
UA 101
Çfarë është Overfitting?
Çfarë është Overfitting?
Kur trajnoni një rrjet nervor, duhet të shmangni përshtatjen e tepërt. Përshtatje e tepërt është një çështje brenda mësimit të makinerive dhe statistikave ku një model mëson shumë mirë modelet e një grupi të dhënash trajnimi, duke shpjeguar në mënyrë të përsosur grupin e të dhënave të trajnimit, por duke dështuar të përgjithësojë fuqinë e tij parashikuese në grupe të tjera të dhënash.
Për ta thënë ndryshe, në rastin e një modeli të tepërt, ai shpesh do të tregojë saktësi jashtëzakonisht të lartë në grupin e të dhënave të trajnimit, por saktësi të ulët në të dhënat e mbledhura dhe të ekzekutuara përmes modelit në të ardhmen. Ky është një përkufizim i shpejtë i përshtatjes së tepërt, por le të shqyrtojmë më në detaje konceptin e mbipërshtatjes. Le të hedhim një vështrim se si ndodh mbipërshtatja dhe si mund të shmanget.
Kuptimi i "përshtatjes" dhe i nënpërshtatjes
Është e dobishme t'i hedhim një vështrim konceptit të mospërshtatjes dhe "i aftë” përgjithësisht kur diskutohet mbi përshtatjen. Kur trajnojmë një model, ne po përpiqemi të zhvillojmë një kornizë që është e aftë të parashikojë natyrën ose klasën e artikujve brenda një grupi të dhënash, bazuar në veçoritë që përshkruajnë ato artikuj. Një model duhet të jetë në gjendje të shpjegojë një model brenda një grupi të dhënash dhe të parashikojë klasat e pikave të të dhënave të ardhshme bazuar në këtë model. Sa më mirë modeli të shpjegojë marrëdhënien midis veçorive të grupit të trajnimit, aq më i "përshtatshëm" është modeli ynë.
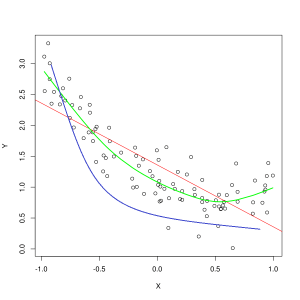
Vija blu përfaqëson parashikimet nga një model që nuk përshtatet, ndërsa vija e gjelbër përfaqëson një model më të përshtatshëm. Foto: Pep Roca nëpërmjet Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Një model që shpjegon dobët marrëdhënien midis veçorive të të dhënave të trajnimit dhe kështu nuk arrin të klasifikojë me saktësi shembujt e të dhënave të ardhshme është nënpërshtatje të dhënat e trajnimit. Nëse do të grafikonit marrëdhënien e parashikuar të një modeli të papërshtatshëm kundrejt kryqëzimit aktual të veçorive dhe etiketave, parashikimet do të largoheshin nga pikëpamja. Nëse do të kishim një grafik me vlerat aktuale të një grupi trajnimi të etiketuar, një model shumë i papërshtatshëm do të humbiste në mënyrë drastike shumicën e pikave të të dhënave. Një model me një përshtatje më të mirë mund të presë një rrugë përmes qendrës së pikave të të dhënave, me pikat individuale të të dhënave që janë vetëm pak jashtë vlerave të parashikuara.
Mospërshtatja shpesh mund të ndodhë kur ka të dhëna të pamjaftueshme për të krijuar një model të saktë, ose kur përpiqeni të hartoni një model linear me të dhëna jolineare. Më shumë të dhëna trajnimi ose më shumë veçori shpesh do të ndihmojnë në reduktimin e mungesës së përshtatjes.
Pra, pse të mos krijojmë thjesht një model që shpjegon çdo pikë në të dhënat e trajnimit në mënyrë të përsosur? Sigurisht që saktësia e përsosur është e dëshirueshme? Krijimi i një modeli që ka mësuar shumë mirë modelet e të dhënave të trajnimit është ajo që shkakton mbipërshtatjen. Grupi i të dhënave të trajnimit dhe grupet e tjera të të dhënave të ardhshme që do të përdorni përmes modelit nuk do të jenë saktësisht të njëjta. Ka të ngjarë të jenë shumë të ngjashme në shumë aspekte, por gjithashtu do të ndryshojnë në mënyra kryesore. Prandaj, dizajnimi i një modeli që shpjegon në mënyrë të përsosur grupin e të dhënave të trajnimit do të thotë që të përfundoni me një teori rreth marrëdhënies midis veçorive që nuk përgjithësohet mirë me grupet e tjera të të dhënave.
Kuptimi i mbipërshtatjes
Përshtatja e tepërt ndodh kur një model mëson shumë mirë detajet brenda grupit të të dhënave të trajnimit, duke bërë që modeli të vuajë kur bëhen parashikime mbi të dhënat e jashtme. Kjo mund të ndodhë kur modeli jo vetëm që mëson veçoritë e grupit të të dhënave, por gjithashtu mëson luhatjet e rastësishme ose zhurmë brenda grupit të të dhënave, duke i dhënë rëndësi këtyre dukurive të rastësishme/të parëndësishme.
Mbi përshtatja ka më shumë gjasa të ndodhë kur përdoren modele jolineare, pasi ato janë më fleksibël kur mësojnë veçoritë e të dhënave. Algoritmet joparametrike të mësimit të makinerive shpesh kanë parametra dhe teknika të ndryshme që mund të aplikohen për të kufizuar ndjeshmërinë e modelit ndaj të dhënave dhe në këtë mënyrë për të zvogëluar mbipërshtatjen. Si nje shembull, modelet e pemës së vendimit janë shumë të ndjeshme ndaj përshtatjes së tepërt, por një teknikë e quajtur krasitje mund të përdoret për të hequr rastësisht disa nga detajet që modeli ka mësuar.
Nëse do të jepnit grafikisht parashikimet e modelit në boshtet X dhe Y, do të kishit një linjë parashikimi që shkon me zigzag përpara dhe mbrapa, gjë që pasqyron faktin se modeli është përpjekur shumë për të përshtatur të gjitha pikat në grupin e të dhënave në shpjegimin e saj.
Kontrolli i mbipërshtatjes
Kur trajnojmë një model, në mënyrë ideale duam që modeli të mos bëjë gabime. Kur performanca e modelit konvergon drejt bërjes së parashikimeve të sakta në të gjitha pikat e të dhënave në grupin e të dhënave të trajnimit, përshtatja po bëhet më e mirë. Një model me një përshtatje të mirë është në gjendje të shpjegojë pothuajse të gjithë grupin e të dhënave të trajnimit pa e tepërt.
Ndërsa një model stërvit, performanca e tij përmirësohet me kalimin e kohës. Shkalla e gabimit të modelit do të ulet me kalimin e kohës së trajnimit, por zvogëlohet vetëm në një pikë të caktuar. Pika në të cilën performanca e modelit në grupin e testimit fillon të rritet përsëri është zakonisht pika në të cilën ndodh mbipërshtatja. Në mënyrë që të kemi përshtatjen më të mirë për një model, ne duam të ndalojmë stërvitjen e modelit në pikën e humbjes më të ulët në grupin e trajnimit, përpara se gabimi të fillojë të rritet përsëri. Pika optimale e ndalimit mund të konstatohet duke paraqitur grafikun e performancës së modelit gjatë gjithë kohës së stërvitjes dhe duke ndërprerë stërvitjen kur humbja është më e ulëta. Megjithatë, një rrezik me këtë metodë të kontrollit për mbipërshtatje është se specifikimi i pikës përfundimtare për trajnimin bazuar në performancën e testit do të thotë që të dhënat e testit përfshihen disi në procedurën e trajnimit dhe humbin statusin e tyre si të dhëna thjesht "të paprekura".
Ka disa mënyra të ndryshme që dikush mund të luftojë mbipërshtatjen. Një metodë për të reduktuar mbipërshtatjen është përdorimi i një taktike rimostrimi, e cila funksionon duke vlerësuar saktësinë e modelit. Ju gjithashtu mund të përdorni një sanksionim grupi i të dhënave përveç grupit të testit dhe vizatoni saktësinë e trajnimit kundrejt grupit të vlefshmërisë në vend të grupit të të dhënave testuese. Kjo e mban të padukshme të dhënat tuaja të testimit. Një metodë e njohur e rimarrjes së mostrave është vërtetimi i kryqëzuar me K-folds. Kjo teknikë ju mundëson të ndani të dhënat tuaja në nënbashkësi ku modeli është trajnuar, dhe më pas performanca e modelit në nëngrupet analizohet për të vlerësuar se si do të performojë modeli në të dhënat e jashtme.
Përdorimi i verifikimit të kryqëzuar është një nga mënyrat më të mira për të vlerësuar saktësinë e një modeli në të dhëna të padukshme, dhe kur kombinohet me një bazë të dhënash vërtetimi, mbipërshtatja shpesh mund të mbahet në minimum.










