
Inteligencia artificial
ST-NeRF: composición y edición para síntesis de video

Un consorcio de investigación chino ha desarrollado técnicas para llevar las capacidades de edición y composición a uno de los sectores de investigación de síntesis de imágenes más populares del año pasado: Neural Radiance Fields (NeRF). El sistema se titula ST-NeRF (Campo de Radiancia Neural Coherente Espacio-Temporal).
Lo que parece ser una panorámica de cámara física en la imagen de abajo es en realidad solo un usuario 'desplazándose' a través de puntos de vista en contenido de video que existe en un espacio 4D. El punto de vista no se limita a la actuación de las personas representadas en el video, cuyos movimientos se pueden ver desde cualquier parte de un radio de 180 grados.

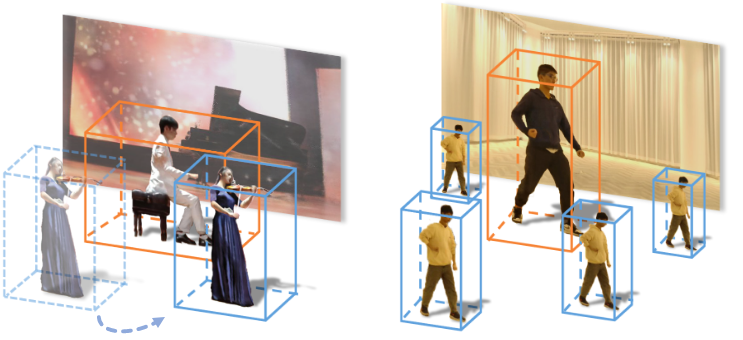
Cada faceta dentro del video es un elemento capturado discretamente, compuesto en una escena cohesiva que se puede explorar dinámicamente.
Las facetas se pueden duplicar libremente dentro de la escena o cambiar de tamaño:

Además, el comportamiento temporal de cada faceta se puede alterar, ralentizar, retroceder o manipular fácilmente de muchas maneras, lo que abre el camino a arquitecturas de filtros y un nivel extremadamente alto de interpretabilidad.

Dos facetas separadas de NeRF se ejecutan a diferentes velocidades en la misma escena. Fuente: https://www.youtube.com/watch?v=Wp4HfOwFGP4
No es necesario rotoscopiar a los artistas o los entornos, ni hacer que los artistas ejecuten sus movimientos a ciegas y fuera del contexto de la escena prevista. En cambio, las imágenes se capturan de forma natural a través de un conjunto de 16 cámaras de video que cubren 180 grados:


Los tres elementos representados arriba, las dos personas y el medio ambiente, son distintos y se describen solo con fines ilustrativos. Cada uno se puede intercambiar y cada uno se puede insertar en la escena en un punto anterior o posterior en su línea de tiempo de captura individual.
ST-NeRF es una innovación en la investigación de campos de radiación neuronal (NERF), un marco de aprendizaje automático mediante el cual las capturas de múltiples puntos de vista se sintetizan en un espacio virtual navegable mediante una capacitación exhaustiva (aunque la captura de un solo punto de vista también es un subsector de la investigación NeRF).

Neural Radiance Fields funciona mediante la recopilación de múltiples puntos de vista de captura en un solo espacio 3D coherente y navegable, con las brechas entre la cobertura estimada y representada por una red neuronal. Cuando se utiliza vídeo (en lugar de imágenes fijas), los recursos de representación necesarios suelen ser considerables. Fuente: https://www.matthewtancik.com/nerf
El interés en NeRF se ha vuelto intenso en los últimos nueve meses, y un informe mantenido por Reddit lista de documentos NeRF derivados o exploratorios enumera actualmente sesenta proyectos.

Solo algunas de las muchas ramificaciones del documento NeRF original. Fuente: https://crossminds.ai/graphlist/nerf-neural-radiance-fields-ai-research-graph-60708936c8663c4cfa875fc2/
Capacitación asequible
El documento es una colaboración entre investigadores de la Universidad Tecnológica de Shanghái y Tecnología digital DGene, y ha sido aceptado con cierto entusiasmo en revisión abierta.
ST-NeRF ofrece una serie de innovaciones sobre iniciativas anteriores en espacios de video navegables derivados de ML. No menos importante, logra un alto nivel de realismo con solo 16 cámaras. Aunque Facebook DyNeRF usa solo dos cámaras más que esto, ofrece un arco navegable mucho más restringido.

Un ejemplo del entorno DyNeRF de Facebook, con un campo de movimiento más limitado y se necesitan más cámaras por pie cuadrado para reconstruir la escena. Fuente: https://neural-3d-video.github.io
Además de carecer de la capacidad de editar y componer facetas individuales, DyNeRF es particularmente costoso en términos de recursos computacionales. Por el contrario, los investigadores chinos afirman que el costo de capacitación para sus datos oscila entre $ 900 y $ 3,000, en comparación con los $ 30,000 para el modelo de generación de video de última generación DVDGAN y sistemas intensivos como DyNeRF.
Los revisores también han notado que ST-NeRF hace una gran innovación al desacoplar el proceso de aprendizaje del movimiento del proceso de síntesis de imágenes. Esta separación es lo que permite editar y componer, con enfoques anteriores restrictivos y lineales en comparación.
Aunque 16 cámaras es una matriz muy limitada para un semicírculo de visión tan completo, los investigadores esperan reducir aún más este número en trabajos posteriores mediante el uso de fondos estáticos escaneados previamente por proxy y más enfoques de modelado de escenas basados en datos. También esperan incorporar capacidades de reencendido, un innovación reciente en la investigación NeRF.
Abordar las limitaciones de ST-NeRF
En el contexto de los artículos académicos de CS que tienden a desechar la usabilidad real de un nuevo sistema en un párrafo final descartable, incluso las limitaciones que los investigadores reconocen para ST-NeRF son inusuales.
Observan que el sistema actualmente no puede individualizar y representar por separado objetos particulares en una escena, porque las personas en el metraje están segmentadas en entidades individuales a través de un sistema diseñado para reconocer humanos y no objetos, un problema que parece resolverse fácilmente con YOLO y similares. marcos, con el trabajo más duro de extraer video humano ya realizado.
Aunque los investigadores señalan que actualmente no es posible generar cámara lenta, parece haber poco para evitar la implementación de esto utilizando las innovaciones existentes en la interpolación de fotogramas, como DAIN y ABUNDANTE.
Como ocurre con todas las implementaciones de NeRF, y en muchos otros sectores de la investigación de la visión por computadora, ST-NeRF puede fallar en casos de oclusión severa, donde el sujeto queda temporalmente oscurecido por otra persona o un objeto, y puede ser difícil rastrearlo continuamente o rastrearlo con precisión. volver a adquirirlo posteriormente. Como en otros lugares, es posible que esta dificultad deba esperar soluciones previas. Mientras tanto, los investigadores admiten que la intervención manual es necesaria en estos marcos ocluidos.
Finalmente, los investigadores observan que los procedimientos de segmentación humana actualmente se basan en diferencias de color, lo que podría conducir a la recopilación no intencional de dos personas en un bloque de segmentación, un obstáculo que no se limita a ST-NeRF, sino que es intrínseco a la biblioteca que se utiliza y que quizás podría resolverse mediante análisis de flujo óptico y otras técnicas emergentes.
Publicado por primera vez el 7 de mayo de 2021.















