AI 101
오버피팅이란 무엇인가?
오버피팅이란 무엇인가?
신경망을 훈련할 때 피해야 할 문제 중 하나가 오버피팅입니다. 오버피팅은 기계 학습과 통계학에서 모델이 훈련 데이터셋의 패턴을 너무 잘 학습하여 훈련 데이터셋을 완벽하게 설명하지만 다른 데이터셋에 대한 예측力を 일반화하지 못하는 문제입니다.
다르게 말하자면, 오버피팅 모델의 경우 훈련 데이터셋에 대해서는 매우 높은 정확도를 보이지만 미래에 모델을 통해 실행되는 데이터에 대해서는 낮은 정확도를 보입니다. 이것이 오버피팅의 간단한 정의입니다. 하지만 오버피팅에 대한 개념을 더 자세히 살펴보겠습니다. 오버피팅이 발생하는 이유와 어떻게 피할 수 있는지 살펴보겠습니다.
적합도와 언더피팅 이해
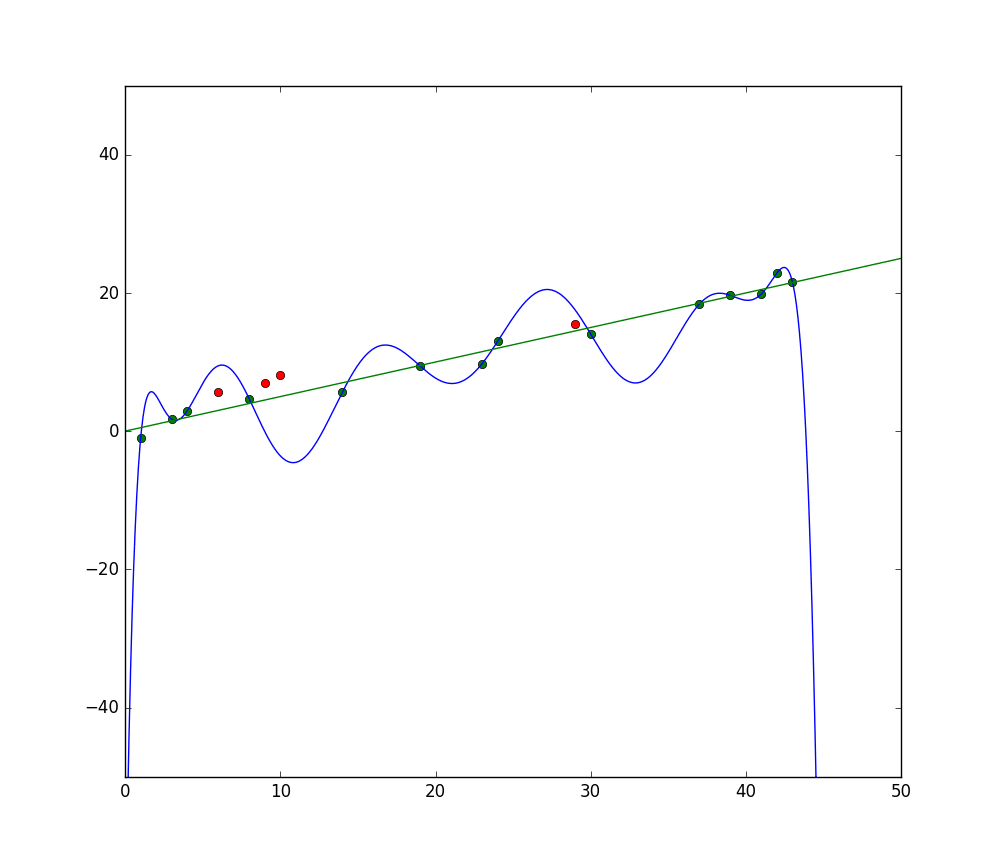
오버피팅을 이해하기 위해서는 언더피팅과 적합도에 대한 개념을 먼저 이해해야 합니다. 모델을 훈련할 때, 우리는 데이터셋 내의 항목들의 특징을 기반으로 그 항목들의 클래스를 예측할 수 있는 프레임워크를 개발하려고 합니다. 모델은 데이터셋 내의 패턴을 설명하고 미래의 데이터 포인트에 대한 클래스를 예측해야 합니다. 모델이 훈련 데이터셋의 특징 간의 관계를 잘 설명할수록, 모델의 적합도는 더 좋아집니다.

블루 라인은 언더피팅 모델의 예측을 나타내고, 그린 라인은 더好的 적합도를 나타냅니다. 사진: Pep Roca via Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
모델이 훈련 데이터의 특징 간의 관계를 잘 설명하지 못하여 미래의 데이터 예제를 정확하게 분류하지 못하는 경우, 언더피팅이 발생합니다. 만약 언더피팅 모델의 예측과 실제 값의 관계를 그래프로 나타낸다면, 예측은 실제 값에서 많이 벗어날 것입니다. 만약 그래프에 실제 훈련 데이터의 값을 표시한다면, 언더피팅 모델은 대부분의 데이터 포인트를 많이 놓칠 것입니다. 하지만 더好的 적합도를 가진 모델은 데이터 포인트를 더 잘 설명할 것입니다.
언더피팅은 일반적으로 훈련 데이터가 충분하지 않거나 비선형 데이터에 선형 모델을 사용하려고 할 때 발생합니다. 더 많은 훈련 데이터 또는 더 많은 특징을 사용하면 언더피팅을 줄일 수 있습니다.
왜 모델을 완벽하게 훈련 데이터셋을 설명하도록 만들지 않을까요? 완벽한 정확도는 바람직하지 않나요? 모델이 훈련 데이터셋의 패턴을 너무 잘 학습하여 오버피팅이 발생하는 것입니다. 훈련 데이터셋과 미래의 데이터셋은 완전히 동일하지 않습니다. 비슷한 점이 많겠지만, 중요한 점에서는 다를 것입니다. 따라서 모델을 훈련 데이터셋을 완벽하게 설명하도록 만들면, 모델은 다른 데이터셋에 일반화하지 못하는 이론을 개발할 것입니다.
오버피팅 이해
오버피팅은 모델이 훈련 데이터셋의 세부 정보를 너무 잘 학습하여 외부 데이터에 대한 예측력이 떨어지는 문제입니다. 이는 모델이 데이터셋의 특징뿐만 아니라 노이즈나 임의의 변동을도 학습하여 그 중요성을 부여할 때 발생합니다.
오버피팅은 비선형 모델을 사용할 때 더 많이 발생합니다. 비선형 모델은 데이터의 특징을 학습할 때 더 유연하기 때문입니다. 비모수 기계 학습 알고리즘은 오버피팅을 줄이기 위한 다양한 매개변수와 기술을 가지고 있습니다. 예를 들어, 의사결정 나무 모델은 오버피팅에 매우 민감하지만, 가지치기라는 기술을 사용하여 모델이 학습한 세부 정보를 랜덤하게 제거하여 오버피팅을 줄일 수 있습니다.
만약 모델의 예측을 X와 Y 축으로 그래프로 나타낸다면, 예측은 실제 값에서 많이 벗어날 것입니다. 이는 모델이 훈련 데이터셋의 모든 포인트를 설명하려고 너무 노력했기 때문입니다.
오버피팅 제어
모델을 훈련할 때, 우리는 모델이 모든 데이터 포인트에서 오류를 발생시키지 않기를 바랍니다. 모델의 성능이 훈련 데이터셋의 모든 데이터 포인트에서 올바른 예측을 하는 방향으로 수렴할 때, 모델의 적합도는 더 좋아집니다. 좋은 적합도를 가진 모델은 훈련 데이터셋을 설명하면서 오버피팅을 피할 수 있습니다.
모델을 훈련할 때, 모델의 성능은 시간이 지남에 따라 개선됩니다. 모델의 오류率는 훈련 시간이 지남에 따라 감소하지만, 어느 정도까지 감소한 후 다시 증가하기 시작합니다. 모델의 성능이 테스트 세트에서 다시 증가하기 시작하는 지점은 일반적으로 오버피팅이 발생하는 지점입니다. 모델의 최적의 적합도를 얻으려면, 모델을 훈련 데이터셋에서 가장 낮은 손실 지점에서停止해야 합니다. 하지만 이 방법에는 테스트 데이터를 사용하여 훈련을 중지하는 것이므로, 테스트 데이터가 훈련 절차에 포함되어 버리므로, 테스트 데이터의 순수성을 잃을 수 있습니다.
오버피팅을 줄이기 위한 방법은 여러 가지가 있습니다. 하나의 방법은 재표본 추출 전략을 사용하는 것입니다. 이는 모델의 정확도를 추정하는 방법입니다. 또한 테스트 세트 외에 검증 세트를 사용하여 모델의 훈련 정확도를 검증 세트와 비교하여 그래프로 나타낼 수 있습니다. 이렇게 하면 테스트 데이터셋을 보지 않은 채로 모델을 평가할 수 있습니다. 인기 있는 재표본 방법은 K-겹 교차 검증입니다. 이 기술을 사용하여 데이터를 하위 집합으로 나누어 모델을 훈련시키고, 모델의 성능을 분석하여 외부 데이터에 대한 모델의 성능을 추정할 수 있습니다.
교차 검증을 사용하는 것은 모델의 정확도를 보지 않은 데이터에 대해 추정하는 가장好的 방법 중 하나입니다. 또한 검증 데이터셋을 사용하여 오버피팅을 최소화할 수 있습니다.








