Künstliche Intelligenz
Die Gefahren der Verwendung von Zitaten zur Authentifizierung von NLG-Inhalten

Meinung Natural Language Generation-Modelle wie GPT-3 sind anfällig für ‘Halluzinationen’ von Material, das sie im Kontext von faktischen Informationen präsentieren. In einer Ära, die sich außerordentlich um das Wachstum von textbasierten Falschmeldungen sorgt, stellen diese ‘eifrigen’ Flügen der Fantasie eine existenzielle Hürde für die Entwicklung von automatisierten Schreib- und Zusammenfassungssystemen und für die Zukunft von AI-getriebener Journalismus dar, sowie für verschiedene andere Subsektoren der Natural Language Processing (NLP).
Das zentrale Problem ist, dass GPT-ähnliche Sprachmodelle wichtige Merkmale und Klassen aus sehr großen Korpora von TrainingsTexten ableiten und lernen, diese Merkmale als Bausteine der Sprache geschickt und authentisch zu verwenden, unabhängig von der Genauigkeit des generierten Inhalts oder sogar seiner Akzeptanz .
NLG-Systeme verlassen sich daher derzeit auf die menschliche Überprüfung von Fakten in einem von zwei Ansätzen: Entweder werden die Modelle als Seed-Text-Generatoren verwendet, die sofort an menschliche Benutzer weitergeleitet werden, entweder zur Überprüfung oder zu einer anderen Form der Bearbeitung oder Anpassung; oder es werden Menschen als teure Filter verwendet, um die Qualität von Datensätzen zu verbessern, die weniger abstrakte und ‘kreative’ Modelle informieren sollen (die selbst noch immer schwierig zu vertrauen sind, was die faktische Genauigkeit betrifft, und die weitere Schichten der menschlichen Überwachung erfordern).
Alte Nachrichten und Falsche Fakten
Natural Language Generation (NLG)-Modelle sind in der Lage, überzeugende und plausible Ausgaben zu produzieren, weil sie semantische Architektur gelernt haben, anstatt abstrakter die tatsächliche Geschichte, Wissenschaft, Wirtschaft oder jedes andere Thema zu assimilieren, über das sie möglicherweise urteilen müssen, das effektiv in den Quelldaten ‘verpackt’ ist.
Die faktische Genauigkeit der von NLG-Modellen generierten Informationen geht davon aus, dass die Eingabe, auf der sie trainiert werden, selbst zuverlässig und aktuell ist, was einen außerordentlichen Aufwand in Bezug auf Vorverarbeitung und weitere menschliche Überprüfung darstellt – ein kostspieliges Hindernis, das der NLP-Forschungssektor derzeit auf vielen Fronten angeht.
GPT-3-ähnliche Systeme benötigen eine enorme Menge an Zeit und Geld für das Training, und sobald sie trainiert sind, sind sie schwierig zu aktualisieren, was als ‘Kern’-Ebene betrachtet werden kann. Obwohl sessionbasierte und benutzerbasierte lokale Modifikationen die Nützlichkeit und Genauigkeit der implementierten Modelle erhöhen können, sind diese nützlichen Vorteile schwierig, manchmal unmöglich, an das Kernmodell zurückzugeben, ohne eine vollständige oder teilweise Neuschulung zu erfordern.
Deshalb ist es schwierig, trainierte Sprachmodelle zu erstellen, die die neuesten Informationen nutzen können.

Trainiert vor dem Beginn der COVID-19-Pandemie, kann text-davinci-002 – die Iteration von GPT-3, die von seinem Ersteller OpenAI als ‘am fähigsten’ betrachtet wird – 4000 Token pro Anfrage verarbeiten, aber nichts über COVID-19 oder den ukrainischen Einmarsch 2022 (diese Prompts und Antworten sind vom 5. April 2022). Interessanterweise ist ‘unbekannt’ tatsächlich eine akzeptable Antwort in beiden Fällen des Scheiterns, aber weitere Prompts können leicht feststellen, dass GPT-3 nichts über diese Ereignisse weiß. Quelle: https://beta.openai.com/playground
Ein trainiertes Modell kann nur auf ‘Wahrheiten’ zugreifen, die es während des Trainings internalisiert hat, und es ist schwierig, ein genaues und relevantes Zitat standardmäßig zu erhalten, wenn man versucht, das Modell dazu zu bringen, seine Behauptungen zu überprüfen. Die wahre Gefahr bei der Erlangung von Zitaten aus dem Standard-GPT-3 (zum Beispiel) besteht darin, dass es manchmal korrekte Zitate produziert, was zu einer falschen Zuversicht in dieser Facette seiner Fähigkeiten führt:

Oben, drei genaue Zitate, die von der 2021er-Version von davinci-instruct-text GPT-3 erhalten wurden. Mitte, GPT-3 kann nicht eines von Einsteins berühmtesten Zitaten ("Gott spielt nicht mit dem Universum") zitieren, trotz eines nicht-kryptischen Prompts. Unten, GPT-3 weist ein skandalöses und fiktives Zitat Albert Einstein zu, offensichtlich ein Überbleibsel von früheren Fragen über Winston Churchill in der gleichen Sitzung. Quelle: Der Artikel des Autors aus dem Jahr 2021 auf https://www.width.ai/post/business-applications-for-gpt-3
GopherCite
Um diese allgemeine Schwäche in NLG-Modellen zu adressieren, hat Google’s DeepMind kürzlich GopherCite vorgeschlagen, ein 280-Milliarden-Parameter-Modell, das in der Lage ist, spezifische und genaue Beweise für seine generierten Antworten auf Prompts zu zitieren.



Drei Beispiele für GopherCite, das seine Behauptungen mit echten Zitaten belegt. Quelle: https://arxiv.org/pdf/2203.11147.pdf
GopherCite nutzt das Reinforcement Learning von menschlichen Präferenzen (RLHP), um Abfrage-Modelle zu trainieren, die in der Lage sind, echte Zitate als Beweise zu zitieren. Die Zitate werden live aus mehreren Dokumentenquellen abgerufen, die aus Suchmaschinen stammen oder von einem bestimmten Dokument, das vom Benutzer bereitgestellt wird.
Die Leistung von GopherCite wurde durch menschliche Bewertung der Modellantworten gemessen, die 80% der Zeit auf Googles NaturalQuestions-Datensatz und 67% der Zeit auf dem ELI5-Datensatz als ‘hochwertig’ bewertet wurden.
Zitieren von Falschheiten
Jedoch wurden GopherCites Antworten bei der Bewertung gegen das TruthfulQA-Benchmark der Universität Oxford nur selten als wahrheitsgetreu bewertet, im Vergleich zu den menschlich kuratierten ‘korrekten’ Antworten.
Die Autoren schlagen vor, dass dies daran liegt, dass das Konzept von ‘unterstützten Antworten’ nicht objektiv die Wahrheit definiert, da die Nützlichkeit von Quellenzitaten durch andere Faktoren beeinträchtigt werden kann, wie die Möglichkeit, dass der Autor des Zitats selbst ‘halluziniert’ (d. h. über fiktive Welten schreibt, Werbeinhalte produziert oder auf andere Weise unechte Materialien erstellt).



Fälle von GopherCite, in denen Plausibilität nicht unbedingt ‘Wahrheit’ bedeutet.
Effektiv wird es notwendig, zwischen ‘unterstützt’ und ‘wahr’ zu unterscheiden. Die menschliche Kultur ist derzeit weit fortgeschrittener als das maschinelle Lernen in Bezug auf die Verwendung von Methoden und Rahmenbedingungen, die darauf abzielen, objektive Definitionen von Wahrheit zu erhalten, und selbst dort scheint der natürliche Zustand von ‘wichtiger’ Wahrheit Streit und marginale Ablehnung zu sein.
Das Problem ist rekursiv in NLG-Architekturen, die darauf abzielen, definitive ‘bestätigende’ Mechanismen zu entwickeln: menschliche Konsensbildung wird als Benchmark der Wahrheit eingesetzt, die durch ausgelagerte, AMT-ähnliche Modelle erfolgt, bei denen die menschlichen Bewertungsexperten (und die anderen Menschen, die zwischen ihnen vermitteln) selbst Teilnehmer und voreingenommen sind.
Zum Beispiel verwenden die anfänglichen GopherCite-Experimente ein ‘Super-Rater’-Modell, um die besten menschlichen Testteilnehmer auszuwählen, um die Ausgabe des Modells zu bewerten, und wählen nur die Rater aus, die mindestens 85% im Vergleich zu einem Qualitätssicherungsset erreicht haben. Schließlich wurden 113 Super-Rater für die Aufgabe ausgewählt.
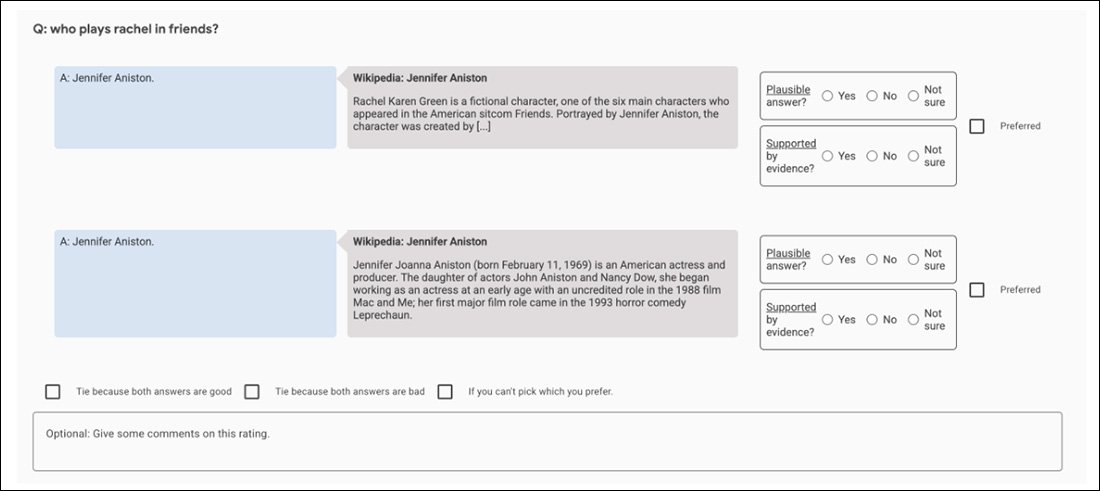
Screenshot der Vergleichs-App, die zur Bewertung der Ausgabe von GopherCite verwendet wird.
Man kann argumentieren, dass dies ein perfektes Bild einer ungewinnbaren fraktalen Verfolgung ist: die Qualitätssicherungsset, die zur Bewertung der Rater verwendet wird, ist selbst ein weiterer ‘menschlich definierten’ Maßstab der Wahrheit, wie auch die Oxford TruthfulQA-Set, gegen die GopherCite als mangelhaft befunden wurde.
In Bezug auf unterstützte und ‘authentifizierte’ Inhalte kann NLG-Systeme nur menschliche Ungleichheit und Vielfalt synthetisieren, die selbst ein schlecht gestelltes und ungelöstes Problem darstellt. Wir haben eine angeborene Tendenz, Quellen zu zitieren, die unsere Standpunkte unterstützen, und mit Überzeugung und Autorität zu sprechen, wenn unsere Quelleninformation möglicherweise veraltet, völlig ungenau oder auf andere Weise absichtlich falsch dargestellt ist; und eine Neigung, diese Standpunkte direkt in die Wildnis zu verbreiten, in einem Maß und einer Effizienz, die in der menschlichen Geschichte unübertroffen sind, direkt in den Weg der Wissensscraping-Frameworks, die neue NLG-Frameworks füttern.
Deshalb scheint die Gefahr, die mit der Entwicklung von zitiergestützten NLG-Systemen verbunden ist, mit der unvorhersehbaren Natur des Quellenmaterials verbunden zu sein. Jeder Mechanismus (wie direktes Zitieren und Zitate), der das Vertrauen des Benutzers in die NLG-Ausgabe erhöht, ist, im aktuellen Stand der Technik, gefährlich, da er der Authentizität, aber nicht der Wahrheit der Ausgabe hinzufügt.
Solche Techniken sind wahrscheinlich nützlich, wenn NLP schließlich die fiktionalen ‘Kaleidoskope’ von Orwells Nineteen Eighty-Four neu erschafft; aber sie stellen eine gefährliche Verfolgung für objektive Dokumentenanalyse, AI-zentrierten Journalismus und andere mögliche ‘nicht-fiktionale’ Anwendungen von maschineller Zusammenfassung und spontaner oder geleiteter Textgenerierung dar.
Erstveröffentlicht am 5. April 2022. Aktualisiert um 15:29 Uhr EET, um den Begriff zu korrigieren.












