
Inteligencia artificial
InstructIR: Restauración de imágenes de alta calidad siguiendo instrucciones humanas

Una imagen puede transmitir mucho, pero también puede verse afectada por diversos problemas, como el desenfoque de movimiento, la neblina, el ruido y el bajo rango dinámico. Estos problemas, comúnmente conocidos como degradaciones en la visión por computadora de bajo nivel, pueden surgir de condiciones ambientales difíciles como el calor o la lluvia o de las limitaciones de la propia cámara. La restauración de imágenes representa un desafío central en la visión por computadora, ya que se esfuerza por recuperar una imagen limpia y de alta calidad a partir de una que exhibe tales degradaciones. La restauración de imágenes es compleja porque puede haber múltiples soluciones para restaurar una imagen determinada. Algunos enfoques apuntan a degradaciones específicas, como reducir el ruido o eliminar el desenfoque o la neblina.
Si bien estos métodos pueden producir buenos resultados para problemas particulares, a menudo tienen dificultades para generalizar a diferentes tipos de degradación. Muchos marcos emplean una red neuronal genérica para una amplia gama de tareas de restauración de imágenes, pero cada una de estas redes se entrena por separado. La necesidad de diferentes modelos para cada tipo de degradación hace que este enfoque sea computacionalmente costoso y requiera mucho tiempo, lo que ha llevado a desarrollos recientes a centrarse en modelos de restauración todo en uno. Estos modelos utilizan un modelo de restauración único y profundo que aborda múltiples niveles y tipos de degradación, a menudo empleando indicaciones o vectores de guía específicos de la degradación para mejorar el rendimiento. Aunque los modelos todo en uno suelen mostrar resultados prometedores, todavía enfrentan desafíos con problemas inversos.
InstructIR representa un enfoque innovador en el campo, siendo el primero restauración de imagen marco diseñado para guiar el modelo de restauración a través de instrucciones escritas por humanos. Puede procesar indicaciones en lenguaje natural para recuperar imágenes de alta calidad a partir de imágenes degradadas, considerando varios tipos de degradación. InstructIR establece un nuevo estándar en rendimiento para un amplio espectro de tareas de restauración de imágenes, incluidas la eliminación del drenaje, la eliminación de ruido, la eliminación de neblina, la eliminación de borrosidades y la mejora de imágenes con poca luz.
Este artículo tiene como objetivo cubrir el marco InstructIR en profundidad y exploramos el mecanismo, la metodología y la arquitectura del marco junto con su comparación con los marcos de generación de imágenes y videos más modernos. Entonces empecemos.
InstructIR: Restauración de imágenes de alta calidad
La restauración de imágenes es un problema fundamental en la visión por computadora ya que tiene como objetivo recuperar una imagen limpia de alta calidad a partir de una imagen que demuestra degradaciones. En visión por computadora de bajo nivel, Degradaciones es un término utilizado para representar efectos desagradables observados dentro de una imagen, como desenfoque de movimiento, neblina, ruido, bajo rango dinámico y más. La razón por la que la restauración de imágenes es un desafío inverso complejo es porque pueden existir múltiples soluciones diferentes para restaurar cualquier imagen. Algunos marcos se centran en degradaciones específicas, como reducir el ruido de la instancia o eliminar el ruido de la imagen, mientras que otros pueden centrarse más en eliminar el desenfoque o la eliminación de desenfoque, o en eliminar la neblina o la eliminación de neblina.
Los métodos recientes de aprendizaje profundo han mostrado un rendimiento más sólido y consistente en comparación con los métodos tradicionales de restauración de imágenes. Estos modelos de restauración de imágenes de aprendizaje profundo proponen utilizar redes neuronales basadas en Transformers y Redes Neuronales Convolucionales. Estos modelos se pueden entrenar de forma independiente para diversas tareas de restauración de imágenes y también poseen la capacidad de capturar interacciones de características locales y globales y mejorarlas, lo que resulta en un rendimiento satisfactorio y consistente. Aunque algunos de estos métodos pueden funcionar adecuadamente para tipos específicos de degradación, normalmente no se extrapolan bien a diferentes tipos de degradación. Además, si bien muchos marcos existentes utilizan la misma red neuronal para una multitud de tareas de restauración de imágenes, cada formulación de red neuronal se entrena por separado. Por lo tanto, es obvio que emplear un modelo neuronal separado para cada degradación imaginable es impracticable y requiere mucho tiempo, razón por la cual los marcos de restauración de imágenes recientes se han concentrado en proxies de restauración todo en uno.
Los modelos de restauración de imágenes Todo en Uno o Multidegradación o Multitarea están ganando popularidad en el campo de la visión por computadora ya que son capaces de restaurar múltiples tipos y niveles de degradaciones en una imagen sin la necesidad de entrenar los modelos de forma independiente para cada degradación. . Los modelos de restauración de imágenes todo en uno utilizan un único modelo de restauración de imágenes ciego para abordar diferentes tipos y niveles de degradación de imágenes. Diferentes modelos Todo en Uno implementan diferentes enfoques para guiar el modelo ciego para restaurar la imagen degradada, por ejemplo, un modelo auxiliar para clasificar la degradación o vectores de guía multidimensionales o indicaciones para ayudar al modelo a restaurar diferentes tipos de degradación dentro de un imagen.
Dicho esto, llegamos a la manipulación de imágenes basada en texto, ya que ha sido implementada por varios marcos en los últimos años para la generación de texto a imagen y tareas de edición de imágenes basadas en texto. Estos modelos suelen utilizar indicaciones de texto para describir acciones o imágenes junto con modelos basados en difusión para generar las imágenes correspondientes. La principal inspiración para el marco InstructIR es el marco InstructPix2Pix que permite al modelo editar la imagen utilizando instrucciones de usuario que le indican al modelo qué acción realizar en lugar de etiquetas de texto, descripciones o leyendas de la imagen de entrada. Como resultado, los usuarios pueden utilizar textos escritos naturales para indicar al modelo qué acción realizar sin la necesidad de proporcionar imágenes de muestra o descripciones de imágenes adicionales.
Sobre la base de estos conceptos básicos, el marco InstructIR es el primer modelo de visión por computadora que emplea instrucciones escritas por humanos para lograr la restauración de imágenes y resolver problemas inversos. Para indicaciones en lenguaje natural, el modelo InstructIR puede recuperar imágenes de alta calidad de sus contrapartes degradadas y también tiene en cuenta múltiples tipos de degradación. El marco InstructIR es capaz de ofrecer un rendimiento de última generación en una amplia gama de tareas de restauración de imágenes, incluida la eliminación del drenaje, la eliminación de ruido, la eliminación de neblina, la eliminación de imágenes borrosas y la mejora de imágenes con poca luz. A diferencia de los trabajos existentes que logran la restauración de imágenes utilizando vectores de guía aprendidos o incrustaciones de mensajes, el marco InstructIR emplea mensajes de usuario sin formato en forma de texto. El marco InstructIR puede generalizarse para restaurar imágenes utilizando instrucciones escritas por humanos, y el modelo único todo en uno implementado por InstructIR cubre más tareas de restauración que los modelos anteriores. La siguiente figura muestra los diversos ejemplos de restauración del marco InstructIR.

InstructIR: método y arquitectura
En esencia, el marco InstructIR consta de un codificador de texto y un modelo de imagen. El modelo utiliza el marco NAFNet, un modelo eficiente de restauración de imágenes que sigue una arquitectura U-Net como modelo de imagen. Además, el modelo implementa técnicas de enrutamiento de tareas para aprender múltiples tareas utilizando un solo modelo con éxito. La siguiente figura ilustra el enfoque de capacitación y evaluación para el marco InstructIR.

Inspirándose en el modelo InstructPix2Pix, el marco InstructIR adopta instrucciones escritas por humanos como mecanismo de control, ya que no es necesario que el usuario proporcione información adicional. Estas instrucciones ofrecen una forma clara y expresiva de interactuar, permitiendo a los usuarios señalar la ubicación exacta y el tipo de degradación en la imagen. Además, el uso de indicaciones para el usuario en lugar de indicaciones específicas de degradación fija mejora la usabilidad y las aplicaciones del modelo, ya que también puede ser utilizado por usuarios que carecen de la experiencia en el dominio requerida. Para dotar al marco InstructIR de la capacidad de comprender diversas indicaciones, el modelo utiliza GPT-4, un modelo de lenguaje grande para crear diversas solicitudes, con indicaciones ambiguas y poco claras eliminadas después de un proceso de filtrado.
Codificador de texto
Los modelos de lenguaje utilizan un codificador de texto para asignar las indicaciones del usuario a una incrustación de texto o una representación vectorial de tamaño fijo. Tradicionalmente, el codificador de texto de un modelo CLIP es un componente vital para la generación de imágenes basadas en texto y modelos de manipulación de imágenes basados en texto para codificar indicaciones del usuario, ya que el marco CLIP sobresale en indicaciones visuales. Sin embargo, la mayoría de las veces, las indicaciones del usuario sobre degradación presentan poco o ningún contenido visual, por lo que los codificadores CLIP grandes son inútiles para tales tareas, ya que obstaculizarán significativamente la eficiencia. Para abordar este problema, el marco InstructIR opta por un codificador de oraciones basado en texto que está capacitado para codificar oraciones en un espacio de incrustación significativo. Los codificadores de oraciones están previamente entrenados en millones de ejemplos y, aún así, son compactos y eficientes en comparación con los codificadores de texto tradicionales basados en CLIP, al tiempo que tienen la capacidad de codificar la semántica de diversas indicaciones de usuario.
Guía de texto
Un aspecto importante del marco InstructIR es la implementación de la instrucción codificada como mecanismo de control para el modelo de imagen. Sobre la base de esto, e inspirado en el enrutamiento de tareas para muchas tareas de aprendizaje, el marco InstructIR propone un bloque de construcción de instrucciones o ICB para permitir transformaciones específicas de tareas dentro del modelo. El enrutamiento de tareas convencional aplica máscaras binarias específicas de tareas a las funciones del canal. Sin embargo, dado que el marco InstructIR no conoce la degradación, esta técnica no se implementa directamente. Además, para las características de la imagen y las instrucciones codificadas, el marco InstructIR aplica el enrutamiento de tareas y produce la máscara usando una capa lineal activada usando la función Sigmoide para producir un conjunto de pesos dependiendo de las incrustaciones de texto, obteniendo así una dimensión c por máscara binaria del canal. El modelo mejora aún más las funciones condicionadas utilizando un NAFBlock y utiliza el NAFBlock y el bloque condicionado de instrucción para condicionar las funciones tanto en el bloque codificador como en el bloque decodificador.
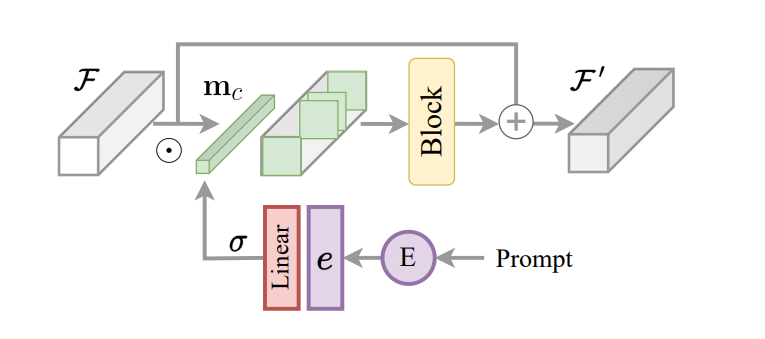
Aunque el marco InstructIR no condiciona explícitamente los filtros de la red neuronal, la máscara facilita que el modelo seleccione los canales más relevantes en función de la instrucción y la información de la imagen.
InstructIR: implementación y resultados
El modelo InstructIR se puede entrenar de un extremo a otro y el modelo de imagen no requiere entrenamiento previo. Sólo es necesario entrenar el texto que incorpora las proyecciones y el cabezal de clasificación. El codificador de texto se inicializa utilizando un codificador BGE, un codificador similar a BERT que está previamente entrenado con una gran cantidad de datos supervisados y no supervisados para la codificación de oraciones con fines genéricos. El marco InstructIR utiliza el modelo NAFNet como modelo de imagen, y la arquitectura de NAFNet consta de un codificador decodificador de 4 niveles con un número variable de bloques en cada nivel. El modelo también agrega 4 bloques intermedios entre el codificador y el decodificador para mejorar aún más las funciones. Además, en lugar de concatenar las conexiones de omisión, el decodificador implementa la suma y el modelo InstructIR implementa solo el ICB o bloque condicionado de instrucción para el enrutamiento de tareas solo en el codificador y el decodificador. Continuando, el modelo InstructIR se optimiza utilizando la pérdida entre la imagen restaurada y la imagen limpia de la verdad fundamental, y la pérdida de entropía cruzada se utiliza para la clasificación de intenciones del codificador de texto. El modelo InstructIR utiliza el optimizador AdamW con un tamaño de lote de 32 y una tasa de aprendizaje de 5e-4 durante casi 500 épocas, y también implementa la disminución de la tasa de aprendizaje por recocido de coseno. Dado que el modelo de imagen en el marco InstructIR comprende solo 16 millones de parámetros y solo hay 100 mil parámetros de proyección de texto aprendidos, el marco InstructIR se puede entrenar fácilmente en GPU estándar, lo que reduce los costos computacionales y aumenta la aplicabilidad.
Múltiples resultados de degradación
Para múltiples degradaciones y restauraciones multitarea, el marco InstructIR define dos configuraciones iniciales:
- 3D para modelos de tres degradación para abordar problemas de degradación como eliminación de neblina, eliminación de ruido y drenaje.
- 5D para cinco modelos de degradación para abordar problemas de degradación como eliminación de ruido de la imagen, mejoras con poca luz, eliminación de neblina, eliminación de ruido y eliminación de drenaje.
El rendimiento de los modelos 5D se demuestra en la siguiente tabla y se compara con la restauración de imágenes de última generación y los modelos todo en uno.

Como se puede observar, el marco InstructIR con un modelo de imagen simple y solo 16 millones de parámetros puede manejar con éxito cinco tareas diferentes de restauración de imágenes gracias a la guía basada en instrucciones y ofrece resultados competitivos. La siguiente tabla demuestra el rendimiento del marco en modelos 3D y los resultados son comparables a los resultados anteriores.

Lo más destacado del marco InstructIR es la restauración de imágenes basada en instrucciones, y la siguiente figura demuestra las increíbles capacidades del modelo InstructIR para comprender una amplia gama de instrucciones para una tarea determinada. Además, para una instrucción adversaria, el modelo InstructIR realiza una identidad que no es forzada.

Consideraciones Finales:
La restauración de imágenes es un problema fundamental en la visión por computadora ya que tiene como objetivo recuperar una imagen limpia de alta calidad a partir de una imagen que demuestra degradaciones. En visión por computadora de bajo nivel, Degradaciones es un término utilizado para representar efectos desagradables observados dentro de una imagen, como desenfoque de movimiento, neblina, ruido, bajo rango dinámico y más. En este artículo, hemos hablado de InstructIR, el primer marco de restauración de imágenes del mundo que tiene como objetivo guiar el modelo de restauración de imágenes utilizando instrucciones escritas por humanos. Para indicaciones en lenguaje natural, el modelo InstructIR puede recuperar imágenes de alta calidad de sus contrapartes degradadas y también tiene en cuenta múltiples tipos de degradación. El marco InstructIR es capaz de ofrecer un rendimiento de última generación en una amplia gama de tareas de restauración de imágenes, incluida la eliminación del drenaje, la eliminación de ruido, la eliminación de neblina, la eliminación de imágenes borrosas y la mejora de imágenes con poca luz.















