
AI 101
GAN(Generative Adversarial Network)이란 무엇입니까?
GAN (Generative Adversarial Networks) 신경망 아키텍처 유형입니다. 새로운 데이터를 생성할 수 있는 학습된 패턴을 따르는 것입니다. GAN은 사람의 얼굴이나 다른 물체의 이미지를 생성하고, 텍스트를 이미지로 변환하고, 한 유형의 이미지를 다른 이미지로 변환하고, 다른 애플리케이션 중에서 이미지의 해상도(초해상도)를 향상시키는 데 사용할 수 있습니다. GAN은 완전히 새로운 데이터를 생성할 수 있기 때문에 많은 최첨단 AI 시스템, 응용 프로그램 및 연구의 선두에 있습니다. 그러나 GAN은 정확히 어떻게 작동합니까? GAN이 어떻게 작동하는지 살펴보고 몇 가지 주요 용도를 살펴보겠습니다.
생성 모델 및 GAN 정의
GAN은 생성 모델의 한 예입니다. 대부분의 AI 모델은 감독 모델과 감독되지 않은 모델의 두 가지 범주 중 하나로 나눌 수 있습니다. 지도 학습 모델은 일반적으로 다양한 입력 범주를 구분하고 분류하는 데 사용됩니다. 반대로 감독되지 않은 모델은 일반적으로 데이터 분포를 요약하는 데 사용되며 종종 학습합니다. 데이터의 가우시안 분포. 그들은 데이터 세트의 분포를 배우기 때문에 이 학습된 분포에서 샘플을 가져와 새 데이터를 생성할 수 있습니다.
다른 생성 모델에는 데이터를 생성하고 확률 분포를 계산하는 방법이 다릅니다. 예를 들어, 나이브 베이즈 모델 다양한 입력 기능 및 생성 클래스에 대한 확률 분포를 계산하여 작동합니다. Naive Bayes 모델이 예측을 렌더링할 때 서로 다른 변수의 확률을 취하고 함께 결합하여 가장 가능성이 높은 클래스를 계산합니다. 다른 비-딥 러닝 생성 모델에는 가우시안 혼합 모델 및 LDA(Latent Dirichlet Allocation)가 포함됩니다. 심층 학습 기반 생성 모델 포함 제한된 볼츠만 기계(RBM), VAE (Variational Autoencoder), 그리고 물론 GAN.
생성적 적대 네트워크는 2014년 Ian Goodfellow가 처음 제안, 그들은 2015년에 Alec Redford와 다른 연구원들에 의해 개선되어 GAN을 위한 표준화된 아키텍처로 이어졌습니다. GAN은 실제로 함께 결합된 두 개의 서로 다른 네트워크입니다. GAN은 두 개의 반으로 구성: 생성자 및 판별자라고도 하는 세대 모델 및 판별 모델.
GAN 아키텍처
생성적 적대 신경망은 Generator 모델과 Discriminator 모델이 합쳐져 만들어졌습니다. 생성기 모델의 역할은 모델이 교육 데이터에서 학습한 패턴을 기반으로 데이터의 새로운 예를 만드는 것입니다. Discriminator 모델의 역할은 이미지를 분석하고(이미지에 대해 훈련되었다고 가정) 이미지가 생성/가짜인지 진짜인지 확인하는 것입니다.

두 모델은 게임 이론적 방식으로 훈련된 서로 경쟁합니다. 제너레이터 모델의 목표는 적수인 판별 모델을 속이는 이미지를 생성하는 것입니다. 한편, discriminator 모델의 역할은 적인 Generator 모델을 극복하고 Generator가 생성하는 가짜 이미지를 잡는 것입니다. 모델이 서로 경쟁한다는 사실은 두 모델이 모두 향상되는 군비 경쟁을 초래합니다. discriminator는 어떤 이미지가 진짜이고 어떤 이미지가 생성자에 의해 생성되었는지에 대한 피드백을 받는 반면, 생성자는 어떤 이미지가 discriminator에 의해 거짓으로 표시되었는지에 대한 정보를 받습니다. 기본적으로 진짜 데이터와 구별할 수 없는 가짜 데이터를 생성할 수 있는 세대 모델을 훈련하는 것을 목표로 두 모델 모두 훈련 중에 개선됩니다.
학습 중에 데이터의 가우시안 분포가 생성되면 생성 모델을 사용할 수 있습니다. 생성기 모델은 초기에 가우시안 분포를 기반으로 변환되는 랜덤 벡터를 공급받습니다. 즉, 벡터는 세대를 시드합니다. 모델이 훈련되면 벡터 공간은 데이터의 가우시안 분포의 압축된 버전 또는 표현이 됩니다. 데이터 분포의 압축 버전을 잠재 공간 또는 잠재 변수라고 합니다. 나중에 GAN 모델은 잠재 공간 표현을 가져와 생성 모델에 제공할 수 있는 포인트를 끌어 훈련 데이터와 매우 유사한 새 데이터를 생성하는 데 사용할 수 있습니다.
판별기 모델은 실제 데이터 예제와 생성된 데이터 예제로 구성된 전체 훈련 도메인의 예제를 제공받습니다. 실제 예제는 훈련 데이터 세트에 포함되며 가짜 데이터는 생성 모델에 의해 생성됩니다. Discriminator 모델을 훈련하는 과정은 기본 이진 분류 모델 훈련과 완전히 동일합니다.
GAN 교육 프로세스
전체를 살펴보자 훈련 방법 가상 이미지 생성 작업을 위해.
우선 GAN은 교육 데이터 세트의 일부로 진짜 실제 이미지를 사용하여 교육됩니다. 이렇게 하면 생성된 이미지와 실제 이미지를 구별하기 위해 판별기 모델이 설정됩니다. 또한 생성기가 새 데이터를 생성하는 데 사용할 데이터 분포를 생성합니다.
생성기는 임의의 숫자 데이터 벡터를 가져와 가우시안 분포를 기반으로 변환하여 이미지를 반환합니다. 이 생성된 이미지는 교육 데이터 세트의 일부 실제 이미지와 함께 판별 모델에 공급됩니다. Discriminator는 수신한 이미지의 특성에 대한 확률적 예측을 렌더링하여 0과 1 사이의 값을 출력합니다. 여기서 1은 일반적으로 정품 이미지이고 0은 가짜 이미지입니다.
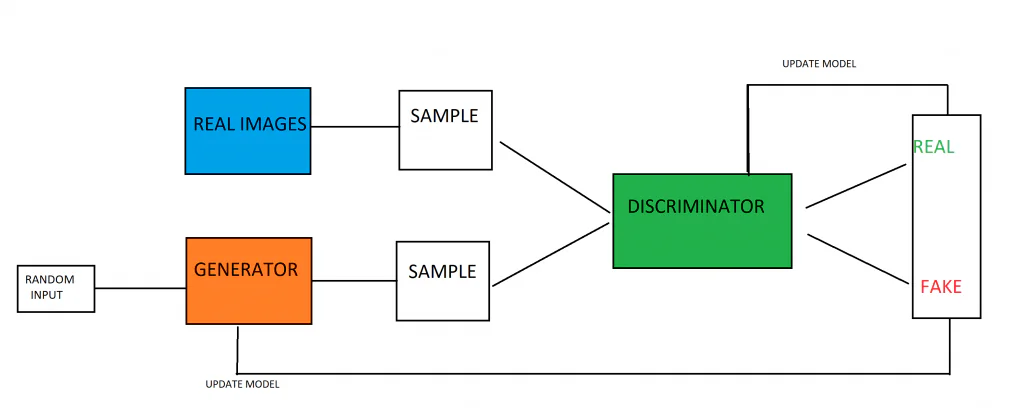
Ground discriminator는 이미지의 ground truth를 공급받는 반면 Generator는 discriminator에 의해 성능에 대한 피드백을 받기 때문에 이중 피드백 루프가 작동합니다.
생성 모델과 차별 모델은 서로 제로섬 게임을 하고 있습니다. 제로섬 게임은 한쪽의 이득이 다른 쪽의 비용으로 오는 게임입니다(합은 두 행동 모두 XNUMX입니다). discriminator 모델이 실제와 가짜 예를 성공적으로 구별할 수 있으면 discriminator의 매개 변수가 변경되지 않습니다. 그러나 실제 이미지와 가짜 이미지를 구별하지 못하는 경우 모델의 매개변수가 크게 업데이트됩니다. 생성 모델의 경우 그 반대입니다. 판별 모델을 속이는 데 실패하면 페널티를 받고(매개 변수가 업데이트됨) 그렇지 않으면 매개 변수가 변경되지 않습니다(또는 보상을 받습니다).
이상적으로 생성기는 판별자가 가짜 이미지와 실제 이미지를 구분할 수 없는 지점까지 성능을 향상시킬 수 있습니다. 이것은 discriminator가 진짜 이미지와 가짜 이미지에 대해 항상 %50의 확률을 렌더링한다는 것을 의미합니다. 즉, 생성된 이미지는 진짜 이미지와 구별할 수 없어야 합니다. 실제로 GAN은 일반적으로 이 지점에 도달하지 않습니다. 그러나 생성 모델은 GAN이 사용되는 많은 작업에 여전히 유용하기 위해 완벽하게 유사한 이미지를 생성할 필요가 없습니다.
GAN 애플리케이션
GAN에는 다양한 응용 프로그램이 있으며 대부분은 이미지 생성 및 이미지 구성 요소를 중심으로 이루어집니다. GAN은 일반적으로 필요한 이미지 데이터가 없거나 용량이 제한된 작업에서 필요한 데이터를 생성하는 방법으로 사용됩니다. GAN의 일반적인 사용 사례 중 일부를 살펴보겠습니다.
데이터 세트에 대한 새 예제 생성
GAN을 사용하여 간단한 이미지 데이터 세트에 대한 새로운 예제를 생성할 수 있습니다. 소수의 훈련 예제만 있고 더 많은 예제가 필요한 경우 GAN을 사용하여 이미지 분류기에 대한 새로운 훈련 데이터를 생성하여 다양한 방향과 각도에서 새로운 훈련 예제를 생성할 수 있습니다.
고유한 인간 얼굴 생성

이 사진의 여자는 존재하지 않습니다. 이미지는 StyleGAN에 의해 생성되었습니다. 사진: Wikimedia Commons를 통한 Owlsmcgee, 퍼블릭 도메인(https://commons.wikimedia.org/wiki/File:Woman_1.jpg)
충분히 훈련되면 GAN을 사용하여 다음을 수행할 수 있습니다. 인간 얼굴의 매우 사실적인 이미지를 생성합니다. 이렇게 생성된 이미지는 얼굴 인식 시스템을 교육하는 데 사용할 수 있습니다.
이미지 대 이미지 번역
간 이미지 번역에 탁월합니다. GAN은 흑백 이미지를 색칠하거나, 스케치나 그림을 사진 이미지로 변환하거나, 낮에서 밤으로 이미지를 변환하는 데 사용할 수 있습니다.
텍스트를 이미지로 번역
텍스트-이미지 번역은 GAN을 사용하여 가능. 이미지와 동반 이미지를 설명하는 텍스트가 제공되면 GAN은 다음을 수행할 수 있습니다. 새로운 이미지를 만드는 훈련을 받다 원하는 이미지에 대한 설명이 제공될 때.
이미지 편집 및 복구
GAN은 기존 사진을 편집하는 데 사용할 수 있습니다. GAN 비나 눈과 같은 요소를 제거하십시오. 이미지에서 사용할 수 있지만 다음에도 사용할 수 있습니다. 오래되거나 손상된 이미지 또는 손상된 이미지를 복구합니다.
초 고해상도
초고해상도는 저해상도 이미지를 가져와 이미지에 더 많은 픽셀을 삽입하여 해당 이미지의 해상도를 향상시키는 프로세스입니다. GAN은 이미지를 찍도록 훈련될 수 있습니다. 해당 이미지의 고해상도 버전을 생성합니다.














