
AI 101
Čo je to gradientný zostup?
Čo je to gradientný zostup?
Ak ste čítali o tom, ako sa trénujú neurónové siete, takmer určite ste sa už stretli s pojmom „gradientný zostup“. Gradientný zostup je primárna metóda optimalizácie výkonu neurónovej siete, ktorá znižuje stratovosť/chybovosť siete. Pre začiatočníkov v oblasti strojového učenia však môže byť zostup gradientu trochu ťažko pochopiteľný a tento článok sa vám pokúsi poskytnúť slušnú intuíciu o tom, ako funguje gradientový zostup.
Gradient zostup je optimalizačný algoritmus. Používa sa na zlepšenie výkonu neurónovej siete vykonávaním úprav parametrov siete tak, aby rozdiel medzi predpoveďami siete a skutočnými/očakávanými hodnotami siete (označovaný ako strata) bol čo najmenší. Gradient zostup berie počiatočné hodnoty parametrov a používa operácie založené na výpočte na úpravu ich hodnôt smerom k hodnotám, vďaka ktorým bude sieť tak presná, ako len môže byť. Nepotrebujete vedieť veľa kalkulu, aby ste pochopili, ako funguje gradientový zostup, ale musíte porozumieť gradientom.
Čo sú to prechody?
Predpokladajme, že existuje graf, ktorý predstavuje množstvo chýb, ktoré neurónová sieť robí. Spodná časť grafu predstavuje body s najnižšou chybou, zatiaľ čo horná časť grafu je miesto, kde je chyba najvyššia. Chceme sa presunúť z hornej časti grafu nadol. Gradient je len spôsob kvantifikácie vzťahu medzi chybou a váhami neurónovej siete. Vzťah medzi týmito dvoma vecami možno vykresliť ako sklon, pričom nesprávne hmotnosti spôsobujú viac chýb. Strmosť svahu/gradientu predstavuje, ako rýchlo sa model učí.
Strmší svah znamená, že dochádza k veľkému zníženiu chýb a model sa rýchlo učí, zatiaľ čo ak je sklon nula, model je na náhornej plošine a neučí sa. Po svahu smerom k menšej chybe sa môžeme pohybovať výpočtom gradientu, smeru pohybu (zmeny parametrov siete) pre náš model.
Posuňme metaforu len mierne a predstavme si rad kopcov a dolín. Chceme sa dostať pod kopec a nájsť časť doliny, ktorá predstavuje najnižšiu stratu. Keď začneme na vrchole kopca, môžeme urobiť veľké kroky dole kopcom a byť si istí, že smerujeme k najnižšiemu bodu v doline.
Keď sa však približujeme k najnižšiemu bodu v údolí, naše kroky sa budú musieť zmenšiť, inak by sme mohli presiahnuť skutočný najnižší bod. Podobne je možné, že pri úprave váh siete ju môžu úpravy skutočne oddialiť od bodu najnižšej straty, a preto sa úpravy musia časom zmenšiť. V súvislosti so zostupom z kopca smerom k bodu s najnižšou stratou je gradient vektorom/pokynmi podrobne opisujúcimi cestu, ktorou by sme sa mali vydať a aké veľké by mali byť naše kroky.
Teraz vieme, že gradienty sú inštrukcie, ktoré nám hovoria, ktorým smerom sa máme pohybovať (ktoré koeficienty by sa mali aktualizovať) a aké veľké kroky by sme mali urobiť (koľko by sa koeficienty mali aktualizovať), môžeme preskúmať, ako sa gradient vypočíta.
Výpočet gradientov a zostupu gradientov
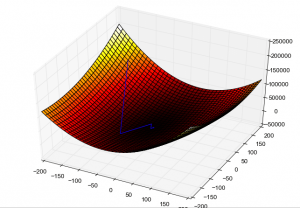
Gradientný zostup začína na mieste s vysokou stratou a prostredníctvom viacerých iterácií robí kroky v smere najnižšej straty s cieľom nájsť optimálnu konfiguráciu hmotnosti. Foto: Роман Сузи cez Wikimedia Commons, CCY BY SA 3.0 (https://commons.wikimedia.org/wiki/File:Gradient_descent_method.png)
Aby bolo možné vykonať gradientový zostup, musia sa najprv vypočítať gradienty. V poriadku na výpočet gradientu, potrebujeme poznať funkciu straty/nákladov. Na určenie derivácie použijeme nákladovú funkciu. V kalkulácii sa derivácia vzťahuje len na sklon funkcie v danom bode, takže v podstate len vypočítavame sklon kopca na základe stratová funkcia. Stratu určíme prevedením koeficientov cez stratovú funkciu. Ak stratovú funkciu znázorníme ako „f“, môžeme konštatovať, že rovnica na výpočet straty je nasledovná (koeficienty len prechádzame cez nami zvolenú nákladovú funkciu):
Strata = f (koeficient)
Následne vypočítame deriváciu, prípadne určíme sklon. Získanie derivácie straty nám povie, ktorý smer je nahor alebo nadol po svahu, a to tak, že nám dá príslušné znamenie, podľa ktorého upravíme naše koeficienty. Príslušný smer budeme reprezentovať ako „delta“.
delta = derivačná_funkcia (strata)
Teraz sme určili, ktorý smer je z kopca smerom k bodu najnižšej straty. To znamená, že môžeme aktualizovať koeficienty v parametroch neurónovej siete a dúfajme, že znížime straty. Koeficienty aktualizujeme na základe predchádzajúcich koeficientov mínus príslušná zmena hodnoty určená smerom (delta) a argumentom, ktorý riadi veľkosť zmeny (veľkosť nášho kroku). Argument, ktorý riadi veľkosť aktualizácie, sa nazýva „rýchlosť učenia“ a budeme ho reprezentovať ako „alfa“.
koeficient = koeficient – (alfa * delta)
Potom už len opakujeme tento proces, kým sieť nekonverguje okolo bodu najnižšej straty, ktorý by mal byť blízko nule.
Je veľmi dôležité zvoliť správnu hodnotu rýchlosti učenia (alfa). Zvolená rýchlosť učenia nesmie byť ani príliš malá, ani príliš veľká. Pamätajte, že keď sa blížime k bodu najnižšej straty, naše kroky sa musia zmenšiť, inak prekročíme skutočný bod najnižšej straty a skončíme na druhej strane. Bod najmenšej straty je malý a ak je naša rýchlosť zmeny príliš veľká, chyba sa môže opäť zvýšiť. Ak sú veľkosti krokov príliš veľké, výkon siete bude aj naďalej skákať okolo bodu najnižšej straty, pričom bude presahovať na jednej a potom na druhej strane. Ak k tomu dôjde, sieť sa nikdy nepriblíži k skutočnej optimálnej konfigurácii hmotnosti.
Naopak, ak je rýchlosť učenia príliš malá, sieti môže potenciálne trvať mimoriadne dlho, kým sa priblíži k optimálnym váhám.
Typy gradientového zostupu
Teraz, keď sme pochopili, ako gradientový zostup vo všeobecnosti funguje, poďme sa pozrieť na niektoré z rôznych typy gradientového zostupu.
Dávkový zostup gradientu: Táto forma zostupu gradientu prechádza cez všetky tréningové vzorky pred aktualizáciou koeficientov. Tento typ zostupu gradientu bude pravdepodobne výpočtovo najefektívnejšou formou zostupu gradientu, pretože váhy sa aktualizujú až po spracovaní celej dávky, čo znamená, že celkovo je aktualizácií menej. Ak však množina údajov obsahuje veľký počet príkladov tréningu, potom môže dávkový zostup gradientu spôsobiť, že tréning bude trvať dlho.
Stochastic Gradient Descent: V Stochastic Gradient Descent sa spracuje iba jeden príklad tréningu pre každú iteráciu zostupu gradientu a aktualizáciu parametrov. Toto sa vyskytuje pri každom príklade školenia. Pretože sa pred aktualizáciou parametrov spracuje iba jeden príklad školenia, má tendenciu konvergovať rýchlejšie ako zostup dávkového gradientu, pretože aktualizácie sa vykonajú skôr. Pretože však tento proces musí byť vykonaný na každej položke v trénovacej množine, môže trvať pomerne dlho, kým sa dokončí, ak je množina údajov veľká, a preto, ak je to preferované, použite jeden z iných typov zostupu gradientu.
Mini-Batch Gradient Descent: Mini-Batch Gradient Descent funguje tak, že rozdelí celý tréningový súbor údajov na podsekcie. Vytvára menšie mini-dávky, ktoré prebiehajú cez sieť, a keď sa mini-dávka použije na výpočet chyby, koeficienty sa aktualizujú. Mini-batch Gradient Descent predstavuje stred medzi Stochastickým Gradient Descentom a Batch Gradient Descentom. Model sa aktualizuje častejšie ako v prípade zostupu dávkového gradientu, čo znamená o niečo rýchlejšiu a robustnejšiu konvergenciu k optimálnym parametrom modelu. Je tiež výpočtovo efektívnejší ako Stochastic Gradient Descent














