
AI 101
Čo je to rozhodovací strom?
Čo je to rozhodovací strom?
A rozhodovací strom je užitočný algoritmus strojového učenia používaný pre regresné aj klasifikačné úlohy. Názov „rozhodovací strom“ pochádza zo skutočnosti, že algoritmus neustále rozdeľuje množinu údajov na menšie a menšie časti, až kým sa údaje nerozdelia do jednotlivých inštancií, ktoré sa potom klasifikujú. Ak by ste mali vizualizovať výsledky algoritmu, spôsob, akým sú kategórie rozdelené, by pripomínal strom a veľa listov.
To je rýchla definícia rozhodovacieho stromu, ale poďme sa hlboko ponoriť do toho, ako rozhodovacie stromy fungujú. Lepšie pochopenie toho, ako fungujú rozhodovacie stromy, ako aj ich prípady použitia, vám pomôže zistiť, kedy ich použiť počas vašich projektov strojového učenia.
Formát rozhodovacieho stromu
Rozhodovací strom je veľa ako vývojový diagram. Ak chcete použiť vývojový diagram, začnete v počiatočnom bode alebo koreňovom bode diagramu a potom na základe toho, ako odpoviete na kritériá filtrovania tohto počiatočného uzla, sa presuniete do jedného z ďalších možných uzlov. Tento proces sa opakuje, kým sa nedosiahne koniec.
Rozhodovacie stromy fungujú v podstate rovnakým spôsobom, pričom každý vnútorný uzol v strome je určitým druhom testovacieho/filtračného kritéria. Uzly na vonkajšej strane, koncové body stromu, sú označeniami pre príslušný údajový bod a nazývajú sa „listy“. Vetvy, ktoré vedú z vnútorných uzlov k ďalšiemu uzlu, sú prvky alebo spojenia prvkov. Pravidlá používané na klasifikáciu údajových bodov sú cesty, ktoré prebiehajú od koreňového po listy.
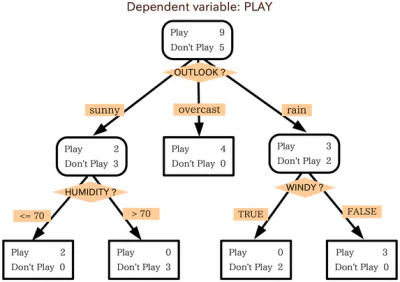
Algoritmy pre rozhodovacie stromy
Rozhodovacie stromy fungujú na algoritmickom prístupe, ktorý rozdeľuje súbor údajov na jednotlivé údajové body na základe rôznych kritérií. Tieto rozdelenia sa vykonávajú s rôznymi premennými alebo rôznymi funkciami súboru údajov. Napríklad, ak je cieľom určiť, či je pes alebo mačka popisovaný vstupnými funkciami, premenné, na ktoré sa údaje delia, môžu byť veci ako „pazúry“ a „štekanie“.
Aké algoritmy sa teda používajú na skutočné rozdelenie údajov na vetvy a listy? Existujú rôzne metódy, ktoré možno použiť na rozdelenie stromu, ale najbežnejšou metódou rozdelenia je pravdepodobne technika označovaná ako „rekurzívne binárne rozdelenie“. Pri vykonávaní tohto spôsobu rozdelenia proces začína od koreňa a počet funkcií v súbore údajov predstavuje možný počet možných rozdelení. Funkcia sa používa na určenie toho, koľko presnosti bude každé možné rozdelenie stáť, a rozdelenie sa vykoná pomocou kritérií, ktoré obetujú najmenšiu presnosť. Tento proces sa uskutočňuje rekurzívne a podskupiny sa vytvárajú pomocou rovnakej všeobecnej stratégie.
Aby sa určiť náklady na rozdelenie, používa sa nákladová funkcia. Pre regresné úlohy a klasifikačné úlohy sa používa odlišná nákladová funkcia. Cieľom oboch nákladových funkcií je určiť, ktoré odvetvia majú najpodobnejšie hodnoty odozvy, prípadne najhomogénnejšie odvetvia. Zvážte, že chcete, aby testovacie údaje určitej triedy sledovali určité cesty, a to dáva intuitívny zmysel.
Pokiaľ ide o funkciu regresných nákladov pre rekurzívne binárne rozdelenie, algoritmus použitý na výpočet nákladov je nasledujúci:
súčet(y – predpoveď)^2
Predikcia pre konkrétnu skupinu dátových bodov je priemer odpovedí trénovacích dát pre túto skupinu. Všetky dátové body prechádzajú cez nákladovú funkciu, aby sa určili náklady pre všetky možné rozdelenia a vyberie sa rozdelenie s najnižšími nákladmi.
Pokiaľ ide o funkciu nákladov na klasifikáciu, funkcia je takáto:
G = súčet(pk * (1 – pk))
Toto je skóre Gini a je to meranie účinnosti rozdelenia na základe toho, koľko inštancií rôznych tried je v skupinách vyplývajúcich z rozdelenia. Inými slovami, kvantifikuje, ako zmiešané sú skupiny po rozdelení. Optimálne rozdelenie je, keď všetky skupiny vyplývajúce z rozdelenia pozostávajú iba zo vstupov z jednej triedy. Ak bolo vytvorené optimálne rozdelenie, hodnota „pk“ bude buď 0 alebo 1 a G sa bude rovnať nule. V prípade binárnej klasifikácie by ste mohli uhádnuť, že najhorším prípadom je rozdelenie, v ktorom je zastúpenie tried v rozdelení 50-50. V tomto prípade by hodnota „pk“ bola 0.5 a G by tiež bola 0.5.
Proces delenia sa ukončí, keď sa všetky dátové body premenia na listy a klasifikujú sa. Možno však budete chcieť zastaviť rast stromu skôr. Veľké zložité stromy sú náchylné na nadmernú montáž, ale na boj proti tomu možno použiť niekoľko rôznych metód. Jednou z metód zníženia presadzovania je špecifikácia minimálneho počtu údajových bodov, ktoré sa použijú na vytvorenie listu. Ďalšou metódou kontroly nadstavby je obmedzenie stromu na určitú maximálnu hĺbku, ktorá riadi, ako dlho sa môže cesta tiahnuť od koreňa po list.
Ďalší proces zapojený do vytvárania rozhodovacích stromov je prerezávanie. Prerezávanie môže pomôcť zvýšiť výkon rozhodovacieho stromu odstránením vetiev obsahujúcich prvky, ktoré majú pre model malú predikčnú silu/malý význam. Týmto spôsobom sa znižuje zložitosť stromu, je menej pravdepodobné, že sa prepasuje a zvyšuje sa prediktívna užitočnosť modelu.
Pri vykonávaní prerezávania môže proces začať buď v hornej časti stromu, alebo v spodnej časti stromu. Najjednoduchším spôsobom prerezávania je však začať s listami a pokúsiť sa vypustiť uzol, ktorý obsahuje najbežnejšiu triedu v tomto liste. Ak sa presnosť modelu nezhorší, potom sa zmena zachová. Na vykonávanie rezu sa používajú aj iné techniky, ale vyššie opísaná metóda – prerezávanie so zníženou chybovosťou – je pravdepodobne najbežnejšou metódou rezu rozhodovacích stromov.
Úvahy o používaní rozhodovacích stromov
Rozhodovacie stromy sú často užitočné keď je potrebné vykonať klasifikáciu, ale čas výpočtu je hlavným obmedzením. Rozhodovacie stromy môžu objasniť, ktoré funkcie vo vybraných súboroch údajov majú najväčšiu predikčnú silu. Okrem toho, na rozdiel od mnohých algoritmov strojového učenia, kde pravidlá používané na klasifikáciu údajov môžu byť ťažko interpretovateľné, rozhodovacie stromy môžu poskytnúť interpretovateľné pravidlá. Rozhodovacie stromy sú tiež schopné využívať kategorické aj spojité premenné, čo znamená, že je potrebné menšie predspracovanie v porovnaní s algoritmami, ktoré dokážu spracovať iba jeden z týchto typov premenných.
Rozhodovacie stromy zvyčajne nefungujú veľmi dobre, keď sa používajú na určenie hodnôt spojitých atribútov. Ďalším obmedzením rozhodovacích stromov je to, že pri klasifikácii, ak existuje málo príkladov školenia, ale veľa tried, má rozhodovací strom tendenciu byť nepresný.










