
Kąt Andersona
HunyuanCustom wprowadza deepfake’i z pojedynczym obrazem wideo, z dźwiękiem i synchronizacją ruchu warg
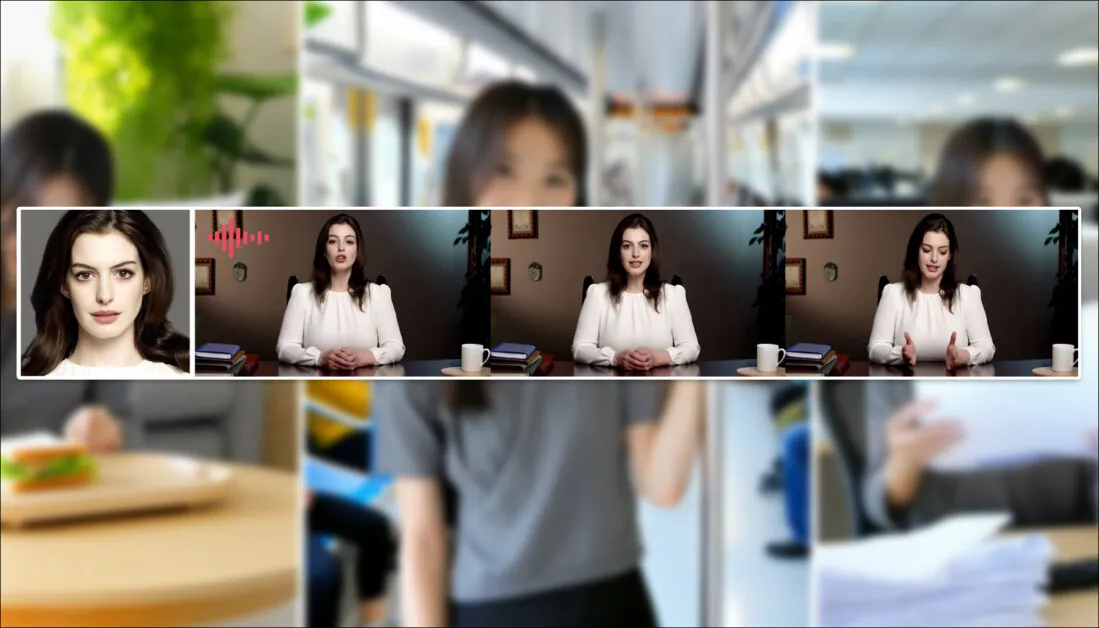
W tym artykule omówiono nową wersję multimodalnego modelu świata wideo Hunyuan o nazwie „HunyuanCustom”. Szeroki zakres tematyczny nowego artykułu, w połączeniu z kilkoma problemami w wielu przykładowych filmach udostępnionych na stronie strona projektu*, ogranicza nas do bardziej ogólnego niż zwykle zakresu materiału oraz do ograniczonej reprodukcji ogromnej ilości materiału wideo dołączonego do tej publikacji (ponieważ wiele z filmów wymaga znacznej ponownej edycji i obróbki w celu poprawy czytelności układu).
Należy również pamiętać, że w artykule system generatywny Kling oparty na API jest nazywany „Kelingiem”. Dla jasności w całym tekście używam określenia „Kling”.
Tencent jest w trakcie wydawania nowej wersji swojego Model wideo Hunyuan, pod tytulem Hunyuan Niestandardowe. Wygląda na to, że nowe wydanie jest w stanie to zrobić Modele Hunyuana LoRA zbędne, umożliwiając użytkownikowi tworzenie personalizowanych filmów w stylu „deepfake” za pomocą pojedynczy obraz:
Kliknij aby zagrać. Podpowiedź: „Mężczyzna słucha muzyki i gotuje makaron ze ślimakami w kuchni”. Nowa metoda jest porównywalna zarówno z metodami typu close-source, jak i open-source, w tym z metodą Kling, która jest poważnym konkurentem w tej dziedzinie. Źródło: https://hunyuancustom.github.io/ (ostrzeżenie: witryna intensywnie wykorzystująca procesor/pamięć!)
W lewej kolumnie powyższego filmu widzimy pojedynczy obraz źródłowy dostarczony do HunyuanCustom, a następnie interpretację komunikatu przez nowy system w drugiej kolumnie, obok. Pozostałe kolumny pokazują wyniki z różnych systemów zastrzeżonych i FOSS: Kling; rozumiem; Pika; Hailuo; i bladyOparte SkyReels-A2.
Na poniższym filmie widzimy rendery trzech scenariuszy kluczowych dla tego wydania: odpowiednio, osoba + obiekt; emulacja pojedynczego znakuOraz wirtualne przymierzanie (osoba + ubranie):
Kliknij, aby odtworzyć. Trzy przykłady zredagowane z materiału na stronie wspierającej Hunyuan Video.
Na podstawie tych przykładów możemy zauważyć kilka rzeczy, głównie związanych z systemem opartym na obraz z pojedynczego źródła, zamiast wielu obrazów tego samego obiektu.
W pierwszym klipie mężczyzna zasadniczo nadal stoi twarzą do kamery. Pochyla głowę w dół i na bok, nie obracając się o więcej niż 20-25 stopni, ale przy nachyleniu większym niż to, system musiałby zacząć zgadywać, jak wygląda z profilu. To trudne, prawdopodobnie niemożliwe do dokładnego oszacowania na podstawie pojedynczego obrazu frontalnego.
W drugim przykładzie widzimy, że mała dziewczynka jest uśmiechając w renderowanym filmie, tak jak na pojedynczym, statycznym obrazie źródłowym. Ponownie, mając ten pojedynczy obraz jako punkt odniesienia, HunyuanCustom musiałby dokonać stosunkowo mało precyzyjnego przypuszczenia, jak wygląda jej „twarz w spoczynku”. Co więcej, jej twarz nie odchyla się od pozycji zwróconej w stronę kamery bardziej niż w poprzednim przykładzie („mężczyzna jedzący chipsy”).
W ostatnim przykładzie widzimy, że ponieważ materiał źródłowy – kobieta i ubrania, które ma założyć – nie są kompletnymi obrazami, render przyciął scenariusz tak, aby do niego pasował – co jest w zasadzie całkiem dobrym rozwiązaniem problemu z danymi!
Chodzi o to, że chociaż nowy system może obsługiwać wiele obrazów (takich jak osoba + chipsylub osoba + ubrania), najwyraźniej nie pozwala na wiele kątów ani alternatywne widoki pojedynczego znaku, tak aby można było uwzględnić różne wyrażenia lub nietypowe kąty. W tym zakresie system może mieć trudności z zastąpieniem rosnącego ekosystemu modeli LoRA, które mają wyrosło wokół HunyuanVideo od momentu jego wydania w grudniu ubiegłego roku, ponieważ mogą one pomóc HunyuanVideo w tworzeniu spójnych postaci z dowolnego kąta i z dowolnym wyrazem twarzy uwzględnionym w zestawie danych treningowych (typowo 20–60 obrazów).
Przewodowy dla dźwięku
W przypadku dźwięku HunyuanCustom wykorzystuje Synchronizacja opóźniona system (niesławny z trudnościami w konfiguracji i uzyskiwaniu dobrych wyników dla hobbystów) służący do uzyskiwania ruchów ust dopasowanych do dźwięku i tekstu dostarczanych przez użytkownika:
Zawiera dźwięk. Kliknij, aby odtworzyć. Różne przykłady synchronizacji ruchu ust z treścią pochodzą z witryny uzupełniającej HunyuanCustom, zmontowane razem.
W chwili pisania tego tekstu nie ma przykładów w języku angielskim, ale te wydają się być całkiem dobre – tym bardziej, że metoda ich tworzenia jest łatwa do zainstalowania i dostępna.
Edycja istniejącego wideo
Nowy system oferuje, jak się wydaje, bardzo imponujące rezultaty w edycji wideo-do-wideo (V2V lub Vid2Vid), w której segment istniejącego (rzeczywistego) wideo jest maskowany i inteligentnie zastępowany przez obiekt podany w pojedynczym obrazie referencyjnym. Poniżej znajduje się przykład ze strony materiałów uzupełniających:
Kliknij aby zagrać. Celem jest tylko obiekt centralny, ale to, co znajduje się wokół niego, również zostaje zmienione podczas przebiegu HunyuanCustom vid2vid.
Jak widać, zgodnie ze standardem w scenariuszu vid2vid, cały film jest w pewnym stopniu zmieniany przez proces, choć najbardziej zmieniany w docelowym regionie, tj. pluszowej zabawce. Przypuszczalnie rurociągi mogłyby zostać opracowane w celu tworzenia takich transformacji pod mata śmieciowa podejście, które pozostawia większość zawartości wideo identyczną z oryginałem. To właśnie robi Adobe Firefly pod maską i robi to całkiem dobrze – ale jest to niedostatecznie zbadany proces w generatywnej scenie FOSS.
Mimo to większość podanych alternatywnych przykładów lepiej radzi sobie z tymi integracjami, co możemy zobaczyć w poniższej kompilacji:
Kliknij aby zagrać. Różne przykłady wtrąconej treści przy użyciu vid2vid w HunyuanCustom, świadczące o szczególnym szacunku dla nieskoncentrowanego materiału.
Nowy początek?
Inicjatywa ta jest rozwinięciem Projekt wideo Hunyuan, a nie radykalne odejście od tego nurtu rozwoju. Ulepszenia projektu wprowadzane są jako dyskretne wstawki architektoniczne, a nie radykalne zmiany strukturalne, co ma na celu umożliwienie modelowi zachowania wierności tożsamości w różnych klatkach bez polegania na przedmiotowy strojenie, jak w przypadku LoRA lub podejść opartych na inwersji tekstu.
Zatem, żeby było jasne, HunyuanCustom nie jest trenowany od podstaw, lecz stanowi dopracowaną wersję modelu bazowego HunyuanVideo z grudnia 2024 r.
Ci, którzy opracowali HunyuanVideo LoRAs, mogą się zastanawiać, czy nadal będą pracować z tą nową edycją, czy też będą musieli wynaleźć koło LoRA na nowo jeszcze raz jeśli będą chcieli mieć więcej możliwości personalizacji niż te zawarte w nowej wersji.
Ogólnie rzecz biorąc, mocno dostrojona wersja modelu hiperskalowego zmienia wagi modeli na tyle, że karty LoRA stworzone dla starszego modelu nie będą działać prawidłowo lub w ogóle nie będą działać z nowo udoskonalonym modelem.
Czasami jednak popularność dobrego utworu może podważyć jego pochodzenie: jednym z przykładów dobrego utworu, który stał się skutecznym utworem, jest widelec, z dedykowanym ekosystemem i własnymi zwolennikami, jest Dyfuzja kucyków strojenie Stabilna dyfuzja XL (SDXL). Pony ma obecnie 592,000 XNUMX+ pobrań na ciągle się zmienia Domena CivitAI, z szeroką gamą LoRA, które wykorzystują Pony (a nie SDXL) jako model bazowy i wymagają Pony w czasie wnioskowania.
Zwalnianie
strona projektu dla nowy papier (który nosi tytuł HunyuanCustom: Multimodalna architektura sterowana dla niestandardowej generacji wideo) zawiera linki do Witryna GitHub który, gdy to piszę, właśnie stał się funkcjonalny i wydaje się zawierać cały kod oraz niezbędne wagi dla lokalnej implementacji, wraz z proponowanym harmonogramem (gdzie jedyną ważną rzeczą jest integracja z ComfyUI).
W chwili pisania tego tekstu projekt Obecność przytulania twarzy nadal jest 404. Istnieje jednak Wersja oparta na API gdzie można zobaczyć demonstrację systemu, o ile można podać kod skanujący WeChat.
Rzadko widziałem tak rozbudowane i rozbudowane wykorzystanie tak szerokiej gamy projektów w jednym pakiecie, jak to widać w HunyuanCustom – i przypuszczalnie niektóre licencje w każdym przypadku wymagałyby pełnego udostępnienia.
Na stronie GitHub zapowiedziano dwa modele: wersję o rozdzielczości 720px i rozdzielczości 1280px, która wymaga 8 GB pamięci GPU (szczytowej), oraz wersję o rozdzielczości 512px i rozdzielczości 896px, która wymaga 60 GB pamięci GPU (szczytowej).
Repozytorium podaje „Minimalna wymagana pamięć GPU wynosi 24 GB dla rozdzielczości 720px1280px129f, ale jest to bardzo wolne… Zalecamy użycie GPU z pamięcią 80 GB w celu uzyskania lepszej jakości generowania” – i powtarza, że system został dotychczas przetestowany wyłącznie na Linuksie.
Wcześniejszy model Hunyuan Video, od czasu oficjalnej premiery, był skwantowany został sprowadzony do rozmiarów umożliwiających jego uruchomienie na pamięci VRAM mniejszej niż 24 GB. Można więc założyć, że społeczność dostosuje nowy model do bardziej przyjaznych użytkownikowi form i że szybko zostanie on dostosowany do użytku w systemach Windows.
Ze względu na ograniczenia czasowe i przytłaczającą ilość informacji towarzyszących temu wydaniu, możemy przyjrzeć się mu jedynie szerzej, a nie dogłębnie. Niemniej jednak, przyjrzyjmy się bliżej HunyuanCustom.
Spojrzenie na papier
Przepływ danych dla HunyuanCustom, najwyraźniej zgodny z RODO framework, obejmuje zarówno syntetyzowane, jak i otwarte zbiory danych wideo, w tym OtwórzHumanVid, z ośmioma głównymi kategoriami reprezentowanymi: ludzie, zwierzęta, Rośliny, krajobrazy, pojazdów, obiekty, architektura, anime.

W dokumencie prasowym zamieszczono przegląd zróżnicowanych pakietów składowych procesu tworzenia danych HunyuanCustom. Źródło: https://arxiv.org/pdf/2505.04512
Początkowe filtrowanie zaczyna się od PySceneDetect, który dzieli filmy na pojedyncze klipy. TekstBPN-Plus-Plus służy następnie do usuwania filmów zawierających nadmierną ilość tekstu na ekranie, napisów, znaków wodnych i logo.
Aby rozwiązać niespójności w rozdzielczości i czasie trwania, klipy są standaryzowane do długości pięciu sekund i zmieniane na 512 lub 720 pikseli na krótszym boku. Filtrowanie estetyczne jest obsługiwane za pomocą Koala-36M, przy czym dla niestandardowego zestawu danych opracowanego przez badaczy z nowego artykułu zastosowano niestandardowy próg 0.06.
Proces ekstrakcji podmiotu łączy w sobie: Qwen7B Duży Model Językowy (LLM) YOLO11X ramy rozpoznawania obiektów i popularne WglądTwarz architektury, w celu identyfikacji i weryfikacji tożsamości człowieka.
W przypadku obiektów innych niż ludzie, QwenVL oraz Uziemiony SAM 2 służą do wyodrębniania odpowiednich pól ograniczających, które są odrzucane, jeśli są zbyt małe.

Przykłady segmentacji semantycznej z wykorzystaniem Grounded SAM 2 w projekcie Hunyuan Control. Źródło: https://github.com/IDEA-Research/Grounded-SAM-2
Ekstrakcja wieloprzedmiotowa wykorzystuje Florencja2 do adnotacji pola ograniczającego i Grounded SAM 2 do segmentacji, a następnie klasteryzacji i segmentacji czasowej klatek treningowych.
Przetworzone klipy są dodatkowo wzbogacane poprzez adnotacje, które są wykonywane przy użyciu zastrzeżonego systemu etykietowania strukturalnego opracowanego przez zespół Hunyuan. System ten dostarcza warstwowych metadanych, takich jak opisy i wskazówki dotyczące ruchu kamery.
Powiększanie maski w celu zmniejszenia liczby pól ograniczających zastosowano w trakcie szkolenia strategie obejmujące konwersję na pola ograniczające nadmierne dopasowanie i zapewnić, że model dopasuje się do różnych kształtów obiektów.
Dane audio synchronizowano za pomocą wspomnianej wcześniej technologii LatentSync, a klipy były odrzucane, jeśli wyniki synchronizacji spadały poniżej minimalnego progu.
Ramowa ocena jakości obrazu w trybie niewidomym HiperIQA został użyty do wykluczenia filmów z oceną poniżej 40 (według specjalnej skali HyperIQA). Prawidłowe ścieżki audio zostały następnie przetworzone za pomocą Szept w celu wyodrębnienia cech dla zadań dalszych.
Autorzy włączają LLaVA model asystenta językowego podczas fazy adnotacji i podkreślają centralną pozycję, jaką te ramy zajmują w HunyuanCustom. LLaVA jest używany do generowania podpisów obrazów i pomaga w dopasowywaniu treści wizualnej do podpowiedzi tekstowych, wspierając budowę spójnego sygnału szkoleniowego w różnych modalnościach:

Framework HunyuanCustom obsługuje generowanie materiałów wideo zgodnych z tożsamością użytkownika, w oparciu o dane wejściowe w postaci tekstu, obrazu, dźwięku i wideo.
Dzięki wykorzystaniu możliwości LLaVA w zakresie dopasowywania wizji do języka, proces przetwarzania zyskuje dodatkową warstwę spójności semantycznej między elementami wizualnymi a ich opisami tekstowymi – co jest szczególnie cenne w scenariuszach obejmujących wiele tematów lub złożonych scen.
Niestandardowe wideo
Aby umożliwić generowanie wideo na podstawie obrazu referencyjnego i monitu, stworzono dwa moduły skupione wokół LLaVA. Najpierw dostosowano strukturę wejściową HunyuanVideo, aby mogła akceptować obraz wraz z tekstem.
Polegało to na sformatowaniu monitu w taki sposób, aby osadzić obraz bezpośrednio lub oznaczyć go krótkim opisem tożsamości. Token separatora został użyty, aby zapobiec przytłoczeniu zawartości monitu przez osadzanie obrazu.
Ponieważ koder wizualny LLaVA ma tendencję do kompresowania lub odrzucania drobnych szczegółów przestrzennych podczas wyrównywania cech obrazu i tekstu (szczególnie podczas tłumaczenia pojedynczego obrazu referencyjnego na ogólne osadzenie semantyczne), moduł ulepszania tożsamości został włączony. Ponieważ niemal wszystkie modele utajonej dyfuzji wideo mają pewne trudności z utrzymaniem tożsamości bez LoRA, nawet w pięciosekundowym klipie, wydajność tego modułu w testach społecznościowych może okazać się znacząca.
W każdym przypadku obraz referencyjny jest następnie zmieniany pod względem rozmiaru i kodowany przy użyciu przyczynowego 3D-VAE z oryginalnego modelu HunyuanVideo i jego utajony wstawiany do wideo ukrytego w osi czasowej, z przesunięciem przestrzennym stosowanym w celu zapobieżenia bezpośredniej reprodukcji obrazu na wyjściu, przy jednoczesnym zachowaniu kontroli nad generacją.
Model został wytrenowany przy użyciu Dopasowanie przepływu, z próbkami szumów pobranymi z logit-normal dystrybucja – a sieć została wytrenowana, aby odzyskać prawidłowe wideo z tych zaszumionych ukrytych danych. LLaVA i generator wideo zostały dostrojone razem, aby obraz i monit mogły płynniej kierować wyjściem i zachować spójność tożsamości podmiotu.
W przypadku podpowiedzi wielotematycznych każda para obraz-tekst została osadzona osobno i przypisano jej odrębną pozycję czasową, co umożliwiło rozróżnianie tożsamości i wspomagało generowanie scen obejmujących wielokrotność podmioty wchodzące w interakcje.
Dźwięk i wizja
HunyuanCustom tworzy warunki do generowania dźwięku/mowy, wykorzystując zarówno dźwięk wprowadzany przez użytkownika, jak i tekstowy monit, umożliwiając postaciom mówienie w scenach odzwierciedlających opisywane otoczenie.
Aby to wesprzeć, moduł AudioNet z rozplątaną tożsamością wprowadza funkcje audio bez zakłócania sygnałów tożsamości osadzonych z obrazu referencyjnego i monitu. Funkcje te są wyrównane z osią czasu skompresowanego wideo, podzielone na segmenty na poziomie klatki i wstrzykiwane za pomocą przestrzennego uwaga krzyżowa mechanizm, który utrzymuje każdą klatkę w izolacji, zachowując spójność obiektu i zapobiegając zakłóceniom czasowym.
Drugi moduł wstrzykiwania w czasie zapewnia dokładniejszą kontrolę nad czasem i ruchem, współpracując z AudioNet, mapując cechy audio na określone obszary sekwencji ukrytej i wykorzystując Perceptron wielowarstwowy (MLP) aby je przekształcić w tokenowo przesunięcia ruchu. Dzięki temu gesty i ruchy twarzy mogą podążać za rytmem i naciskiem wypowiedzi mówionej z większą precyzją.
HunyuanCustom pozwala na bezpośrednią edycję tematów w istniejących filmach, zastępując lub wstawiając osoby lub obiekty do sceny bez konieczności ponownego tworzenia całego klipu od podstaw. Dzięki temu jest przydatny do zadań, które obejmują zmianę wyglądu lub ruchu w ukierunkowany sposób.
Kliknij aby zagrać. Kolejny przykład ze strony uzupełniającej.
Aby ułatwić efektywną zamianę tematów w istniejących filmach, nowy system unika wymagającego dużych zasobów podejścia stosowanego w przypadku ostatnio stosowanych metod, takich jak obecnie popularna VACElub te, które łączą całe sekwencje wideo, preferując zamiast tego kompresję wideo referencyjnego przy użyciu wstępnie wytrenowanego przyczynowego 3D-VAE – dopasowując go do wewnętrznych ukrytych danych wideo potoku generacji, a następnie dodając je do siebie. Dzięki temu proces jest stosunkowo lekki, a jednocześnie pozwala zewnętrznej zawartości wideo kierować wyjściem.
Mała sieć neuronowa zajmuje się wyrównaniem między czystym wideo wejściowym a zaszumionymi latentami używanymi w generowaniu. System testuje dwa sposoby wstrzykiwania tych informacji: scalanie dwóch zestawów cech przed ich ponowną kompresją; i dodawanie cech klatka po klatce. Druga metoda działa lepiej, odkryli autorzy, i unika utraty jakości, jednocześnie utrzymując niezmienione obciążenie obliczeniowe.
Dane i testy
W testach wykorzystano następujące metryki: moduł spójności tożsamości w ArcFace'a, który wyodrębnia osadzenia twarzy zarówno z obrazu referencyjnego, jak i z każdej klatki wygenerowanego wideo, a następnie oblicza średnie podobieństwo cosinusowe między nimi; podobieństwo podmiotupoprzez wysyłanie segmentów YOLO11x do Dinozaur 2 dla porównania; KLIPS-B, wyrównanie tekstu i wideo, które mierzy podobieństwo między komunikatem a wygenerowanym wideo; ponownie CLIP-B, aby obliczyć podobieństwo między każdą klatką a sąsiadującymi z nią klatkami i pierwszą klatką, a także spójność czasową; i stopień dynamiczny, zgodnie z definicją Ławka VBench.
Jak wskazano wcześniej, podstawowymi konkurentami zamkniętego kodu źródłowego były Hailuo; Vidu 2.0; Kling (1.6); i Pika. Konkurującymi frameworkami FOSS były VACE i SkyReels-A2.

Ocena wydajności modelu porównująca HunyuanCustom z wiodącymi metodami dostosowywania wideo pod kątem spójności ID (Face-Sim), podobieństwa obiektów (DINO-Sim), wyrównania tekstu i wideo (CLIP-BT), spójności czasowej (Temp-Consis) i intensywności ruchu (DD). Optymalne i suboptymalne wyniki są pokazane odpowiednio pogrubioną i podkreśloną czcionką.
Autorzy wyników piszą:
„Nasz [HunyuanCustom] osiąga najlepszą spójność identyfikacji i obiektów. Osiąga również porównywalne rezultaty pod względem szybkości śledzenia i spójności czasowej. [Hailuo] ma najlepszy wynik w kategorii klipów, ponieważ dobrze radzi sobie z instrukcjami tekstowymi, zachowując jedynie spójność identyfikacji, kosztem spójności obiektów innych niż ludzie (najgorszy model DINO-Sim). Pod względem stopnia dynamiki, [Vidu] i [VACE] wypadają słabo, co może wynikać z niewielkiego rozmiaru modelu”.
Chociaż strona projektu jest przesycona filmami porównawczymi (których układ wydaje się być zaprojektowany bardziej pod kątem estetyki strony niż łatwego porównania), obecnie nie zawiera ona wideo-ekwiwalentu statycznych wyników upchniętych razem w pliku PDF, w odniesieniu do początkowych testów jakościowych. Chociaż zamieszczam je tutaj, zachęcam czytelnika do dokładnego zbadania filmów na stronie projektu, ponieważ dają one lepsze wyobrażenie o wynikach:

Z artykułu, porównanie dostosowywania wideo zorientowanego na obiekty. Chociaż widz powinien (jak zawsze) odwołać się do źródłowego pliku PDF w celu uzyskania lepszej rozdzielczości, filmy na stronie projektu mogą być w tym przypadku bardziej pouczającym źródłem.
Autorzy komentują tutaj:
„Można zauważyć, że [Vidu], [Skyreels A2] i nasza metoda osiągają stosunkowo dobre wyniki w zakresie szybkiego dopasowania i spójności tematu, ale jakość naszego wideo jest lepsza niż w przypadku Vidu i Skyreels, dzięki dobrej wydajności generowania wideo naszego modelu bazowego, tj. [Hunyuanvideo-13B].
„Wśród produktów komercyjnych, mimo że [Kling] oferuje dobrą jakość wideo, pierwsza klatka filmu ma problem z kopiowaniem i wklejaniem, a czasami obiekt porusza się zbyt szybko i [jest rozmazany], co prowadzi do kiepskich wrażeń podczas oglądania”.
Autorzy zauważają ponadto, że Pika słabo radzi sobie z spójnością czasową i wprowadza artefakty w postaci napisów (efekt słabej selekcji danych, gdzie elementy tekstowe w klipach wideo mogą zanieczyszczać podstawowe koncepcje).
Hailuo utrzymuje tożsamość twarzy, twierdzą, ale nie zachowuje spójności całego ciała. Spośród metod open source, VACE, jak twierdzą badacze, nie jest w stanie utrzymać spójności tożsamości, podczas gdy twierdzą, że HunyuanCustom produkuje filmy z silnym zachowaniem tożsamości, zachowując jednocześnie jakość i różnorodność.
Następnie przeprowadzono testy dla personalizacja wideo obejmująca wiele tematów, przeciwko tym samym kandydatom. Podobnie jak w poprzednim przykładzie, spłaszczone wyniki PDF nie są odpowiednikami drukowanymi filmów dostępnych na stronie projektu, ale są unikalne wśród prezentowanych wyników:

Porównania przy użyciu wielotematycznych dostosowań wideo. Aby uzyskać więcej szczegółów i rozdzielczości, zobacz PDF.
Artykuł stwierdza:
'[Pika] może generować określone podmioty, ale wykazuje niestabilność w klatkach wideo, z przypadkami zniknięcia mężczyzny w jednym scenariuszu i kobiety, która nie otwiera drzwi zgodnie z poleceniem. [Vidu] i [VACE] częściowo uchwycą ludzką tożsamość, ale stracą istotne szczegóły obiektów nieludzkich, co wskazuje na ograniczenie w reprezentowaniu podmiotów nieludzkich.
'[SkyReels A2] charakteryzuje się poważną niestabilnością klatek, zauważalnymi zmianami w procesorach i licznymi artefaktami w odpowiednich scenariuszach.
„Nasz HunyuanCustom z kolei skutecznie uchwyca tożsamość zarówno ludzi, jak i zwierząt, generuje filmy zgodne z podanymi wskazówkami, a także utrzymuje wysoką jakość obrazu i stabilność”.
Kolejnym eksperymentem była „wirtualna reklama z udziałem człowieka”, w której zadaniem frameworków było zintegrowanie produktu z osobą:

Przykłady neuronowego „umieszczania produktu” z rundy testów jakościowych. Więcej szczegółów i rozwiązań można znaleźć w pliku PDF.
W tej rundzie autorzy stwierdzają:
[Wyniki] pokazują, że HunyuanCustom skutecznie zachowuje tożsamość człowieka, jednocześnie zachowując szczegóły produktu docelowego, w tym znajdujący się na nim tekst.
„Co więcej, interakcja między człowiekiem a produktem wydaje się naturalna, a film ściśle odpowiada zadaniu, co podkreśla duży potencjał HunyuanCustom w zakresie tworzenia filmów reklamowych”.
Jednym z obszarów, w którym wyniki uzyskane za pomocą wideo byłyby bardzo przydatne, jest jakościowa runda personalizacji tematu na podstawie dźwięku, w której postać wypowiada odpowiedni dźwięk na podstawie opisanej za pomocą tekstu sceny i postawy.

Podano częściowe wyniki dla rundy audio – choć w tym przypadku lepsze mogłyby być wyniki wideo. Tutaj odtworzono tylko górną połowę rysunku PDF, ponieważ jest on duży i trudny do umieszczenia w tym artykule. Aby uzyskać lepsze szczegóły i rozdzielczość, zapoznaj się ze źródłowym PDF.
Autorzy twierdzą:
'Poprzednie metody animacji człowieka oparte na dźwięku wprowadzały obraz człowieka i dźwięk, przy czym postawa człowieka, ubiór i otoczenie pozostawały spójne z danym obrazem i nie mogły generować filmów z innymi gestami i otoczeniem, co może [ograniczyć] ich zastosowanie.
„…[Nasz] HunyuanCustom umożliwia personalizację postaci za pomocą dźwięku, w której postać wypowiada odpowiedni dźwięk w opisanej tekstem scenie i postawie, co pozwala na bardziej elastyczną i kontrolowaną animację postaci za pomocą dźwięku”.
Dalsze testy (szczegóły w pliku PDF) obejmowały rundę testów nowego systemu, w której sprawdzano zgodność z systemami VACE i Kling 1.6 pod kątem zastępowania obiektów w nagraniach wideo:

Testowanie zastępowania tematu w trybie wideo-wideo. Aby uzyskać więcej szczegółów i rozdzielczości, zapoznaj się ze źródłowym plikiem PDF.
Ostatnie testy przedstawione w nowej pracy, zdaniem badaczy, są następujące:
'VACE cierpi na artefakty graniczne z powodu ścisłego przestrzegania masek wejściowych, co skutkuje nienaturalnymi kształtami obiektów i zakłóconą ciągłością ruchu. [Kling] z kolei wykazuje efekt kopiuj-wklej, gdzie obiekty są bezpośrednio nakładane na wideo, co prowadzi do słabej integracji z tłem.
„Dla porównania HunyuanCustom skutecznie unika artefaktów granicznych, zapewnia płynną integrację z tłem wideo i zachowuje silne cechy identyfikacyjne, co dowodzi jego lepszej wydajności w zadaniach związanych z edycją wideo”.
Podsumowanie
To fascynująca publikacja, przede wszystkim dlatego, że porusza kwestię, na którą ostatnio coraz częściej narzekają niezadowoleni hobbyści – brak synchronizacji ruchu warg. Dzięki temu zwiększony realizm, jaki zapewniają systemy takie jak Hunyuan Video i Wan 2.1, może zyskać nowy wymiar autentyczności.
Chociaż układ niemal wszystkich porównawczych przykładów wideo na stronie projektu utrudnia porównywanie możliwości HunyuanCustom z poprzednimi konkurentami, należy zauważyć, że bardzo, bardzo niewiele projektów w branży syntezy wideo ma odwagę zmierzyć się w testach z Klingiem, komercyjnym interfejsem API do rozpowszechniania wideo, który zawsze utrzymuje się na szczycie lub w jego pobliżu w rankingach; Tencent wydaje się poczynić imponujące postępy w porównaniu z tym dotychczasowym konkurentem.
* Problem polega na tym, że niektóre filmy są tak szerokie, krótkie i mają tak wysoką rozdzielczość, że nie da się ich odtworzyć w standardowych odtwarzaczach wideo, takich jak VLC czy Windows Media Player; zamiast tego wyświetlają się czarne ekrany.
Pierwsze opublikowanie: czwartek, 8 maja 2025 r.











