
AI 101
Čo je lineárna regresia?
Čo je lineárna regresia?
Lineárna regresia je algoritmus používaný na predpovedanie alebo vizualizáciu a vzťah medzi dvoma rôznymi vlastnosťami/premennými. V úlohách lineárnej regresie sa skúmajú dva druhy premenných: závislej premennej a nezávislej premennej. Nezávislá premenná je premenná, ktorá stojí sama osebe a nie je ovplyvnená inou premennou. Pri úprave nezávislej premennej budú hladiny závislej premennej kolísať. Závislá premenná je premenná, ktorá sa študuje, a to je to, čo regresný model rieši/pokúša sa predpovedať. V úlohách lineárnej regresie sa každé pozorovanie/prípad skladá z hodnoty závislej premennej aj hodnoty nezávislej premennej.
To bolo rýchle vysvetlenie lineárnej regresie, ale presvedčte sa, že lineárnej regresii lepšie porozumieme tak, že sa pozrieme na jej príklad a preskúmame vzorec, ktorý používa.
Pochopenie lineárnej regresie
Predpokladajme, že máme súbor údajov o veľkostiach pevných diskov a nákladoch na tieto pevné disky.
Predpokladajme, že súbor údajov, ktorý máme, pozostáva z dvoch rôznych funkcií: množstva pamäte a nákladov. Čím viac pamäte do počítača zakúpime, tým viac sa cena nákupu zvýši. Ak by sme vyniesli jednotlivé dátové body do bodového grafu, mohli by sme dostať graf, ktorý vyzerá asi takto:

Presný pomer pamäte k cene sa môže líšiť medzi výrobcami a modelmi pevných diskov, ale vo všeobecnosti je trend údajov taký, ktorý začína vľavo dole (kde sú pevné disky lacnejšie a majú menšiu kapacitu) a presúvajú sa na vpravo hore (kde sú disky drahšie a majú vyššiu kapacitu).
Ak by sme mali množstvo pamäte na osi X a náklady na os Y, čiara zachytávajúca vzťah medzi premennými X a Y by začínala v ľavom dolnom rohu a prebiehala by vpravo hore.
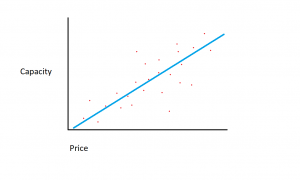
Funkciou regresného modelu je určiť lineárnu funkciu medzi premennými X a Y, ktorá najlepšie popisuje vzťah medzi týmito dvoma premennými. Pri lineárnej regresii sa predpokladá, že Y možno vypočítať z nejakej kombinácie vstupných premenných. Vzťah medzi vstupnými premennými (X) a cieľovými premennými (Y) možno zobraziť nakreslením čiary cez body v grafe. Čiara predstavuje funkciu, ktorá najlepšie popisuje vzťah medzi X a Y (napríklad pri každom zvýšení X o 3 sa Y zvýši o 2). Cieľom je nájsť optimálnu „regresnú čiaru“ alebo čiaru/funkciu, ktorá najlepšie zodpovedá údajom.
Čiary sú typicky reprezentované rovnicou: Y = m*X + b. X označuje závislú premennú, zatiaľ čo Y je nezávislá premenná. Medzitým m je sklon čiary, ako je definovaný „nárastom“ nad „behom“. Praktici strojového učenia predstavujú slávnu rovnicu sklonu trochu inak a namiesto toho používajú túto rovnicu:
y(x) = w0 + w1 * x
Vo vyššie uvedenej rovnici je y cieľová premenná, zatiaľ čo „w“ sú parametre modelu a vstup je „x“. Takže rovnica sa číta takto: „Funkcia, ktorá dáva Y v závislosti od X, sa rovná parametrom modelu vynásobeným vlastnosťami“. Parametre modelu sa upravujú počas tréningu tak, aby ste získali čo najlepšie prispôsobenú regresnú líniu.
Viacnásobná lineárna regresia

Foto: Cbaf cez Wikimedia Commons, Public Domain (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
Vyššie opísaný proces sa vzťahuje na jednoduchú lineárnu regresiu alebo regresiu na množinách údajov, kde existuje iba jedna vlastnosť/nezávislá premenná. Regresiu je však možné vykonať aj s viacerými funkciami. V prípade "viacnásobná lineárna regresia“, rovnica je rozšírená o počet premenných nájdených v súbore údajov. Inými slovami, kým rovnica pre pravidelnú lineárnu regresiu je y(x) = w0 + w1 * x, rovnica pre viacnásobnú lineárnu regresiu by bola y(x) = w0 + w1x1 plus váhy a vstupy pre rôzne funkcie. Ak znázorníme celkový počet váh a vlastností ako w(n)x(n), potom by sme vzorec mohli reprezentovať takto:
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
Po vytvorení vzorca pre lineárnu regresiu bude model strojového učenia používať rôzne hodnoty pre váhy, pričom nakreslí rôzne línie prispôsobenia. Pamätajte, že cieľom je nájsť riadok, ktorý najlepšie zodpovedá údajom, aby ste mohli určiť, ktorá z možných kombinácií váh (a teda ktorý možný riadok) najlepšie zodpovedá údajom, a vysvetliť vzťah medzi premennými.
Nákladová funkcia sa používa na meranie toho, ako blízko sú predpokladané hodnoty Y k skutočným hodnotám Y, keď je daná konkrétna hodnota hmotnosti. Nákladová funkcia pre lineárnu regresiu je stredná štvorcová chyba, ktorá berie len priemernú (kvadratúru) chybu medzi predpokladanou hodnotou a skutočnou hodnotou pre všetky rôzne dátové body v súbore údajov. Nákladová funkcia sa používa na výpočet nákladov, ktoré zachytávajú rozdiel medzi predpokladanou cieľovou hodnotou a skutočnou cieľovou hodnotou. Ak je preložená čiara ďaleko od údajových bodov, náklady budú vyššie, zatiaľ čo náklady budú menšie, čím viac sa čiara priblíži k zachyteniu skutočných vzťahov medzi premennými. Váhy modelu sa potom upravujú, kým sa nenájde konfigurácia závažia, ktorá vytvára najmenšiu chybu.










