
Künstliche Intelligenz
Klebet DALL-E 2 nur Dinge zusammen, ohne ihre Beziehungen zu verstehen?

Eine neue Forschungsarbeit der Harvard University legt nahe, dass das schlagzeilenträchtige Text-zu-Bild-Framework DALL-E 2 von OpenAI erhebliche Schwierigkeiten hat, selbst kindliche Beziehungen zwischen den Elementen, die es zu synthetisierten Fotos zusammensetzt, zu reproduzieren, trotz der erstaunlichen Raffinesse vieler davon seine Ausgabe.
Die Forscher führten eine Benutzerstudie mit 169 Crowdsourcing-Teilnehmern durch, denen DALL-E 2-Bilder präsentiert wurden, die auf den grundlegendsten menschlichen Prinzipien der Beziehungssemantik basierten, zusammen mit den Textaufforderungen, die sie erstellt hatten. Auf die Frage, ob die Aufforderungen und die Bilder zusammenhängen, wurden weniger als 22 % der Bilder als relevant für die zugehörigen Aufforderungen wahrgenommen, im Hinblick auf die sehr einfachen Beziehungen, die DALL-E 2 visualisieren sollte.

Ein Screenshot der für das neue Papier durchgeführten Versuche. Die Teilnehmer wurden beauftragt, alle Bilder auszuwählen, die der Aufforderung entsprachen. Trotz des Haftungsausschlusses am unteren Rand der Benutzeroberfläche wurden die Bilder in allen Fällen, ohne dass die Teilnehmer es wussten, tatsächlich aus der angezeigten zugehörigen Eingabeaufforderung generiert. Quelle: https://arxiv.org/pdf/2208.00005.pdf
Die Ergebnisse deuten auch darauf hin, dass die offensichtliche Fähigkeit von DALL-E, unterschiedliche Elemente zu verbinden, abnehmen könnte, da die Wahrscheinlichkeit sinkt, dass diese Elemente in den realen Trainingsdaten, die das System antreiben, vorkommen.
Beispielsweise erzielten Bilder für die Aufforderung „Kind berührt eine Schüssel“ eine Zustimmungsrate von 87 % (d. h. die Teilnehmer klickten auf die meisten Bilder, die für die Aufforderung relevant waren), wohingegen ähnlich fotorealistische Darstellungen von „Ein Affe berührt einen Leguan“ erzielt wurden nur 11 % Zustimmung:


DALL-E hat Mühe, das unwahrscheinliche Ereignis „ein Affe, der einen Leguan berührt“ darzustellen, wohl weil es im Trainingsset ungewöhnlich und wahrscheinlich gar nicht vorhanden ist.
Im zweiten Beispiel misst DALL-E 2 häufig den Maßstab und sogar die Art, was vermutlich auf einen Mangel an Bildern aus der realen Welt zurückzuführen ist, die dieses Ereignis darstellen. Im Gegensatz dazu ist davon auszugehen, dass es eine große Anzahl an Schulungsfotos zum Thema Kinder und Essen gibt und dass diese Unterdomäne/Klasse gut entwickelt ist.
Die Schwierigkeit von DALL-E bei der Gegenüberstellung stark kontrastierender Bildelemente deutet darauf hin, dass die Öffentlichkeit derzeit von den fotorealistischen und umfassenden Interpretationsfähigkeiten des Systems so geblendet ist, dass sie kein kritisches Auge für Fälle entwickelt hat, in denen das System ein Element praktisch nur stark an ein anderes „geklebt“ hat , wie in diesen Beispielen von der offiziellen DALL-E 2-Website:

Cut-and-Paste-Synthese aus den offiziellen Beispielen für DALL-E 2. Quelle: https://openai.com/dall-e-2/
Im neuen Papier heißt es*:
„Relationales Verständnis ist ein grundlegender Bestandteil der menschlichen Intelligenz, der sich manifestiert früh in der Entwicklungund wird schnell und automatisch berechnet in der Wahrnehmung.
Die Schwierigkeiten von „DALL-E 2“ selbst mit grundlegenden räumlichen Beziehungen (wie z in, on, für) deutet darauf hin, dass es, was auch immer es gelernt hat, noch nicht die Art von Darstellungen gelernt hat, die es dem Menschen ermöglichen, die Welt so flexibel und robust zu strukturieren.
„Eine direkte Interpretation dieser Schwierigkeit ist, dass Systeme wie DALL-E 2 noch nicht über relationale Kompositionalität verfügen.“
Die Autoren schlagen vor, dass textgesteuerte Bilderzeugungssysteme wie die DALL-E-Serie von der Nutzung von in der Robotik üblichen Algorithmen profitieren könnten, die Identitäten und Beziehungen gleichzeitig modellieren, da der Agent tatsächlich mit der Umgebung interagieren muss, anstatt nur etwas zu fabrizieren eine Mischung aus verschiedenen Elementen.
Ein solcher Ansatz mit dem Titel CLIPort, verwendet dasselbe CLIP-Mechanismus das als Qualitätsbewertungselement in DALL-E 2 dient:
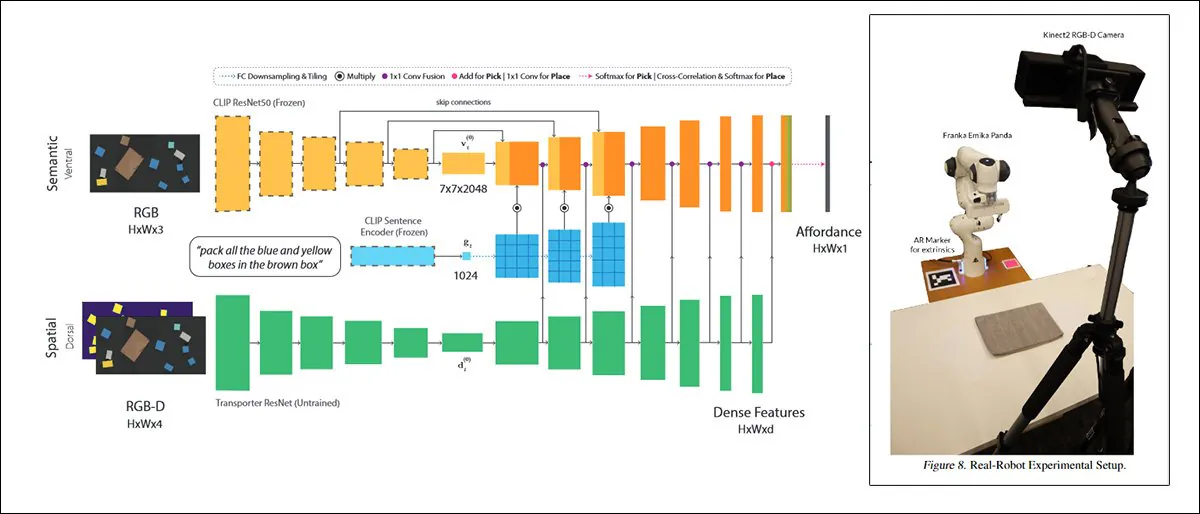
CLIPort, eine Zusammenarbeit zwischen der University of Washington und NVIDIA im Jahr 2021, nutzt CLIP in einem so praktischen Kontext, dass die darauf trainierten Systeme notwendigerweise ein Verständnis für physikalische Zusammenhänge entwickeln müssen, ein Motivator, der in DALL-E 2 fehlt und ähnlich „fantastisch“ ist. Bildsynthese-Frameworks. Quelle: https://arxiv.org/pdf/2109.12098.pdf
Die Autoren schlagen außerdem vor, dass „ein weiteres plausibles Upgrade“ darin bestehen könnte, die Architektur von Bildsynthesesystemen wie DALL-E zu integrieren multiplikative Effekte in einer einzigen Rechenschicht, die die Berechnung von Beziehungen auf eine Weise ermöglicht, die von den Informationsverarbeitungskapazitäten von inspiriert ist und mit einander verheirateten Systeme.
Der neues Papier ist betitelt Testen des relationalen Verständnisses bei der textgesteuerten Bildgenerierungund stammt von Colin Conwell und Tomer D. Ullman vom Department of Psychology der Harvard University.
Jenseits der frühen Kritik
Die Autoren kommentieren die „Taschenspielertricks“ hinter dem Realismus und der Integrität der Ausgabe von DALL-E 2 und weisen auf frühere Arbeiten hin, bei denen Mängel in generativen Bildsystemen im DALL-E-Stil festgestellt wurden.
Im Juni dieses Jahres, UoC Berkeley bekannt die Schwierigkeiten, die DALL-E beim Umgang mit Reflexionen und Schatten hat; Im selben Monat untersuchte eine Studie aus Korea die „Einzigartigkeit“ und Originalität der Ausgabe im DALL-E 2-Stil mit kritischem Blick, Ein Voruntersuchung von DALL-E 2-Bildern, kurz nach dem Start, von der NYU und der University of Texas, fanden verschiedene Probleme mit der Komposition und anderen wesentlichen Faktoren in DALL-E 2-Bildern; und letzten Monat, eine gemeinsame Arbeit zwischen der University of Illinois und dem MIT bot Vorschläge für architektonische Verbesserungen solcher Systeme im Hinblick auf die Kompositionalität an.
Die Forscher stellen außerdem fest, dass DALL-E-Koryphäen wie Aditya Ramesh dies getan haben räumte die Probleme des Frameworks mit Bindung, relativer Größe, Text und anderen Herausforderungen.
Auch die Entwickler von Googles konkurrierendem Bildsynthesesystem Imagen haben einen Vorschlag gemacht DrawBank, ein neuartiges Vergleichssystem, das die Bildgenauigkeit über Frameworks hinweg mit unterschiedlichen Metriken misst.
Stattdessen schlagen die Autoren des neuen Papiers vor, dass ein besseres Ergebnis erzielt werden könnte, wenn man menschliche Einschätzungen – und nicht interne, algorithmische Metriken – mit den resultierenden Bildern vergleicht, um herauszufinden, wo die Schwächen liegen und was getan werden könnte, um sie zu mildern.
Die Studie
Zu diesem Zweck basiert der Ansatz des neuen Projekts auf psychologischen Prinzipien und versucht, sich vom Strom zurückzuziehen Anstieg des Interesses in schnelles Engineering (was in der Tat ein Zugeständnis an die Mängel von DALL-E 2 oder einem vergleichbaren System darstellt), um die Einschränkungen zu untersuchen und möglicherweise anzugehen, die solche „Problemumgehungen“ erforderlich machen.
Das Papier sagt:
„Die aktuelle Arbeit konzentriert sich auf eine Reihe von 15 grundlegenden Beziehungen, die zuvor in der kognitiven, entwicklungsbezogenen oder linguistischen Literatur beschrieben, untersucht oder vorgeschlagen wurden.“ Die Menge enthält sowohl begründete räumliche Beziehungen (z. B. „X auf Y“) als auch abstraktere Agentenbeziehungen (z. B. „X hilft Y“).
„Die Eingabeaufforderungen sind bewusst einfach, ohne Attributkomplexität oder Ausarbeitung.“ Das heißt, anstelle einer Aufforderung wie „Ein Esel und ein Oktopus spielen ein Spiel.“ An einem Ende hält der Esel ein Seil, am anderen hält sich der Oktopus fest. Der Esel hält das Seil im Maul. „Eine Katze springt über das Seil“, wir verwenden „eine Kiste auf einem Messer“.
„Die Einfachheit erfasst immer noch ein breites Spektrum an Beziehungen aus verschiedenen Teilbereichen der menschlichen Psychologie und macht potenzielle Modellfehler auffälliger und spezifischer.“
Für ihre Studie rekrutierten die Autoren 169 Teilnehmer von Prolific, alle mit Sitz in den USA, mit einem Durchschnittsalter von 33 Jahren und 59 % Frauen.
Den Teilnehmern wurden 18 Bilder gezeigt, die in einem 3×6-Raster angeordnet waren, mit der Eingabeaufforderung oben und einem Haftungsausschluss unten, der besagte, dass alle, einige oder keine der Bilder möglicherweise aus der angezeigten Eingabeaufforderung generiert wurden, und wurden dann dazu aufgefordert Wählen Sie die Bilder aus, von denen sie glauben, dass sie auf diese Weise zusammenhängen.
Die den Individuen präsentierten Bilder basierten auf sprachlicher, entwicklungsbezogener und kognitiver Literatur und umfassten eine Reihe von acht physischen und sieben „agentischen“ Beziehungen (dies wird gleich klar werden).
Körperliche Beziehungen
in, auf, unter, bedeckend, nahe, verdeckt durch, hängend, und gebunden.
Agentenbeziehungen
schieben, ziehen, berühren, schlagen, treten, helfen, und behindernd.
Alle diese Beziehungen wurden aus den zuvor genannten Nicht-CS-Studienbereichen abgeleitet.
Auf diese Weise wurden zwölf Entitäten zur Verwendung in den Eingabeaufforderungen abgeleitet, mit sechs Objekten und sechs Agenten:
Objekte
Schachtel, Zylinder, Decke, Schüssel, Teetasse, und Messer.
Makler
Mann, Frau, Kind, Roboter, Affe, und Leguan.
(Die Forscher geben zu, dass die Einbeziehung des Leguans, der kein Hauptbestandteil der trockenen soziologischen oder psychologischen Forschung ist, „ein Vergnügen“ war.)
Für jede Beziehung wurden fünf verschiedene Eingabeaufforderungen erstellt, indem zwei Entitäten fünfmal zufällig ausgewählt wurden, was insgesamt 75 Eingabeaufforderungen ergab, von denen jede an DALL-E 2 übermittelt wurde und für die jeweils die ursprünglich 18 bereitgestellten Bilder ohne Variationen verwendet wurden oder zweite Chancen erlaubt.
Ergebnisse
In dem Papier heißt es*:
„Die Teilnehmer gaben im Durchschnitt eine geringe Übereinstimmung zwischen den Bildern von DALL-E 2 und den Eingabeaufforderungen an, die zu ihrer Erstellung verwendet wurden, mit einem Mittelwert von 22.2 % [18.3, 26.6] bei den 75 verschiedenen Eingabeaufforderungen.“
„Agentische Eingabeaufforderungen erzeugten mit einem Mittelwert von 28.4 % [22.8, 34.2] bei 35 Eingabeaufforderungen eine höhere Zustimmung als physische Eingabeaufforderungen mit einem Mittelwert von 16.9 % [11.9, 23.0] bei 40 Eingabeaufforderungen.“

Ergebnisse der Studie. Punkte in Schwarz kennzeichnen alle Eingabeaufforderungen, wobei jeder Punkt eine einzelne Eingabeaufforderung ist, und die Farbe gliedert sich danach, ob es sich bei dem Eingabeaufforderungssubjekt um einen Agenten oder ein physisches Objekt handelte.
Um den Unterschied zwischen menschlicher und algorithmischer Wahrnehmung der Bilder zu vergleichen, ließen die Forscher ihre Renderings über OpenAIs Open Source laufen ViT-L/14 CLIP-basiertes Framework. Beim Mitteln der Ergebnisse stellten sie einen „mäßigen Zusammenhang“ zwischen den beiden Ergebnissätzen fest, was vielleicht überraschend ist, wenn man bedenkt, inwieweit CLIP selbst bei der Generierung der Bilder hilft.

Ergebnisse des CLIP (ViT-L/14)-Vergleichs mit menschlichen Reaktionen.
Die Forscher vermuten, dass andere Mechanismen innerhalb der Architektur, möglicherweise kombiniert mit einem zufälligen Überwiegen (oder Fehlen) von Daten im Trainingssatz, dafür verantwortlich sein könnten, dass CLIP die Einschränkungen von DALL-E erkennen kann, ohne in jedem Fall etwas tun zu können viel über das Problem.
Die Autoren kommen zu dem Schluss, dass DALL-E 2, wenn überhaupt, nur eine fiktive Fähigkeit besitzt, Bilder zu reproduzieren, die relationales Verständnis beinhalten, eine grundlegende Facette der menschlichen Intelligenz, die sich in uns sehr früh entwickelt.
„Die Vorstellung, dass Systeme wie DALL-E 2 nicht über Kompositionalität verfügen, dürfte jeden überraschen, der die auffallend vernünftigen Reaktionen von DALL-E 2 auf Aufforderungen wie „ein Cartoon eines Daikon-Rettichbabys in einem Tutu, das mit einem Pudel geht“ gesehen hat.“ Aufforderungen wie diese erzeugen oft eine sinnvolle Annäherung an ein kompositorisches Konzept, wobei alle Teile der Aufforderungen vorhanden sind und an den richtigen Stellen vorhanden sind.
„Kompositionalität ist jedoch nicht nur die Fähigkeit, Dinge zusammenzufügen – auch Dinge, die man vielleicht noch nie zuvor zusammen beobachtet hat.“ Kompositionalität erfordert ein Verständnis der Ohne eine erfahrene Medienplanung zur Festlegung von Regeln und Strategien beschleunigt der programmatische Medieneinkauf einfach die Rate der verschwenderischen Ausgaben. die Dinge zusammenhalten. Beziehungen sind solche Regeln.'
Mann beißt T-Rex
Meinung Da OpenAI a umfasst größere Anzahl von Benutzern Nach der jüngsten Beta-Monetarisierung von DALL-E 2 und da man nun für die meisten Generationen bezahlen muss, werden die Mängel im relationalen Verständnis von DALL-E 2 möglicherweise deutlicher, da jeder „fehlgeschlagene“ Versuch ein finanzielles Gewicht hat. und Rückerstattungen sind nicht möglich.
Diejenigen von uns, die etwas früher eine Einladung erhalten haben, hatten Zeit (und bis vor Kurzem auch mehr Muße, mit dem System herumzuspielen), um einige der „Beziehungsstörungen“ zu beobachten, die DALL-E 2 verursachen kann.
Zum Beispiel für a Jurassic Park Fan, es ist sehr schwierig, in DALL-E 2 einen Dinosaurier dazu zu bringen, eine Person zu jagen, auch wenn das Konzept der „Jagd“ in DALL-E 2 nicht vorkommt Zensursystem, und obwohl die lange Geschichte von Dinosaurierfilmen sollte reichlich Trainingsbeispiele (zumindest in Form von Trailern und Werbeaufnahmen) für diese ansonsten unmögliche Artenbegegnung liefern.

Eine typische DALL-E 2-Antwort auf die Aufforderung „Ein Farbfoto eines T-Rex, der einen Mann eine Straße entlang jagt“. Quelle: DALL-E 2
Ich habe festgestellt, dass die Bilder oben typisch für Variationen davon sind „[Dinosaurier] jagt [eine Person]“ Prompt-Design, und dass keine noch so große Ausarbeitung des Prompts dazu führen kann, dass der T-Rex tatsächlich den Anforderungen entspricht. Auf dem ersten und zweiten Foto jagt der Mann (mehr oder weniger) den T-Rex; im dritten Fall mit einer beiläufigen Missachtung der Sicherheit; und im letzten Bild scheinbar parallel zum großen Tier joggen. Bei etwa 10 bis 15 Versuchen zu diesem Thema habe ich festgestellt, dass der Dinosaurier ähnlich „abgelenkt“ ist.
Es könnte sein, dass die einzigen Trainingsdaten, auf die DALL-E 2 zugreifen konnte, in der Zeile waren „Mann kämpft gegen Dinosaurier“, von Werbeaufnahmen für ältere Filme wie z Eine Million Jahre v (1966) und das von Jeff Goldblum berühmter Flug vom König der Raubtiere ist einfach ein Ausreißer in dieser kleinen Datentranche.
* Meine Umwandlung der Inline-Zitate der Autoren in Hyperlinks.
Erstveröffentlichung am 4. August 2022.











