janë krijuar veçori të reja (komponentët kryesorë) që përmbajnë informacionin nga grupi i të dhënave origjinale në një hapësirë më të vogël dimensionale.
Zbërthimi i vlerës së njëjës
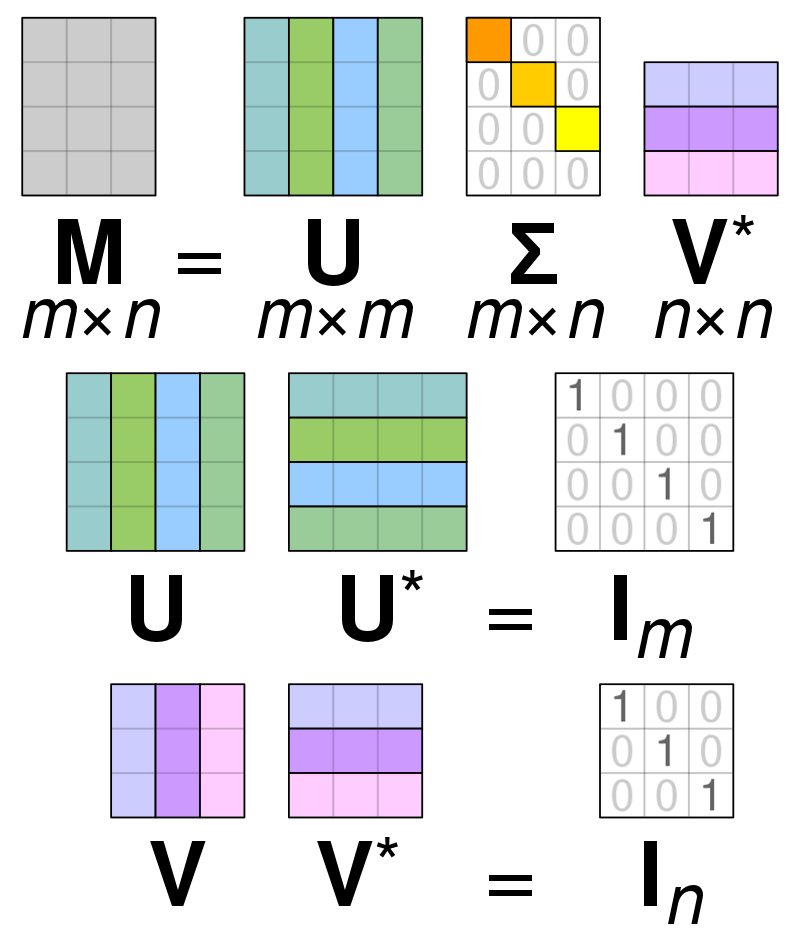
Foto: Nga Cmglee – Vepra e vet, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=67853297
Zbërthimi i vlerës njëjës (SVD) is përdoret për të thjeshtuar vlerat brenda një matrice, duke reduktuar matricën deri në pjesët përbërëse të saj dhe duke i bërë më të lehta llogaritjet me atë matricë. SVD mund të përdoret si për matricat me vlerë reale ashtu edhe për matricat komplekse, por për qëllimet e këtij shpjegimi, do të shqyrtohet se si të zbërthehet një matricë e vlerave reale.
Supozojmë se kemi një matricë të përbërë nga të dhëna me vlerë reale dhe qëllimi ynë është të zvogëlojmë numrin e kolonave/veçorive brenda matricës, të ngjashme me qëllimin e PCA. Ashtu si PCA, SVD do të kompresojë dimensionalitetin e matricës duke ruajtur sa më shumë ndryshueshmërinë e matricës. Nëse duam të operojmë në matricën A, ne mund ta paraqesim matricën A si tre matrica të tjera të quajtura U, D dhe V. Matrica A përbëhet nga elementët origjinalë x * y ndërsa matrica U përbëhet nga elementët X * X (është një matricë ortogonale). Matrica V është një matricë e ndryshme ortogonale që përmban elemente y * y. Matrica D përmban elementet x * y dhe është një matricë diagonale.
Për të zbërthyer vlerat për matricën A, duhet të konvertojmë vlerat origjinale të matricës njëjës në vlerat diagonale të gjetura brenda një matrice të re. Kur punohet me matrica ortogonale, vetitë e tyre nuk ndryshojnë nëse shumëzohen me numra të tjerë. Prandaj, ne mund të përafrojmë matricën A duke përfituar nga kjo veti. Kur shumëzojmë matricat ortogonale së bashku me një transpozim të Matricës V, rezultati është një matricë ekuivalente me A-në tonë origjinale.
Kur Matrica a zbërthehet në matricat U, D dhe V, ato përmbajnë të dhënat e gjetura brenda Matricës A. Megjithatë, kolonat më të majta të matricave do të mbajnë shumicën e të dhënave. Ne mund të marrim vetëm këto kolona të para dhe të kemi një paraqitje të Matricës A që ka shumë më pak dimensione dhe shumicën e të dhënave brenda A.
Analiza Diskriminuese Lineare

Majtas: Matrica përpara LDA, djathtas: Boshti pas LDA, tani i ndashëm
Analiza Diskriminuese Lineare (LDA) është një proces që merr të dhëna nga një grafik shumëdimensional dhe e riprojekton atë në një grafik linear. Ju mund ta imagjinoni këtë duke menduar për një grafik dydimensional të mbushur me pika të dhënash që u përkasin dy klasave të ndryshme. Supozoni se pikat janë të shpërndara përreth, kështu që nuk mund të vizatohet asnjë vijë që do të ndajë mirë dy klasat e ndryshme. Për të trajtuar këtë situatë, pikat e gjetura në grafikun 2D mund të reduktohen në një grafik 1D (një vijë). Kjo linjë do të ketë të gjitha pikat e të dhënave të shpërndara nëpër të dhe shpresojmë se mund të ndahet në dy seksione që përfaqësojnë ndarjen më të mirë të mundshme të të dhënave.
Gjatë kryerjes së LDA ka dy qëllime kryesore. Qëllimi i parë është minimizimi i variancës për klasat, ndërsa qëllimi i dytë është maksimizimi i distancës midis mesatareve të dy klasave. Këto qëllime arrihen duke krijuar një bosht të ri që do të ekzistojë në grafikun 2D. Boshti i krijuar rishtazi vepron për të ndarë dy klasat bazuar në qëllimet e përshkruara më parë. Pasi të jetë krijuar boshti, pikat e gjetura në grafikun 2D vendosen përgjatë boshtit.
Kërkohen tre hapa për të zhvendosur pikat origjinale në një pozicion të ri përgjatë boshtit të ri. Në hapin e parë, distanca ndërmjet mesatareve të klasave individuale (varianca ndërmjet klasave) përdoret për të llogaritur ndashmërinë e klasave. Në hapin e dytë, llogaritet varianca brenda klasave të ndryshme, duke përcaktuar distancën midis mostrës dhe mesatares për klasën në fjalë. Në hapin e fundit, krijohet hapësira me dimensione më të ulëta që maksimizon variancën midis klasave.
Teknika LDA arrin rezultatet më të mira kur mjetet për klasat e synuara janë shumë larg njëra-tjetrës. LDA nuk mund t'i ndajë në mënyrë efektive klasat me një bosht linear nëse mjetet për shpërndarjet mbivendosen.










