
AI 101
Čo je to overfitting?
Čo je to overfitting?
Keď trénujete neurónovú sieť, musíte sa vyvarovať nadmerného vybavenia. Premnožené je problém v rámci strojového učenia a štatistiky, kde sa model príliš dobre učí vzory množiny trénovacích údajov, dokonale vysvetľuje množinu trénovacích údajov, ale nedokáže zovšeobecniť svoju predikčnú silu na iné množiny údajov.
Inak povedané, v prípade modelu s nadmerným vybavením bude často vykazovať extrémne vysokú presnosť v súbore trénovacích údajov, ale nízku presnosť údajov zhromaždených a prechádzajúcich modelom v budúcnosti. To je rýchla definícia nadmerného vybavenia, ale poďme si tento pojem prebrať podrobnejšie. Poďme sa pozrieť na to, ako dochádza k nadmernému vybaveniu a ako sa mu dá vyhnúť.
Pochopenie „vhodnosti“ a nedostatočného prispôsobenia
Je užitočné pozrieť sa na koncept podvybavenia a „fit“ vo všeobecnosti pri diskusii o nadmernom vybavení. Keď trénujeme model, snažíme sa vyvinúť rámec, ktorý je schopný predpovedať povahu alebo triedu položiek v rámci súboru údajov na základe funkcií, ktoré tieto položky opisujú. Model by mal byť schopný vysvetliť vzor v rámci súboru údajov a predpovedať triedy budúcich údajových bodov na základe tohto vzoru. Čím lepšie model vysvetľuje vzťah medzi vlastnosťami tréningovej zostavy, tým je náš model „vhodnejší“.
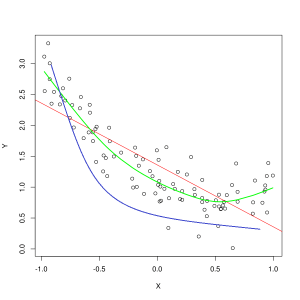
Modrá čiara predstavuje predpovede modelu, ktorý nevyhovuje, zatiaľ čo zelená čiara predstavuje model, ktorý lepšie vyhovuje. Foto: Pep Roca cez Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Model, ktorý nedostatočne vysvetľuje vzťah medzi vlastnosťami trénovacích údajov, a teda nedokáže presne klasifikovať budúce príklady údajov, je podvybavenie tréningové údaje. Ak by ste mali nakresliť predpokladaný vzťah modelu nedostatočnej výbavy oproti skutočnému priesečníku prvkov a štítkov, predpovede by sa odchýlili od značky. Ak by sme mali označený graf so skutočnými hodnotami tréningovej množiny, výrazne zaostávajúci model by drasticky minul väčšinu údajových bodov. Model s lepším prispôsobením môže prerezať cestu stredom údajových bodov, pričom jednotlivé údajové body budú len o málo mimo predpovedaných hodnôt.
Nedostatočné prispôsobenie sa môže často vyskytnúť, keď nie je dostatok údajov na vytvorenie presného modelu alebo keď sa pokúšate navrhnúť lineárny model s nelineárnymi údajmi. Viac tréningových údajov alebo viac funkcií často pomôže znížiť nedostatočné vybavenie.
Prečo by sme teda jednoducho nevytvorili model, ktorý dokonale vysvetľuje každý bod v tréningových údajoch? Je určite žiaduca dokonalá presnosť? Vytvorenie modelu, ktorý sa príliš dobre naučil vzorce tréningových údajov, spôsobuje nadmerné prispôsobenie. Tréningový súbor údajov a ďalšie budúce súbory údajov, ktoré spustíte prostredníctvom modelu, nebudú úplne rovnaké. Pravdepodobne budú v mnohých ohľadoch veľmi podobné, ale budú sa líšiť aj v kľúčových veciach. Preto navrhnutie modelu, ktorý dokonale vysvetľuje tréningový súbor údajov, znamená, že skončíte s teóriou o vzťahu medzi funkciami, ktorá sa nedá dobre zovšeobecniť na iné súbory údajov.
Pochopenie nadmerného vybavenia
Prepracovanie nastane, keď sa model príliš dobre naučí podrobnosti v rámci trénovacej množiny údajov, čo spôsobí, že model trpí, keď sa robia predpovede na vonkajších údajoch. K tomu môže dôjsť, keď sa model naučí nielen vlastnosti súboru údajov, ale naučí sa aj náhodné fluktuácie resp hluk v rámci súboru údajov, pričom sa kladie dôraz na tieto náhodné/nedôležité udalosti.
Pri použití nelineárnych modelov je pravdepodobnejšie, že dôjde k preťaženiu, pretože sú flexibilnejšie pri učení sa dátových funkcií. Algoritmy neparametrického strojového učenia majú často rôzne parametre a techniky, ktoré možno použiť na obmedzenie citlivosti modelu na údaje, a tým znížiť nadmerné prispôsobenie. Ako príklad, modely rozhodovacích stromov sú veľmi citlivé na premontovanie, ale na náhodné odstránenie niektorých detailov, ktoré sa model naučil, možno použiť techniku nazývanú prerezávanie.
Ak by ste vykreslili predpovede modelu na osiach X a Y, mali by ste predikčnú líniu, ktorá sa kľukatí tam a späť, čo odráža skutočnosť, že model sa príliš snažil umiestniť všetky body v súbore údajov do jeho vysvetlenie.
Ovládanie nadmerného vybavenia
Keď trénujeme model, v ideálnom prípade chceme, aby model nerobil žiadne chyby. Keď sa výkon modelu približuje k vytváraniu správnych predpovedí na všetkých dátových bodoch v trénovacej množine údajov, zhoda sa zlepšuje. Model, ktorý dobre sedí, je schopný vysvetliť takmer celý súbor trénovacích údajov bez toho, aby sa premontoval.
Ako model trénuje, jeho výkon sa časom zlepšuje. Chybovosť modelu sa bude s pribúdajúcim časom tréningu znižovať, ale klesá len do určitého bodu. Bod, v ktorom výkon modelu na testovacej súprave opäť začína rásť, je zvyčajne bod, v ktorom dochádza k nadmernej montáži. Aby sa model čo najlepšie prispôsobil, chceme zastaviť trénovanie modelu v bode najnižšej straty na trénovacej sade, skôr než sa chyba začne opäť zvyšovať. Optimálny bod zastavenia sa dá zistiť pomocou grafu výkonu modelu počas tréningového času a zastavením tréningu, keď je strata najnižšia. Jedno riziko pri tejto metóde kontroly nadmerného vybavenia však spočíva v tom, že špecifikácia koncového bodu pre školenie na základe výkonu testu znamená, že údaje o teste budú do istej miery zahrnuté do tréningového postupu a stratia svoj status čisto „nedotknutých“ údajov.
Existuje niekoľko rôznych spôsobov, ako bojovať proti nadmernému vybaveniu. Jedným zo spôsobov, ako obmedziť nadmerné vybavenie, je použiť taktiku prevzorkovania, ktorá funguje na základe odhadu presnosti modelu. Môžete tiež použiť a validácia súbor údajov ako doplnok k testovaciemu súboru a namiesto testovacieho súboru údajov vyneste do grafu presnosť tréningu oproti súboru overovania. Váš testovací súbor údajov tak zostane neviditeľný. Obľúbenou metódou prevzorkovania je krížová validácia K-násobkov. Táto technika vám umožňuje rozdeliť vaše údaje do podmnožín, na ktorých je model trénovaný, a potom sa analyzuje výkonnosť modelu na podskupinách, aby sa odhadlo, ako bude model fungovať na vonkajších údajoch.
Využitie krížovej validácie je jedným z najlepších spôsobov, ako odhadnúť presnosť modelu na neviditeľných údajoch, a v kombinácii s overovacím súborom údajov je často možné obmedziť nadmerné prispôsobenie na minimum.










