
AI 101
Čo je redukcia rozmerov?
Čo je redukcia rozmerov?
Zníženie rozmerov je proces používaný na redukciu rozmerov množiny údajov, pričom preberá mnoho funkcií a predstavuje ich ako menej funkcií. Napríklad redukcia rozmerov by sa mohla použiť na redukciu súboru údajov dvadsiatich prvkov na niekoľko prvkov. Zmenšenie rozmerov sa bežne používa v učenie bez dozoru úloh na automatické vytváranie tried z mnohých funkcií. Aby sme lepšie pochopili prečo a ako sa používa redukcia rozmerov, pozrieme sa na problémy spojené s vysokorozmernými dátami a najpopulárnejšími metódami znižovania rozmerov.
Viac rozmerov vedie k nadmernej montáži
Rozmernosť sa týka počtu prvkov/stĺpcov v rámci množiny údajov.
Často sa predpokladá, že pri strojovom učení je lepších viac funkcií, pretože vytvára presnejší model. Viac funkcií však nemusí nevyhnutne znamenať lepší model.
Funkcie množiny údajov sa môžu značne líšiť, pokiaľ ide o ich užitočnosť pre model, pričom mnohé funkcie sú málo dôležité. Okrem toho, čím viac funkcií súbor údajov obsahuje, tým viac vzoriek je potrebných na zabezpečenie toho, aby boli rôzne kombinácie funkcií v údajoch dobre zastúpené. Preto sa počet vzoriek zvyšuje úmerne s počtom funkcií. Viac vzoriek a viac funkcií znamená, že model musí byť zložitejší, a keď sa modely stávajú zložitejšími, stávajú sa citlivejšími na nadmerné prispôsobenie. Model sa príliš dobre učí vzory v trénovacích údajoch a nedokáže zovšeobecniť na mimo vzorové údaje.
Zníženie rozmerov súboru údajov má niekoľko výhod. Ako už bolo spomenuté, jednoduchšie modely sú menej náchylné na nadmernú montáž, pretože model musí vytvárať menej predpokladov o tom, ako spolu funkcie súvisia. Navyše, menej rozmerov znamená, že na trénovanie algoritmov je potrebný menší výpočtový výkon. Podobne je potrebný menší úložný priestor pre množinu údajov, ktorá má menšiu dimenziu. Zníženie rozmerov množiny údajov vám tiež umožní používať algoritmy, ktoré nie sú vhodné pre množiny údajov s mnohými funkciami.
Bežné metódy znižovania rozmerov
Zníženie rozmerov môže byť vykonané výberom prvkov alebo konštrukčným riešením prvkov. Výber funkcií je miesto, kde inžinier identifikuje najrelevantnejšie vlastnosti súboru údajov funkcia inžinierstva je proces vytvárania nových funkcií kombinovaním alebo transformáciou iných funkcií.
Výber funkcií a inžinierstvo možno vykonať programovo alebo manuálne. Pri manuálnom výbere a navrhovaní prvkov je typická vizualizácia údajov na zistenie korelácií medzi funkciami a triedami. Uskutočnenie redukcie dimenzionality týmto spôsobom môže byť dosť časovo náročné, a preto niektoré z najbežnejších spôsobov redukcie dimenzionality zahŕňajú použitie algoritmov dostupných v knižniciach, ako je Scikit-learn pre Python. Tieto bežné algoritmy znižovania rozmerov zahŕňajú: analýzu hlavných komponentov (PCA), singulárny rozklad hodnoty (SVD) a lineárnu diskriminačnú analýzu (LDA).
Algoritmy používané pri znižovaní rozmerov pre úlohy učenia bez dozoru sú zvyčajne PCA a SVD, zatiaľ čo algoritmy využívané na znižovanie rozmerov učenia pod dohľadom sú zvyčajne LDA a PCA. V prípade modelov učenia pod dohľadom sa novo vygenerované funkcie vkladajú do klasifikátora strojového učenia. Berte na vedomie, že tu opísané použitia sú len všeobecné prípady použitia a nie jediné podmienky, v ktorých sa tieto techniky môžu použiť. Algoritmy redukcie rozmerov opísané vyššie sú jednoducho štatistické metódy a používajú sa mimo modelov strojového učenia.
Analýza hlavných komponentov

Foto: Matica s identifikovanými hlavnými komponentmi
Analýza hlavných komponentov (PCA) je štatistická metóda, ktorá analyzuje charakteristiky/funkcie súboru údajov a sumarizuje vlastnosti, ktoré sú najvplyvnejšie. Vlastnosti množiny údajov sú skombinované do reprezentácií, ktoré zachovávajú väčšinu charakteristík údajov, ale sú rozptýlené v menšom počte dimenzií. Môžete si to predstaviť ako „stlačenie“ údajov z reprezentácie vyššej dimenzie na reprezentáciu s niekoľkými dimenziami.
Ako príklad situácie, v ktorej môže byť PCA užitočná, zamyslite sa nad rôznymi spôsobmi, ktorými by sa dalo opísať víno. Aj keď je možné opísať víno pomocou mnohých vysoko špecifických vlastností, ako sú úrovne CO2, úrovne prevzdušnenia atď., takéto špecifické vlastnosti môžu byť pri pokuse o identifikáciu konkrétneho typu vína relatívne zbytočné. Namiesto toho by bolo rozumnejšie identifikovať typ na základe všeobecnejších znakov, ako je chuť, farba a vek. PCA možno použiť na kombinovanie špecifickejších funkcií a vytváranie funkcií, ktoré sú všeobecnejšie, užitočnejšie a s menšou pravdepodobnosťou spôsobia nadmerné vybavenie.
PCA sa vykonáva určením, ako sa vstupné znaky líšia od priemeru vzhľadom na seba navzájom, pričom sa určí, či medzi znakmi existujú nejaké vzťahy. Na tento účel sa vytvorí kovariantná matica, ktorá vytvorí maticu zloženú z kovariancií vzhľadom na možné páry vlastností súboru údajov. Toto sa používa na určenie korelácií medzi premennými, pričom negatívna kovariancia indikuje inverznú koreláciu a pozitívna korelácia indikuje pozitívnu koreláciu.
Hlavné (najvplyvnejšie) komponenty súboru údajov sa vytvárajú vytváraním lineárnych kombinácií počiatočných premenných, čo sa robí pomocou konceptov lineárnej algebry tzv. vlastné hodnoty a vlastné vektory. Kombinácie sú vytvorené tak, že hlavné zložky nie sú navzájom korelované. Väčšina informácií obsiahnutých v počiatočných premenných je komprimovaná do niekoľkých prvých hlavných komponentov, čo znamená, že boli vytvorené nové funkcie (hlavné komponenty), ktoré obsahujú informácie z pôvodného súboru údajov v menšom rozmerovom priestore.
Dekompozícia singulárnej hodnoty
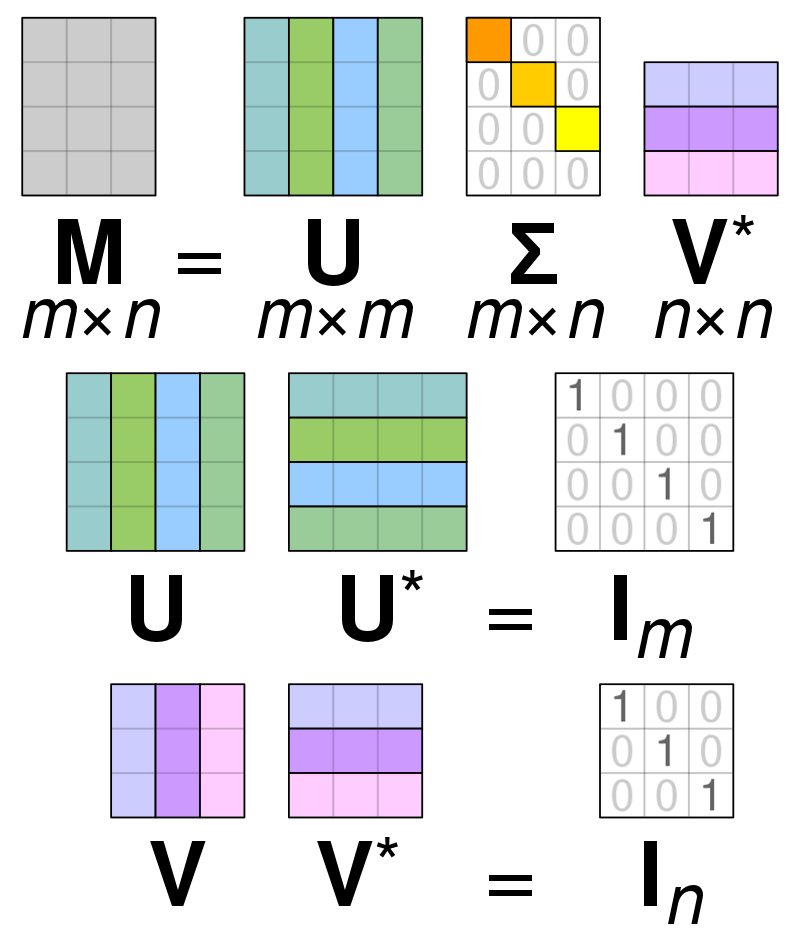
Foto: Autor Cmglee – Vlastné dielo, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=67853297
Dekompozícia singulárnej hodnoty (SVD) is používa sa na zjednodušenie hodnôt v matici, zredukuje maticu na jej jednotlivé časti a zjednoduší výpočty s touto maticou. SVD je možné použiť pre matice reálnych hodnôt aj pre komplexné matice, ale na účely tohto vysvetlenia preskúma, ako rozložiť maticu reálnych hodnôt.
Predpokladajme, že máme maticu zloženú z údajov s reálnou hodnotou a naším cieľom je znížiť počet stĺpcov/prvkov v rámci matice, podobne ako cieľ PCA. Podobne ako PCA, aj SVD komprimuje rozmer matice, pričom zachová čo najväčšiu variabilitu matice. Ak chceme pracovať s maticou A, môžeme maticu A reprezentovať ako tri ďalšie matice nazývané U, D a V. Matica A sa skladá z pôvodných x * y prvkov, zatiaľ čo matica U sa skladá z prvkov X * X (je ortogonálna matica). Matica V je iná ortogonálna matica obsahujúca y * y prvkov. Matica D obsahuje prvky x * y a je to diagonálna matica.
Aby sme rozložili hodnoty pre maticu A, musíme previesť pôvodné singulárne hodnoty matice na diagonálne hodnoty nájdené v novej matici. Pri práci s ortogonálnymi maticami sa ich vlastnosti nemenia, ak sú vynásobené inými číslami. Preto môžeme aproximovať maticu A využitím tejto vlastnosti. Keď vynásobíme ortogonálne matice spolu s transpozíciou matice V, výsledkom je ekvivalentná matica k našej pôvodnej A.
Keď sa matica a rozloží na matice U, D a V, tieto obsahujú údaje nachádzajúce sa v matici A. Avšak stĺpce úplne vľavo budú obsahovať väčšinu údajov. Môžeme vziať len týchto prvých pár stĺpcov a mať reprezentáciu matice A, ktorá má oveľa menej rozmerov a väčšinu údajov v rámci A.
Lineárna diskriminačná analýza

Vľavo: Matrix pred LDA, Vpravo: Os po LDA, teraz oddeliteľné
Lineárna diskriminačná analýza (LDA) je proces, ktorý preberá údaje z viacrozmerného grafu a premietne ho do lineárneho grafu. Môžete si to predstaviť tak, že si predstavíte dvojrozmerný graf vyplnený dátovými bodmi patriacimi do dvoch rôznych tried. Predpokladajme, že body sú roztrúsené okolo, takže nie je možné nakresliť čiaru, ktorá by tieto dve rôzne triedy úhľadne oddelila. Na zvládnutie tejto situácie je možné body nájdené v 2D grafe zredukovať na 1D graf (čiaru). Tento riadok bude mať rozmiestnené všetky dátové body a dúfajme, že sa dá rozdeliť na dve časti, ktoré predstavujú najlepšie možné oddelenie dát.
Pri vykonávaní LDA existujú dva hlavné ciele. Prvým cieľom je minimalizovať rozptyl pre triedy, zatiaľ čo druhým cieľom je maximalizovať vzdialenosť medzi priemermi týchto dvoch tried. Tieto ciele sa dosiahnu vytvorením novej osi, ktorá bude existovať v 2D grafe. Novovytvorená os slúži na oddelenie týchto dvoch tried na základe vyššie opísaných cieľov. Po vytvorení osi sa body nájdené v 2D grafe umiestnia pozdĺž osi.
Na presun pôvodných bodov do novej polohy pozdĺž novej osi sú potrebné tri kroky. V prvom kroku sa na výpočet separability tried použije vzdialenosť medzi jednotlivými triedami (medzitriedny rozptyl). V druhom kroku sa vypočíta rozptyl v rámci rôznych tried, pričom sa určí vzdialenosť medzi vzorkou a priemerom pre príslušnú triedu. V poslednom kroku sa vytvorí priestor nižšej dimenzie, ktorý maximalizuje rozptyl medzi triedami.
Technika LDA dosahuje najlepšie výsledky, keď sú prostriedky pre cieľové triedy ďaleko od seba. LDA nemôže efektívne oddeliť triedy lineárnou osou, ak sa prostriedky pre distribúcie prekrývajú.










