AI 101
決定木とは何か?
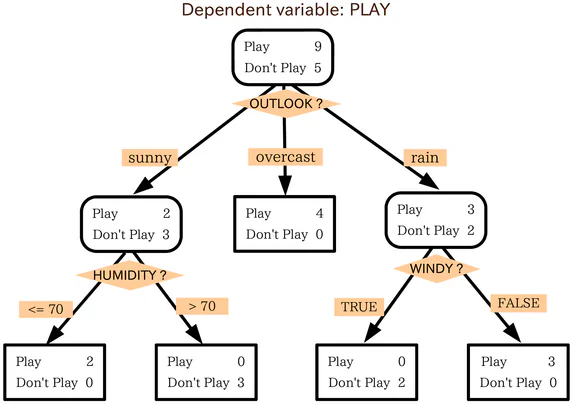
決定木とは何か?
決定木は、回帰と分類の両タスクに使用される有用な機械学習アルゴリズムです。決定木という名前は、アルゴリズムがデータセットを小さな部分に分割し続け、最終的にデータが単一のインスタンスに分割されるという事実から来ています。如果視覚化するなら、アルゴリズムの結果は、カテゴリが分割される方法が木のように見え、多くの葉を持つことになります。
これは決定木の簡単な定義ですが、決定木がどのように機能するかについて深く掘り下げてみましょう。決定木のしくみとそのユースケースを理解することで、機械学習プロジェクトでいつそれらを使用するかを知ることができます。
決定木の形式
決定木はフローチャートと似ています。フローチャートを使用するには、チャートの開始点、またはルートから始めて、開始ノードのフィルタリング条件に基づいて次の可能なノードに移動します。このプロセスは、終了するまで繰り返されます。
決定木も基本的に同じ方法で動作します。木の中間ノードはすべて、ある種のテスト/フィルタリング条件です。木の外側のノード、つまり木の端点は、データポイントのラベルであり、「葉」と呼ばれます。中間ノードから次のノードへの枝は、特徴または特徴の結合です。データポイントを分類するルールは、ルートから葉までのパスです。

決定木のアルゴリズム
決定木は、データセットを個々のデータポイントに分割するアルゴリズムアプローチを使用します。これらの分割は、さまざまな条件で実行されます。たとえば、入力特徴が犬または猫を記述しているかどうかを判断する場合、データを分割する変数は「爪」や「吠える」などのものになります。
那么、データを分割して枝と葉を作成するために使用されるアルゴリズムは何ですか?分割するためのさまざまな方法がありますが、最も一般的な分割方法は「再帰的二分割」と呼ばれるテクニックです。この分割方法を使用すると、プロセスはルートから開始され、データセットの特徴の数は可能な分割の数を表します。各可能な分割の精度のコストを決定するために使用される関数があり、分割は最も精度を犠牲にする条件で実行されます。このプロセスは再帰的に実行され、同じ戦略を使用してサブグループが形成されます。
分割のコストを決定するために、コスト関数が使用されます。回帰タスクと分類タスクの両方で、異なるコスト関数が使用されます。両方のコスト関数の目的は、最も類似した応答値を持つ枝、または最も均一な枝を見つけることです。特定のクラスのテストデータが特定のパスを辿るようにしたいと考えることは、直感的に理解できます。
再帰的二分割の回帰コスト関数の場合、コストを計算するために使用されるアルゴリズムは次のとおりです:
sum(y – prediction)^2
特定のデータポイントグループの予測は、そのグループのトレーニングデータの応答の平均です。すべてのデータポイントをコスト関数を通じて実行して、すべての可能な分割のコストを決定し、最も低いコストの分割が選択されます。
分類のコスト関数については、関数は次のとおりです:
G = sum(pk * (1 – pk))
これはジニスコアであり、分割の有効性の尺度であり、分割によって得られるグループ内の異なるクラスのインスタンスの数に基づいています。言い換えると、分割後のグループの混合度を量化します。最適な分割は、分割によって得られるすべてのグループが1つのクラスの入力のみで構成される場合です。如果最適な分割が作成された場合、「pk」値は0または1になり、Gは0になります。二項分類の場合、最悪の分割はクラスが分割されたグループで50-50の表現される場合です。この場合、「pk」値は0.5になり、Gも0.5になります。
分割プロセスは、すべてのデータポイントが葉になり、分類されるまで続きます。ただし、木の成長を早く停止したい場合があります。大きく複雑な木は過剰適合する傾向がありますが、過剰適合に対処するために使用できるさまざまな方法があります。過剰適合を減らす1つの方法は、葉を作成するために使用される最小のデータポイントの数を指定することです。過剰適合を制御する別の方法は、木を特定の最大深度に制限することです。これにより、ルートから葉までのパスの長さが制御されます。
決定木の作成に関与する別のプロセスは剪定です。剪定により、特徴の予測力が低い/モデルにとって重要でない枝を除去することで、決定木のパフォーマンスを向上させることができます。这样、木の複雑さが軽減され、過剰適合の可能性が低くなり、モデルの予測の有用性が向上します。
剪定を実行する場合、プロセスは木のトップまたはボトムから開始できます。ただし、最も簡単な剪定方法は、葉から開始し、最も共通のクラスが含まれるノードを削除することです。如果モデルが変更されても精度が低下しない場合、変更は保持されます。剪定を実行するための他のテクニックもありますが、上記で説明した方法 (剪定によるエラーの削減) が最も一般的な決定木の剪定方法です。
決定木の使用に関する考慮事項
決定木は、分類が必要だが、計算時間が大きな制約である場合に便利です。決定木は、選択したデータセットのどの特徴が最も予測力を持っているかを明確に示すことができます。さらに、多くの機械学習アルゴリズムでは、データを分類するために使用されるルールが解釈するのが難しい場合がありますが、決定木は解釈可能なルールを提供します。決定木は、カテゴリと連続の両方の変数を使用できるため、アルゴリズムが1つの変数タイプのみを処理できる場合と比較して、前処理が少なくて済みます。
決定木は、連続的な属性の値を決定する場合に、特にうまく機能しません。決定木の別の制限は、分類を行う場合、トレーニング例が少なく、クラスが多いと、決定木は不正確になる傾向があります。








