AI 101
딥 러닝에서 RNN과 LSTM이란 무엇인가?
자연어 처리와 AI 챗봇에서 가장 인상적인 진보는 Recurrent Neural Networks (RNNs)와 Long Short-Term Memory (LSTM) 네트워크에 의해 주도된다. RNN과 LSTM은 순차적 데이터를 처리할 수 있는 특별한 신경망 아키텍처이다. LSTM은 본질적으로 RNN의 개선된 버전으로, 더 긴 데이터 시퀀스를 해석할 수 있다. RNN과 LSTM의 구조와 자연어 처리 시스템을 생성하는 방법을 살펴보자.
피드 포워드 신경망이란 무엇인가?
LSTM과 CNN이 작동하는 방식에 대해 논의하기 전에 일반적인 신경망의 형식을 논의해야 한다.
신경망은 데이터를 검사하고 관련 패턴을 학습하여 다른 데이터에 적용하고 새 데이터를 분류할 수 있다. 신경망은 세 개의 섹션으로 나뉜다: 입력 계층, 숨겨진 계층(또는 여러 숨겨진 계층), 출력 계층.
입력 계층은 신경망에 데이터를 입력받는 역할을 한다. 숨겨진 계층은 데이터의 패턴을 학습한다. 숨겨진 계층은 입력 계층과 출력 계층에 의해 가중치와 편향으로 연결된다. 이러한 가중치는 훈련过程에서 조정된다. 네트워크가 훈련될수록 모델의 추측(출력 값)은 실제 훈련 레이블과 비교된다. 훈련过程에서 네트워크는 데이터 포인트 간의 관계를 예측하는 정확도가提高되어야 한다. 깊은 신경망은 중간에 더 많은 계층을 가진 네트워크이다. 모델의 숨겨진 계층과 노드가 많을수록 모델은 데이터의 패턴을 더 잘 인식할 수 있다.
일반적인 피드 포워드 신경망은 밀집 신경망이라고도 한다. 이러한 밀집 신경망은 다른 네트워크 아키텍처와 결합하여 다양한 유형의 데이터를 해석한다.
RNN(재귀 신경망)이란 무엇인가?

RNN은 피드 포워드 신경망의 일반적인 원리를 따르며, 모델에 내부 메모리를 제공하여 순차적 데이터를 처리할 수 있다. RNN의 이름에서 “재귀”라는 단어는 입력과 출력이 루프를 형성한다는 事実에서 유래했다. 네트워크의 출력이 생성되면 출력이 복사되어 네트워크에 입력으로 반환된다. 결정할 때 현재 입력과 출력만이 아니라 이전 입력도 고려된다. 즉, 초기 입력이 X이고 출력이 H인 경우, H와 X1(데이터 시퀀스의 다음 입력)은 네트워크에 다음 라운드의 학습을 위해 입력된다.这样하면 데이터의 컨텍스트(이전 입력)를 네트워크가 훈련过程에서 유지할 수 있다.
RNN의 결과는 순차적 데이터를 처리할 수 있다. 그러나 RNN은 몇 가지 문제가 있다. RNN은 소실 경사와 폭발 경사 문제를uffers한다.
RNN이 해석할 수 있는 시퀀스의 길이는 제한적이며, 특히 LSTM에 비해 제한적이다.
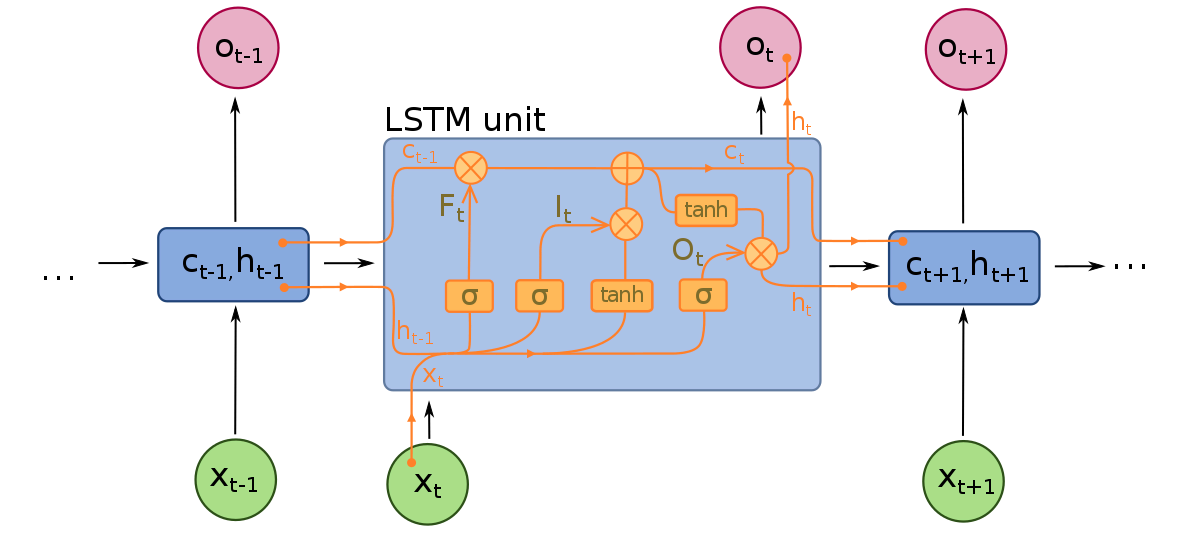
LSTM(장단기 메모리)이란 무엇인가?
LSTM은 RNN의 확장으로, 입력의 컨텍스트를 유지하는 개념을 적용한다. 그러나 LSTM은 소실 경사 문제를 해결하고 더 긴 입력 시퀀스를 해석할 수 있도록 수정되었다. LSTM은 세 가지 구성 요소 또는 게이트로 구성된다. 입력 게이트, 출력 게이트, 그리고忘却 게이트가 있다. RNN과 마찬가지로 LSTM은 이전 시간 단계의 입력을 모델의 메모리와 입력 가중치를 수정할 때 고려한다. 입력 게이트는 중요한 값에 대한 결정과 모델을 통해 전달할 값을 결정한다. 시그모이드 함수는 입력 게이트에서 사용되며, 값의 중요성을 결정한다. 0은 값을 삭제하고, 1은 값을 유지한다. TanH 함수도 여기에서 사용되며, 입력 값의 중요성을 모델에 대해 결정한다.
현재 입력과 메모리 상태가 계산된 후, 출력 게이트는 다음 시간 단계에 전달할 값을 결정한다. 출력 게이트에서 값은 분석되고 중요도가 -1에서 1 사이의 범위로 할당된다. 이는 데이터가 다음 시간 단계의 계산으로 전달되기 전에 조정된다. 마지막으로,忘却 게이트는 모델이 결정에 필요하지 않은 정보를 삭제하는 역할을 한다.忘却 게이트는 시그모이드 함수를 사용하여 0(이 정보를 忘却)과 1(이 정보를 유지) 사이의 값을 출력한다.
LSTM 신경망은 특별한 LSTM 계층과 밀집 계층으로 구성된다. 데이터가 LSTM 계층을 통해 이동한 후, 밀집 계층으로 진행된다.








