
UA 101
Çfarë është regresioni linear?
Çfarë është regresioni linear?
Regresioni linear është një algoritëm i përdorur për të parashikuar, ose vizualizuar, a marrëdhënia ndërmjet dy veçorive/variablave të ndryshme. Në detyrat e regresionit linear, ekzaminohen dy lloje variablash: the variabli i varur dhe ndryshorja e pavarur. Variabli i pavarur është ndryshorja që qëndron në vetvete, e pa ndikuar nga ndryshorja tjetër. Me rregullimin e ndryshores së pavarur, nivelet e ndryshores së varur do të luhaten. Variabla e varur është ndryshorja që studiohet dhe është ajo për të cilën modeli i regresionit zgjidh/përpjek për të parashikuar. Në detyrat e regresionit linear, çdo vëzhgim/instancë përbëhet nga vlera e variablit të varur dhe nga vlera e ndryshores së pavarur.
Ky ishte një shpjegim i shpejtë i regresionit linear, por le të sigurohemi që të arrijmë në një kuptim më të mirë të regresionit linear duke parë një shembull të tij dhe duke shqyrtuar formulën që ai përdor.
Kuptimi i regresionit linear
Supozoni se kemi një grup të dhënash që mbulon madhësitë e hard disqeve dhe koston e atyre disqeve.
Le të supozojmë se grupi i të dhënave që kemi përbëhet nga dy karakteristika të ndryshme: sasia e memories dhe kostoja. Sa më shumë memorie të blejmë për një kompjuter, aq më shumë rritet kostoja e blerjes. Nëse vizatojmë pikat individuale të të dhënave në një grafik shpërndarjeje, mund të marrim një grafik që duket diçka si kjo:

Raporti i saktë i kujtesës ndaj kostos mund të ndryshojë midis prodhuesve dhe modeleve të hard drive-it, por në përgjithësi, tendenca e të dhënave është ajo që fillon në pjesën e poshtme majtas (ku hard disqet janë edhe më të lirë dhe kanë kapacitet më të vogël) dhe lëviz në djathtas sipër (ku disqet janë më të shtrenjtë dhe kanë kapacitet më të lartë).
Nëse do të kishim sasinë e memories në boshtin X dhe koston në boshtin Y, një linjë që kap marrëdhënien midis ndryshoreve X dhe Y do të fillonte në këndin e poshtëm majtas dhe do të shkonte në të djathtën e sipërme.
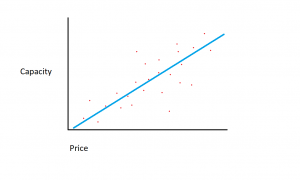
Funksioni i një modeli regresioni është të përcaktojë një funksion linear midis ndryshoreve X dhe Y që përshkruan më së miri marrëdhënien midis dy variablave. Në regresionin linear, supozohet se Y mund të llogaritet nga disa kombinime të variablave hyrëse. Marrëdhënia midis variablave hyrëse (X) dhe ndryshoreve të synuara (Y) mund të portretizohet duke tërhequr një vijë përmes pikave në grafik. Linja përfaqëson funksionin që përshkruan më së miri marrëdhënien midis X dhe Y (për shembull, për çdo herë që X rritet me 3, Y rritet me 2). Qëllimi është të gjendet një "vijë regresioni" optimale, ose linja/funksioni që i përshtatet më së miri të dhënave.
Vijat zakonisht përfaqësohen nga ekuacioni: Y = m*X + b. X i referohet ndryshores së varur ndërsa Y është ndryshorja e pavarur. Ndërkohë, m është pjerrësia e vijës, siç përcaktohet nga "ngritja" mbi "run". Praktikuesit e mësimit të makinerive përfaqësojnë ekuacionin e famshëm të vijës së pjerrësisë pak më ndryshe, duke përdorur këtë ekuacion në vend të kësaj:
y(x) = w0 + w1 * x
Në ekuacionin e mësipërm, y është ndryshorja e synuar ndërsa "w" janë parametrat e modelit dhe hyrja është "x". Pra, ekuacioni lexohet si: “Funksioni që jep Y, në varësi të X, është i barabartë me parametrat e modelit të shumëzuar me veçoritë”. Parametrat e modelit rregullohen gjatë stërvitjes për të marrë linjën më të përshtatshme të regresionit.
Regresioni linear i shumëfishtë

Foto: Cbaf nëpërmjet Wikimedia Commons, Domain Publik (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
Procesi i përshkruar më sipër zbatohet për regresionin e thjeshtë linear, ose regresionin në grupet e të dhënave ku ka vetëm një veçori të vetme/ndryshore të pavarur. Megjithatë, një regresion mund të bëhet edhe me karakteristika të shumta. Në rastin e "regresioni linear i shumëfishtë”, ekuacioni zgjerohet nga numri i variablave që gjenden brenda grupit të të dhënave. Me fjalë të tjera, ndërsa ekuacioni për regresionin e rregullt linear është y(x) = w0 + w1 * x, ekuacioni për regresionin e shumëfishtë linear do të ishte y(x) = w0 + w1x1 plus peshat dhe hyrjet për tiparet e ndryshme. Nëse përfaqësojmë numrin total të peshave dhe veçorive si w(n)x(n), atëherë mund të përfaqësojmë formulën si kjo:
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
Pas vendosjes së formulës për regresionin linear, modeli i mësimit të makinerive do të përdorë vlera të ndryshme për peshat, duke tërhequr vija të ndryshme përshtatjeje. Mos harroni se qëllimi është të gjeni linjën që i përshtatet më mirë të dhënave në mënyrë që të përcaktojë se cili nga kombinimet e mundshme të peshës (dhe për rrjedhojë cila linjë e mundshme) i përshtatet më mirë të dhënave dhe shpjegon marrëdhënien midis variablave.
Një funksion i kostos përdoret për të matur se sa afër janë vlerat e supozuara Y me vlerat aktuale Y kur jepet një vlerë e caktuar peshe. Funksioni i kostos për regresionin linear është gabimi mesatar në katror, i cili merr vetëm gabimin mesatar (në katror) midis vlerës së parashikuar dhe vlerës së vërtetë për të gjitha pikat e ndryshme të të dhënave në grupin e të dhënave. Funksioni i kostos përdoret për të llogaritur një kosto, e cila kap diferencën midis vlerës së synuar të parashikuar dhe vlerës së vërtetë të synuar. Nëse linja e përshtatjes është larg pikave të të dhënave, kostoja do të jetë më e lartë, ndërsa kostoja do të bëhet më e vogël sa më afër vija të kap marrëdhëniet e vërteta midis variablave. Peshat e modelit më pas rregullohen derisa të gjendet konfigurimi i peshës që prodhon sasinë më të vogël të gabimit.










