人工知能
AIがビデオ会議中の『部屋の雰囲気を読む』ことを不安なスピーカーに助ける

2013年、一般的な恐怖症に関する調査では、多くの回答者にとって、死の可能性よりも公の場での話すことの方が悪いと判断された。この症状は、glossophobia(公の場での話すことへの恐怖)として知られている。
COVID-19によって、対面でのミーティングからオンラインのZoom会議への移行は、予想に反して状況を改善しなかった。参加者が多い場合、低解像度の参加者アイコンや参加者の顔の表情やボディランゲージの微妙な視覚的信号を読み取ることが困難になるため、自然な脅威評価能力が損なわれる。Skypeは、非言語的な合図を伝えるには適していないプラットフォームであることがわかっている。
話し手のパフォーマンスに与える、聞き手の興味や反応の認識の影響は、既に十分に文書化されており、多くの人にとって直感的に明らかである。聞き手の反応が不明瞭な場合、話し手は躊躇して「filler speech」に頼ることがあり、自分の主張が賛成、軽蔑、または無関心に遭遇しているかどうかを知ることができず、話し手と聞き手の両方にとって不快な経験になることが多い。
COVID-19の影響によるオンラインビデオ会議への急速な移行の圧力の下、この問題は悪化していると主張することができ、コンピュータビジョンと感情研究のコミュニティでは、過去2年間でいくつかの改善された聴衆フィードバックスキームが提案されている。
ハードウェアに焦点を当てた解決策
しかし、これらの多くは、プライバシーまたはロジスティクスに関する問題を引き起こす可能性のある追加の機器または複雑なソフトウェアを必要とするため、相対的に高コストまたはその他のリソース制約アプローチスタイルである。2001年、MITは、聴衆参加者の感情状態を推測するために手で着用するデバイスである「Galvactivator」を提案し、1日間のシンポジウムでテストした。

2001年のMITのGalvactivator。聴衆の感情状態と関与を理解するために、皮膚の導電性反応を測定した。 ソース: https://dam-prod.media.mit.edu/x/files/pub/tech-reports/TR-542.pdf
学術的なエネルギーも、聴衆参加者がアクティブな参加を増やすための「クリッカー」の展開に注がれてきた。さらに、話し手の奨励の手段としても考えられている。
話し手と聴衆を「接続」する他の試みには、心拍数の測定、複雑な身体着用機器を使用した脳波測定、「チアメーター」、デスクワーカー向けのコンピュータビジョンに基づく感情認識、話し手の演説中に聴衆が送信する絵文字の使用が含まれる。

2017年のLMUミュンヘンとシュトゥットガルト大学の共同学術研究プロジェクトであるEngageMeter。 ソース: http://www.mariamhassib.net/pubs/hassib2017CHI_3/hassib2017CHI_3.pdf
視線推定と追跡に特化したシステムは、各聴衆参加者(その後話し手になる可能性がある)が、関与と賛成の指標として眼球追跡の対象となる。
これらの方法はすべて、高い摩擦がある。多くの場合、専用のハードウェア、研究室環境、特殊なソフトウェアフレームワーク、または高価な商用APIへのサブスクリプションが必要である。
したがって、過去18ヶ月間で、ビデオ会議ツールに基づく最小限のシステムの開発が注目されている。
聴衆の賛意を微妙に報告する
この目的のために、東京大学とカーネギーメロン大学の新しい研究共同プロジェクトは、標準のビデオ会議ツール(Zoomなど)に乗っ取り、Webカメラが搭載されたWebサイトで軽量の視線推定と姿勢推定ソフトウェアを実行する新しいシステムを提供する。ローカルブラウザープラグインの必要性さえも回避できる。
ユーザーのうなずきと推定された眼球注目は、話し手に視覚化される代表的なデータに翻訳され、コンテンツが聴衆をどれだけ魅了しているかを「生」のリットマス試験を可能にし、話し手が聴衆の関心を失っている可能性のある話し手の議論の期間についても、少なくとも漠然とした指標を提供する。
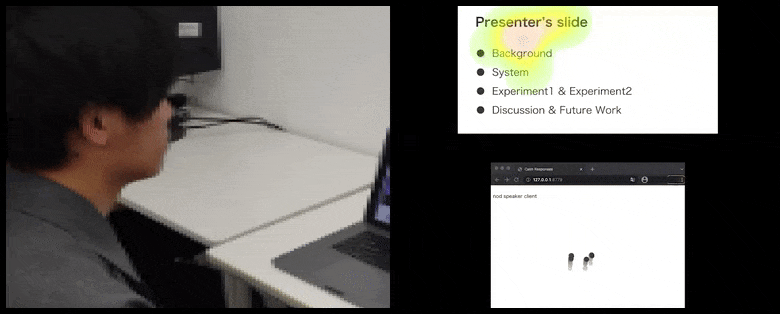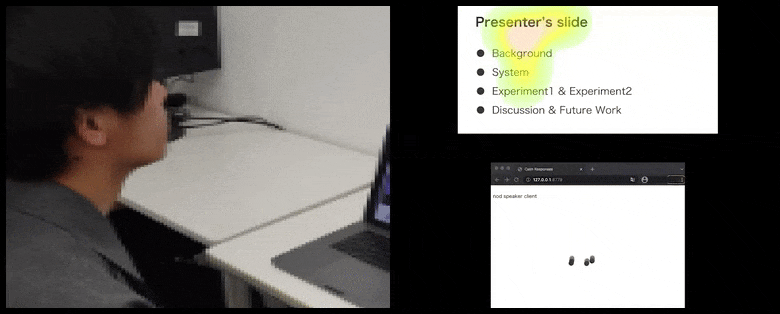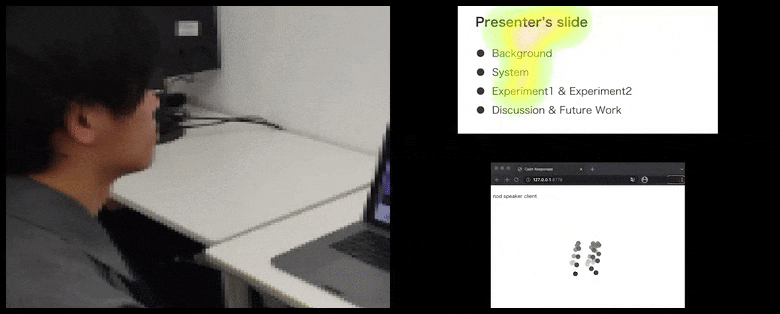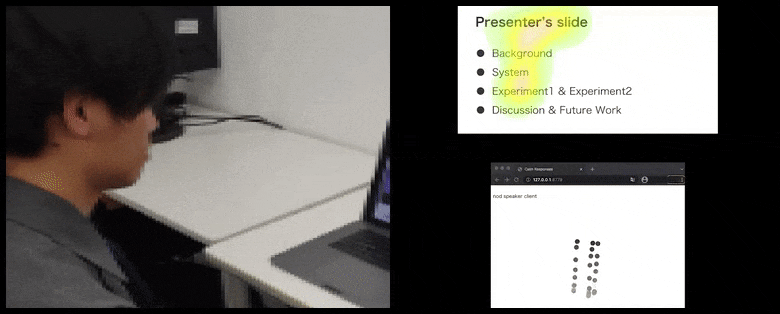
CalmResponsesでは、ユーザーの注目とうなずきが聴衆のフィードバックのプールに追加され、視覚的な表現に翻訳される。詳細と例については、記事の末尾にある埋め込み動画を参照してください。 ソース: https://www.youtube.com/watch?v=J_PhB4FCzk0
多くの学術的な状況では、オンライン講義など、学生は話し手から見えていない可能性がある。なぜなら、彼らは背景や現在の外見についての自己意識のために、カメラをオンにしていないからである。CalmResponsesは、話し手にコンテンツを見ているか、うなずいているかを報告することで、話し手のフィードバックのこのような障害に対処できる。
論文は、遠隔コミュニケーションにおける集団的な聴衆の反応の表示:CalmResponsesと題されており、東京大学の2人の研究者とカーネギーメロン大学の1人の研究者による共同研究である。
著者は、ライブWebベースのデモを提供し、GitHubでソースコードを公開している。
CalmResponsesフレームワーク
CalmResponsesが他の頭の動きではなく、うなずきに興味を持っているのは、聴衆の頭の動きの80%以上がうなずきで構成されていることを示す研究(一部はダーウィンの時代まで遡る)に基づいている。同時に、眼球の動きは、興味や関与の信頼できる指標であることが多数の研究で示されている。
CalmResponsesは、HTML、CSS、JavaScriptで実装されており、3つのサブシステムで構成されている:聴衆クライアント、話し手クライアント、サーバー。聴衆クライアントは、ユーザーのWebカメラからの眼球注目または頭の動きのデータを、Herokuクラウドアプリケーションプラットフォーム経由でWebSocketsを使用してサーバーに渡す。

聴衆のうなずきが右側にアニメーション化された動きで視覚化される。 ソース: https://arxiv.org/pdf/2204.02308.pdf
眼球追跡のセクションでは、研究者は、WebGazerという軽量でJavaScriptベースのブラウザーベースの眼球追跡フレームワークを使用した。これは、Webサイトから直接低遅延で実行できる。
入力された姿勢データは、平均値に従って平滑化される前に、全体的な反応推定のために考慮される。
うなずきの動作は、JavaScriptライブラリclmtrackrを使用して評価される。これは、画像やビデオ内の検出された顔に顔モデルを合わせる。経済性と低遅延のために、著者の実装では、鼻のランドマークのみがアクティブに監視される。これは、うなずきの動作を追跡するのに十分である。
ユーザーの鼻の先の動きが、うなずきに関連する聴衆の反応のプールに貢献する。
ヒートマップ
うなずきの動作は、動的な移動するドットで表現される(上の画像と記事末尾の動画を参照)。視覚的注目は、話し手と聴衆が、共有プレゼンテーションスクリーンまたはビデオ会議環境で一般的な注目の焦点がどこにあるかを示すヒートマップで報告される。

すべての参加者が、一般的なユーザーの注目がどこに焦点を当てているかを確認できる。
テスト
CalmResponsesのテスト環境は、3つの異なる状況セットを使用して2つのテスト環境で行われた:「Condition B」(ベースライン)では、著者は、多くの学生がWebカメラをオフにしている典型的なオンライン学生講義を再現し、話し手は聴衆の顔を見ることができない。「Condition CR-E」では、話し手は視線のフィードバック(ヒートマップ)を確認できた。「Condition CR-N」では、話し手は聴衆のうなずきと視線の活動を確認できた。
最初の実験シナリオは、条件Bと条件CR-Eで構成され、2番目の実験シナリオは、条件Bと条件CR-Nで構成されていた。話し手と聴衆の両方からフィードバックが得られた。
各実験では、3つの要素が評価された:プレゼンテーションの客観的および主観的な評価(話し手からの自己報告式質問紙を含む)、話し手の不安や躊躇の兆候である「filler speech」のイベントの数、および質的コメント。これらの基準は、話し手のパフォーマンスと不安の評価に一般的に使用される。
テストプールは、19〜44歳の38人で構成され、29人の男性と9人の女性で、平均年齢は24.7歳で、日本人または中国人であり、日本語が堪能だった。彼らは6〜7人の参加者で5つのグループにランダムに分割され、参加者はお互いに個人的に知り合いではなかった。
テストはZoomで実施され、最初の実験では5人の話し手がプレゼンテーションを行い、2番目の実験では6人の話し手がプレゼンテーションを行った。

フィラー条件はオレンジ色のボックスで示される。一般的に、フィラーの内容はシステムからの聴衆のフィードバックの増加に比例して減少した。
研究者は、1人の話し手のフィラーが著しく減少したことに注目し、「Condition CR-N」では、話し手はほとんどフィラーのフレーズを発しなかった。詳細な結果については、論文を参照してください。ただし、最も顕著な結果は、話し手と聴衆参加者からの主観的な評価にあった。
聴衆からのコメントには以下のようなものがあった:
「私はプレゼンテーションに関与している感じがした」[AN2]、「私は話し手のスピーチが改善されたかどうかはわかりませんでしたが、他の人の頭の動きの視覚化から統一感を感じた」[AN6]
「私は話し手のスピーチが改善されたかどうかはわかりませんでしたが、他の人の頭の動きの視覚化から統一感を感じた」
研究者は、システムが話し手のプレゼンテーションに新しい種類の人工的なパウーズを導入することに注目する。話し手は、進む前に聴衆のフィードバックを評価するために、視覚的なシステムを参照する傾向にある。
また、参加者がバイオメトリックデータのセキュリティ上の影響を心配するため、実験状況では避けられない「白いコート効果」も指摘する。
結論
このようなシステムの注目すべき利点は、使用後には、標準的な付加技術が完全に消え去ることである。ブラウザープラグインのアンインストールや、参加者がシステムに残っているかどうかを心配する必要はなく、ユーザーを導かれる必要もない(Webベースのフレームワークは、初期設定に1、2分かかる)。また、ローカルソフトウェアのインストールを許可するためのユーザーのガイダンスや、ユーザーがローカルソフトウェアをインストールするための適切な権限を持っていない可能性について心配する必要もない。
評価される顔の動きや眼球の動きは、専用のローカルマシンラーニングフレームワーク(YOLOシリーズなど)を使用する状況ほど正確ではないかもしれないが、このほぼ無摩擦のアプローチは、典型的なビデオ会議シナリオでの広範な感情や態度の分析に十分な精度を提供する。何よりも、非常に安価である。
詳細と例については、以下のプロジェクトビデオを参照してください。
初めて公開されたのは2022年4月11日。












