KI 101
Was ist Bayes-Theorem?
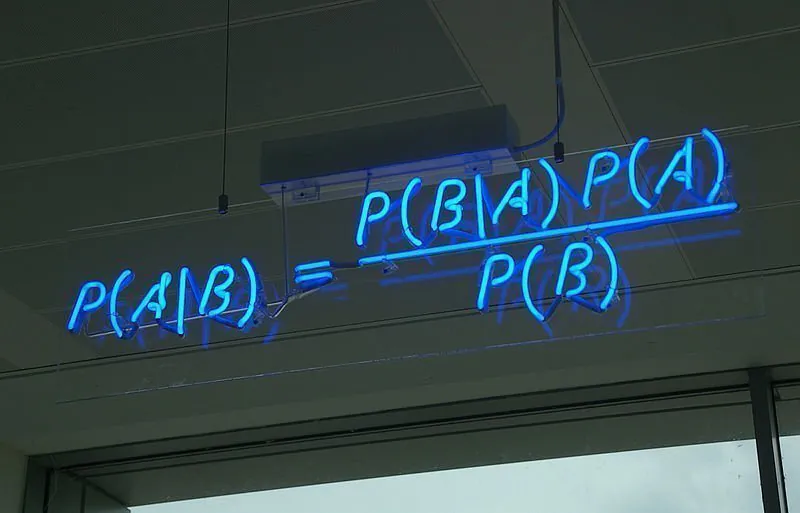
Wenn Sie über Data Science oder Machine Learning gelernt haben, besteht eine gute Chance, dass Sie den Begriff “Bayes-Theorem” oder einen “Bayes-Klassifizierer” bereits gehört haben. Diese Konzepte können etwas verwirrend sein, besonders wenn Sie nicht daran gewöhnt sind, über Wahrscheinlichkeit aus einer traditionellen, frequentistischen Statistik-Perspektive nachzudenken. Dieser Artikel wird versuchen, die Prinzipien hinter dem Bayes-Theorem und seine Verwendung in der maschinellen Lerntheorie zu erklären.
Was ist Bayes-Theorem?
Bayes-Theorem ist eine Methode zur Berechnung der bedingten Wahrscheinlichkeit. Die traditionelle Methode zur Berechnung der bedingten Wahrscheinlichkeit (die Wahrscheinlichkeit, dass ein Ereignis eintritt, wenn ein anderes Ereignis eintritt) besteht darin, die bedingte Wahrscheinlichkeitsformel zu verwenden, die gemeinsame Wahrscheinlichkeit von Ereignis eins und Ereignis zwei zu berechnen und diese dann durch die Wahrscheinlichkeit von Ereignis zwei zu teilen. Die bedingte Wahrscheinlichkeit kann jedoch auch auf eine leicht andere Weise mit Bayes-Theorem berechnet werden.
Bei der Berechnung der bedingten Wahrscheinlichkeit mit Bayes-Theorem werden die folgenden Schritte verwendet:
- Bestimmen Sie die Wahrscheinlichkeit, dass Bedingung B wahr ist, wenn Bedingung A wahr ist.
- Bestimmen Sie die Wahrscheinlichkeit, dass Ereignis A wahr ist.
- Multiplizieren Sie die beiden Wahrscheinlichkeiten miteinander.
- Teilen Sie durch die Wahrscheinlichkeit, dass Ereignis B eintritt.
Dies bedeutet, dass die Formel für Bayes-Theorem wie folgt ausgedrückt werden kann:
P(A|B) = P(B|A)*P(A) / P(B)
Die Berechnung der bedingten Wahrscheinlichkeit auf diese Weise ist besonders nützlich, wenn die umgekehrte bedingte Wahrscheinlichkeit leicht berechnet werden kann oder wenn die Berechnung der gemeinsamen Wahrscheinlichkeit zu schwierig wäre.
Beispiel für Bayes-Theorem
Dies könnte einfacher zu interpretieren sein, wenn wir uns ein Beispiel ansehen, wie man bayessche Argumentation und Bayes-Theorem anwendet. Nehmen wir an, Sie spielen ein einfaches Spiel, bei dem mehrere Teilnehmer Ihnen eine Geschichte erzählen und Sie bestimmen müssen, welcher der Teilnehmer Ihnen gegenüber lügt. Füllen wir die Gleichung für Bayes-Theorem mit den Variablen in diesem hypothetischen Szenario aus.
Wir versuchen, vorherzusagen, ob jeder Einzelne im Spiel lügt oder die Wahrheit sagt, sodass die kategorischen Variablen als A1, A2 und A3 ausgedrückt werden können. Der Beweis für ihre Lügen/Wahrheit ist ihr Verhalten. Ähnlich wie beim Pokern würden Sie nach bestimmten “Tells” suchen, die darauf hindeuten, dass eine Person lügt, und diese als Informationen verwenden, um Ihre Vermutung zu informieren. Oder wenn Sie sie befragen dürften, wäre es jeder Beweis, dass ihre Geschichte nicht zusammenpasst. Wir können den Beweis, dass eine Person lügt, als B darstellen.
Um klar zu sein, wir zielen darauf ab, die Wahrscheinlichkeit zu berechnen, dass A lügt/die Wahrheit sagt, gegeben den Beweis ihres Verhaltens. Dazu möchten wir die Wahrscheinlichkeit von B ermitteln, gegeben A, oder die Wahrscheinlichkeit, dass ihr Verhalten auftritt, wenn die Person wirklich lügt oder die Wahrheit sagt. Sie versuchen, unter welchen Bedingungen das Verhalten, das Sie beobachten, am meisten Sinn ergibt. Wenn es drei Verhaltensweisen gibt, die Sie beobachten, würden Sie die Berechnung für jedes Verhalten durchführen. Zum Beispiel P(B1, B2, B3 * A). Sie würden dies für jeden Vorkommensfall von A/den jeder Person im Spiel außer Ihnen tun. Das ist dieser Teil der Gleichung oben:
P(B1, B2, B3,|A) * P|A
Schließlich teilen wir dies durch die Wahrscheinlichkeit von B.
Wenn wir irgendwelche Beweise über die tatsächlichen Wahrscheinlichkeiten in dieser Gleichung erhalten, würden wir unser Wahrscheinlichkeitsmodell neu erstellen und die neuen Beweise berücksichtigen. Dies wird als Aktualisierung der Vorprioritäten bezeichnet, da Sie Ihre Annahmen über die vorherige Wahrscheinlichkeit der beobachteten Ereignisse aktualisieren.
Machine-Learning-Anwendungen für Bayes-Theorem
Die häufigste Verwendung von Bayes-Theorem bei der maschinellen Lerntheorie ist in Form des Naive-Bayes-Algorithmus.
Naive Bayes wird für die Klassifizierung von binären und multiklassigen Datensätzen verwendet. Naive Bayes erhält seinen Namen, weil die Werte, die den Zeugenbeweisen/Attributen – Bs in P(B1, B2, B3 * A) – zugewiesen werden, als unabhängig voneinander angenommen werden. Es wird angenommen, dass diese Attribute sich nicht gegenseitig beeinflussen, um das Modell zu vereinfachen und die Berechnungen möglich zu machen, anstatt den komplexen Aufgaben zu versuchen, die Beziehungen zwischen jedem der Attribute zu berechnen. Trotz dieses vereinfachten Modells tendiert Naive Bayes dazu, als Klassifizierungsalgorithmus recht gut zu funktionieren, auch wenn diese Annahme wahrscheinlich nicht wahr ist (was meistens der Fall ist).
Es gibt auch häufig verwendete Varianten des Naive-Bayes-Klassifizierers, wie Multinomial Naive Bayes, Bernoulli Naive Bayes und Gaussian Naive Bayes.
Multinomial Naive Bayes-Algorithmen werden oft zur Klassifizierung von Dokumenten verwendet, da sie effektiv darin sind, die Häufigkeit von Wörtern in einem Dokument zu interpretieren.
Bernoulli Naive Bayes funktioniert ähnlich wie Multinomial Naive Bayes, aber die Vorhersagen, die der Algorithmus liefert, sind boolesch. Das bedeutet, dass die Werte, wenn eine Klasse vorhergesagt wird, binär sind, nein oder ja. Im Bereich der Textklassifizierung würde ein Bernoulli-Naive-Bayes-Algorithmus die Parameter mit einem Ja oder Nein basierend darauf zuweisen, ob ein Wort im Textdokument gefunden wird.
Wenn der Wert der Prädiktoren/Merkmale nicht diskret, sondern kontinuierlich ist, kann Gaussian Naive Bayes verwendet werden. Es wird angenommen, dass die Werte, die die kontinuierlichen Merkmale haben, aus einer gaußschen Verteilung stammen.












