人工知能
ChatGPTの1周年: AIインタラクションの未来を再定義する

ChatGPTの1年間を振り返ると、このツールがAIのシーンを大きく変えたことが明らかだ。2022年末にリリースされたChatGPTは、ユーザーフレンドリーで会話形式のスタイルが特徴で、AIとのやり取りが機械ではなく人との会話のように感じられるようになった。この新しいアプローチはすぐに一般の大衆の目に止まった。リリース後わずか5日で、ChatGPTはすでに100万人のユーザーを集め、2023年初頭には約1億人の月間ユーザーに達し、10月までに世界中で約17億回の訪問があった。これらの数字は、その人気と有用性について語り尽くしている。
過去1年間で、ユーザーはChatGPTを様々な創造的な方法で使用してきた。シンプルなタスク seperti メールの書き方や履歴書の更新から、成功したビジネスの立ち上げまで。しかし、それはただの人々がそれをどのように使用しているかではなく、技術自体が成長し改善されたことにも関係がある。最初、ChatGPTは詳細なテキスト応答を提供する無料サービスだった。現在、ChatGPT Plusが利用可能で、ChatGPT-4を含む。この更新されたバージョンは、より多くのデータでトレーニングされており、間違った答えを出さないで、複雑な指示をよりよく理解する。
最大の更新点は、ChatGPTが今や多様な方法で相互作用できることだ。音声を聞く、話す、そして画像を処理することができる。これは、モバイルアプリを通じて会話をすることができ、画像を表示して応答を得ることができることを意味する。これらの変更は、AIの新たな可能性を開き、人々がAIの役割について考えるやり方を変えた。
テクノロジー デモとしての始まりから、テクノロジー界における主要プレーヤーとしての現在の地位まで、ChatGPTの旅は非常に印象的だ。最初、技術のテストと改善のために一般の人々からのフィードバックを得る手段として見られていた。しかし、すぐにAIの風景における不可欠な部分となった。この成功は、大規模言語モデル(LLM)を教師あり学習と人間からのフィードバックでファインチューニングする有効性を示している。結果として、ChatGPTは幅広い質問やタスクに対応できるようになった。
最も有能で多機能なAIシステムを開発する競争は、ChatGPTのようなオープンソースモデルやプロプライエタリ モデルの普及につながった。彼らの一般的な能力を理解するには、幅広いタスクに対する包括的なベンチマークが必要だ。このセクションでは、これらのベンチマークについて説明し、ChatGPTを含むさまざまなモデルがどのように互いに比較されるかを明らかにする。
LLMの評価: ベンチマーク
- MT-Bench: このベンチマークは、8つのドメイン(書き込み、ロールプレイ、情報抽出、推論、数学、コーディング、STEM知識、人文科学)におけるマルチターン会話と指示の実行能力をテストする。GPT-4のような強力なLLMが評価者として使用される。
- AlpacaEval: AlpacaFarm評価セットに基づくこのLLMベースの自動評価器は、GPT-4やClaudeのような高度なLLMからの応答と比較して、モデルの勝率を計算する。
- Open LLM Leaderboard: 言語モデル評価ハーネスを使用して、LLMを7つの重要なベンチマーク(推論課題や一般知識テストなど)で評価する。ゼロショットとファインショットの設定で行われる。
- BIG-bench: この共同ベンチマークでは、200を超える新しい言語タスクを網羅し、多様なトピックや言語をカバーする。LLMの将来の能力を予測することを目的としている。
- ChatEval: オープンエンドの質問や伝統的な自然言語生成タスクに対するさまざまなモデルの応答の品質を評価するためのマルチエージェント ディベート フレームワーク。
比較パフォーマンス
一般的なベンチマークにおいて、オープンソースのLLMは著しい進歩を示している。例えば、Llama-2-70Bは、特に指示データでファインチューニングされた後、印象的な結果を達成した。AlpacaEvalでは、92.66%の勝率を記録し、GPT-3.5-turboを上回った。しかし、GPT-4は95.28%の勝率でトップを維持している。
Zephyr-7Bは、より小さいモデルながら、AlpacaEvalやMT-Benchで70BのLLMと同等の能力を示した。WizardLM-70Bは、MT-BenchでオープンソースLLMの中で最高スコアを達成したが、GPT-3.5-turboとGPT-4にはまだ及ばない。
GodziLLa2-70Bは、Open LLM Leaderboardで競争的なスコアを記録し、多様なデータセットを組み合わせた実験モデルの潜在性を示した。Yi-34Bは、GPT-3.5-turboと同等のスコアを記録し、GPT-4にはわずかに及ばない程度だった。
UltraLlamaは、多様で高品質のデータでファインチューニングされた結果、提案されたベンチマークでGPT-3.5-turboと同等の成績を収め、世界や専門知識の分野ではそれを上回った。
スケールアップ: 巨大LLMの台頭
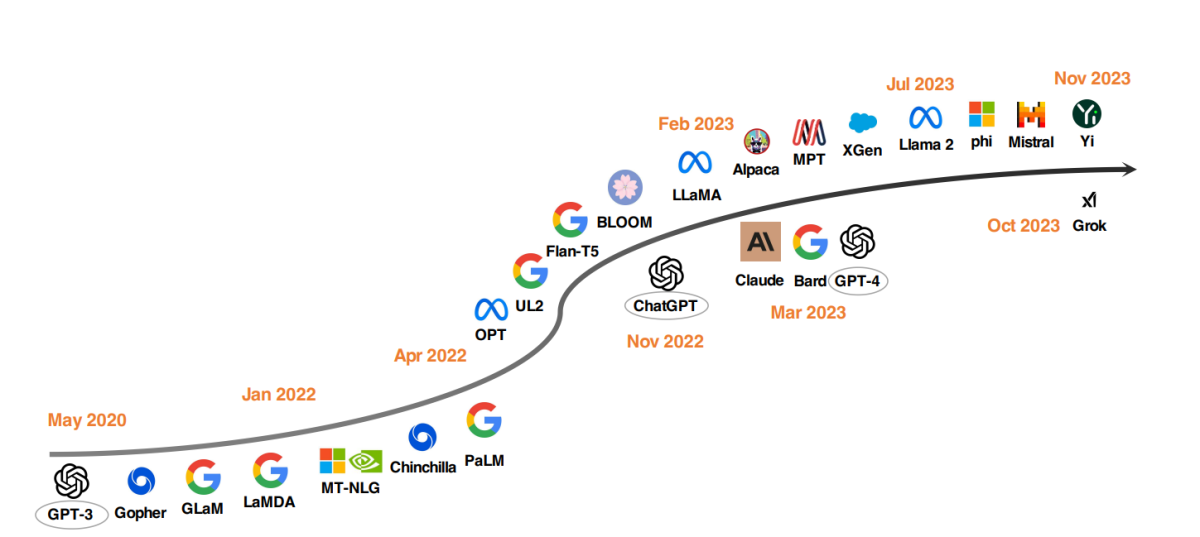
2020年以降のトップLLMモデル
LLM開発における注目すべきトレンドは、モデルのパラメータをスケールアップすることだ。Gopher、GLaM、LaMDA、MT-NLG、PaLMのようなモデルは、最大540億のパラメータを持つモデルまでの境界を押し広げてきた。これらのモデルは卓越した能力を示しているが、クローズドソースであるため、より広範な応用が制限されている。この制限は、オープンソースLLMの開発への関心を高めている。
モデルのサイズを単純に大きくするのではなく、研究者は代替戦略を模索している。ChinchillaやUL2のようなモデルは、より賢い戦略で効率的な結果をもたらすことを示している。また、FLAN、T0、Flan-T5のようなプロジェクトが言語モデルの指示チューニングに重大な貢献をしている。
ChatGPTのカタリスト
OpenAIのChatGPTの導入は、NLP研究における転換点となった。OpenAIと競争するために、GoogleやAnthropicはそれぞれBardとClaudeをリリースした。これらのモデルは多くのタスクでChatGPTと同等のパフォーマンスを示しているが、OpenAIの最新モデルGPT-4にはまだ及ばない。これらのモデルの成功は、人間のフィードバックからの強化学習(RLHF)に帰因され、この技術はさらに改善のために研究の焦点を集めている。
OpenAIのQ\*(Q-Star)に関する噂と推測
最近の報告によると、OpenAIの研究者はQ\*(クゥ・スター)と呼ばれる新しいモデルを開発し、AIにおける重大なブレークスルーを達成した可能性がある。Q\*は小学校レベルの数学を実行できる能力を持つとされるが、これは専門家の間で人工一般知能(AGI)への道標としてのその潜在性について議論を呼んでいる。
Q\*の開発は注目に値する。既存の言語モデル seperti ChatGPTやGPT-4は、一部の数学タスクには対応できるが、信頼性は高くない。課題は、AIモデルが単にパターンを認識するのではなく、抽象概念を理解し、推論する能力を持つ必要があることにある。数学は推論のベンチマークであり、AIは複数のステップを計画し実行し、抽象概念を深く理解する必要がある。
しかし、専門家はこの開発を過大評価しないよう警告している。数学タスクを信頼性高く解くことができるAIシステムは、印象的な成果となるが、必ずしも超知能AIまたはAGIの到来を意味するわけではない。現在のAI研究、OpenAIを含む、は基本的な問題に焦点を当てており、より複雑なタスクではさまざまな程度の成功を収めている。
Q\*のような進歩の潜在的な応用は広範囲にわたる。個別の指導から科学研究やエンジニアリングへの支援まで。しかし、期待を管理し、こうした進歩の限界や安全性に関する懸念を認識することが重要だ。AIが実存的リスクをもたらす可能性についての懸念、OpenAIの基礎的な懸念は、AIシステムがより実世界と関わるようになるにつれて、依然として重要なままだ。
オープンソースLLMムーブメント
オープンソースLLM研究を促進するために、MetaはLlamaシリーズモデルをリリースし、Llamaに基づく新しい開発の波を引き起こした。これには、Alpaca、Vicuna、Lima、WizardLMのような、指示データでファインチューニングされたモデルが含まれる。エージェントの能力、論理的推論、長文モデル化の強化に関する研究も、Llamaベースのフレームワークで進められている。
さらに、MPT、Falcon、XGen、Phi、Baichuan、Mistral、Grok、Yiのような、スクラッチから開発された強力なLLMへの取り組みがある。これらの努力は、クローズドソースLLMの能力を民主化し、先進的なAIツールをよりアクセスしやすく効率的なものにするというコミットメントを反映している。
ChatGPTとオープンソースモデルのヘルスケアへの影響
将来、LLMは臨床ノートの作成、請求書の作成、医師の診断と治療計画のサポートに役立つ可能性がある。この分野はテクノロジー企業やヘルスケア機関の注目を集めている。
MicrosoftのEpicとの協議は、LLMをヘルスケアに統合することを示唆しており、UCサンディエゴヘルスやスタンフォード大学医療センターでは既に取り組みが始まっている。同様に、GoogleのMayo Clinicとのパートナーシップや、Amazon Web ServicesのHealthScribeの立ち上げは、AIをヘルスケアに取り入れる重要なステップを示している。
しかし、これらの急速な展開は、医学を企業の利益に任せることについて懸念を引き起こしている。プロプライエタリなLLMの性質は、評価を難しくしている。利益のために変更または中止される可能性があるため、患者のケア、プライバシー、安全性が損なわれる可能性がある。
ヘルスケアにおけるLLM開発へのオープンで包括的なアプローチが必要だ。ヘルスケア機関、研究者、医療従事者、患者は、ヘルスケア用のオープンソースLLMを共同で開発するために世界中で協力しなければならない。これは、Trillion Parameter Consortiumに似たアプローチで、計算リソース、財政リソース、専門知識のプールを可能にする。












