AI 101
Hva er Forsterkingslæring?
Hva er Forsterkingslæring?
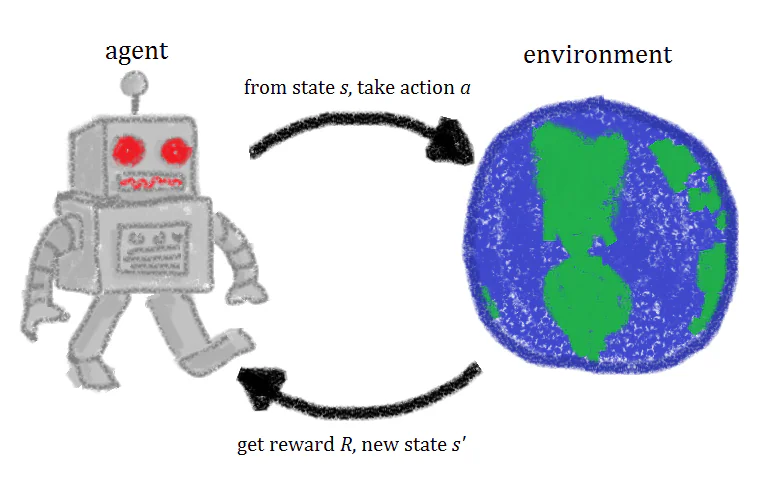
Forsterkingslæring er, sett enkelt, en maskinlæringsmetode som innebærer å trene en kunstig intelligens-agent gjennom gjentakelse av handlinger og tilhørende belønninger. En forsterkingslæringsagent eksperimenterer i en omgivelse, utfører handlinger og belønnes når riktige handlinger utføres. Over tid lærer agenten å utføre handlinger som vil maksimere belønningen. Dette er en rask definisjon av forsterkingslæring, men å se nærmere på konseptene bak forsterkingslæring vil hjelpe deg å få en bedre, mer intuitiv forståelse av det.
Begrepet “forsterkingslæring” er tilpasset fra konseptet forsterkning i psykologi. Av denne grunn, la oss ta et øyeblikk til å forstå det psykologiske konseptet forsterkning. I den psykologiske betydning, refererer begrepet forsterkning til noe som øker sannsynligheten for at en bestemt respons/handling vil skje. Dette konseptet for forsterkning er en sentral ide i teorien om operant betingning, som opprinnelig ble foreslått av psykologen B.F. Skinner. I denne sammenhengen er forsterkning noe som får hyppigheten av en gitt atferd til å øke. Hvis vi tenker på mulig forsterkning for mennesker, kan disse være ting som ros, lønnsøkning på jobb, godter og morsomme aktiviteter.
I den tradisjonelle, psykologiske betydning, finnes det to typer forsterkning. Det finnes positiv forsterkning og negativ forsterkning. Positiv forsterkning er tilføying av noe for å øke en atferd, som å gi hunden en godbit når den er veloppdragen. Negativ forsterkning innebærer fjerning av en stimulus for å fremkalle en atferd, som å slå av høy lyd for å lokke ut en sky kattpus.
Positiv & Negativ Forsterkning
Positiv forsterkning øker hyppigheten av en atferd, mens negativ forsterkning reduserer hyppigheten. Generelt er positiv forsterkning den vanligste typen forsterkning som brukes i forsterkingslæring, da den hjelper modellene å maksimere ytelsen på en gitt oppgave. Ikke bare det, men positiv forsterkning fører modellen til å gjøre mer bærekraftige endringer, endringer som kan bli bestående mønster og vedvare i lange perioder.
I motsetning til, selv om negativ forsterkning også gjør en atferd mer sannsynlig, brukes den til å opprettholde en minimumsytelsestandard fremfor å nå modellens maksimale ytelse. Negativ forsterkning i forsterkingslæring kan hjelpe med å sikre at en modell holdes borte fra uønskede handlinger, men den kan ikke gjøre en modell til å utforske ønskede handlinger.
Trening av en Forsterkingsagent
Når en forsterkingslæringsagent blir trent, finnes det fire forskjellige ingredienser eller tilstander som brukes i treningen: initiale tilstander (Tilstand 0), ny tilstand (Tilstand 1), handlinger og belønninger.
Tenk at vi trener en forsterkingsagent til å spille et plattformspill der AI-målet er å nå slutten av nivået ved å bevege seg til høyre over skjermen. Den initiale tilstanden i spillet trekkes fra omgivelsen, det vil si at den første ruten i spillet analyseres og gis til modellen. Basert på denne informasjonen, må modellen bestemme en handling.
Under de innledende fasene av treningen, er disse handlingene tilfeldige, men når modellen blir forsterket, blir visse handlinger mer vanlige. Etter at handlingen er utført, oppdateres spillomgivelsen og en ny tilstand eller rute blir skapt. Hvis handlingen utført av agenten produserte et ønsket resultat, la oss si i dette tilfelle at agenten fortsatt er i live og ikke er blitt truffet av en fiende, blir noen belønning gitt til agenten og det blir mer sannsynlig at den gjør det samme i fremtiden.
Dette grunnleggende systemet er konstant løkke, skjer igjen og igjen, og hver gang prøver agenten å lære litt mer og maksimere belønningen.
Episodiske vs Kontinuerlige Oppgaver
Forsterkingslæringsoppgaver kan vanligvis plasseres i en av to forskjellige kategorier: episodiske oppgaver og kontinuerlige oppgaver.
Episodiske oppgaver vil utføre læring/trening-løkken og forbedre ytelsen til noen sluttkriterier er møtt og treningen avsluttes. I et spill, kan dette være å nå slutten av nivået eller falle i en felle som spikre. I motsetning til, har kontinuerlige oppgaver ingen avslutningskriterier, og de fortsetter å trene til engineer velger å avslutte treningen.
Monte Carlo vs Temporal Difference
Det finnes to primære måter å lære, eller trene, en forsterkingslæringsagent. I Monte Carlo-tilnærmingen, blir belønninger levert til agenten (dens poengsum oppdateres) bare ved slutten av treningsepisoden. For å si det på en annen måte, bare når avslutningsvilkåret er møtt, lærer modellen hvordan den utførte seg. Den kan deretter bruke denne informasjonen til å oppdatere, og når neste treningrunde starter, vil den reagere i henhold til den nye informasjonen.
Temporaldifferansemetoden skiller seg fra Monte Carlo-metoden ved at verdiestimaten, eller poengestimaten, oppdateres under treningsepisoden. Når modellen går videre til neste tidssteg, oppdateres verdiene.
Utforskning vs Utbytte
Trening av en forsterkingslæringsagent er en balanseakt, som innebærer å balansere to forskjellige mål: utforskning og utbytte.
Utforskning er handlingen å samle mer informasjon om omgivelsen, mens utbytte er å bruke informasjonen som allerede er kjent om omgivelsen til å tjene belønningspoeng. Hvis en agent bare utforsker og aldri utnytter omgivelsen, vil de ønskede handlingene aldri bli utført. På den andre siden, hvis agenten bare utnytter og aldri utforsker, vil agenten bare lære å utføre en handling og ikke oppdage andre mulige strategier for å tjene belønning. Derfor er det kritisk å balansere utforskning og utbytte når man lager en forsterkingslæringsagent.
Anvendelsesområder for Forsterkingslæring
Forsterkingslæring kan brukes i en rekke roller, og det er best egnet for applikasjoner hvor oppgaver krever automatisering.
Automatisering av oppgaver som skal utføres av industriroboter er et område hvor forsterkingslæring viser seg å være nyttig. Forsterkingslæring kan også brukes for problemer som tekstmining, å lage modeller som kan sammenfatte lange tekstmasser. Forskere eksperimenterer også med å bruke forsterkingslæring i helsefeltet, med forsterkingsagenter som håndterer jobber som optimalisering av behandlingspolitikker. Forsterkingslæring kan også brukes til å tilpasse utdanningsmateriale for studenter.
Oppsummering av Forsterkingslæring
Forsterkingslæring er en kraftfull metode for å konstruere AI-agenter som kan føre til imponerende og noen ganger overraskende resultater. Å trene en agent gjennom forsterkingslæring kan være komplekst og vanskelig, da det krever mange treningssykluser og en delikat balanse av utforskning/utbytte-dikotomi. Men hvis det lykkes, kan en agent skapt med forsterkingslæring utføre komplekse oppgaver under en rekke forskjellige omgivelser.








