Künstliche Intelligenz
Vollständiger Leitfaden zu Gemma 2: Googles neues offenes großes Sprachmodell

Gemma 2 baut auf seinem Vorgänger auf und bietet verbesserte Leistung und Effizienz sowie eine Reihe innovativer Funktionen, die es sowohl für die Forschung als auch für praktische Anwendungen besonders attraktiv machen. Was Gemma 2 auszeichnet, ist seine Fähigkeit, eine Leistung zu liefern, die mit viel größeren proprietären Modellen vergleichbar ist, jedoch in einem Paket, das für eine breitere Zugänglichkeit und den Einsatz auf einfacheren Hardware-Setups konzipiert ist.
Als ich mich mit den technischen Spezifikationen und der Architektur von Gemma 2 befasste, war ich zunehmend von der Genialität seines Designs beeindruckt. Das Modell enthält mehrere fortschrittliche Techniken, darunter neuartige Aufmerksamkeitsmechanismen und innovative Ansätze zur Schulung der Stabilität, die zu seinen bemerkenswerten Fähigkeiten beitragen.

Google Open Source LLM Gemma
In diesem umfassenden Leitfaden untersuchen wir Gemma 2 eingehend und untersuchen seine Architektur, seine wichtigsten Funktionen und seine praktischen Anwendungen. Egal, ob Sie ein erfahrener KI-Praktiker oder ein begeisterter Neuling auf diesem Gebiet sind, dieser Artikel bietet Ihnen wertvolle Einblicke in die Funktionsweise von Gemma 2 und wie Sie dessen Leistungsfähigkeit in Ihren eigenen Projekten nutzen können.
Was ist Gemma 2?
Gemma 2 ist Googles neuestes Open-Source-Modell für große Sprachen. Es ist leichtgewichtig und dennoch leistungsstark. Es basiert auf der gleichen Forschung und Technologie wie die Gemini-Modelle von Google und bietet modernste Leistung in einem benutzerfreundlicheren Paket. Gemma 2 ist in zwei Größen erhältlich:
Gemma 2 9B: Ein 9 Milliarden Parametermodell
Gemma 2 27B: Ein größeres Modell mit 27 Milliarden Parametern
Jede Größe ist in zwei Varianten erhältlich:
Basismodelle: Vorab trainiert anhand eines riesigen Korpus an Textdaten
Unterrichtsoptimierte (IT-)Modelle: Feinabstimmung für bessere Leistung bei bestimmten Aufgaben
Greifen Sie in Google AI Studio auf die Modelle zu: Google AI Studio – Gemma 2
Lesen Sie das Papier hier: Technischer Bericht zu Gemma 2
Hauptmerkmale und Verbesserungen
Gemma 2 bietet gegenüber seinem Vorgänger mehrere bedeutende Verbesserungen:
1. Mehr Trainingsdaten
Die Modelle wurden mit wesentlich mehr Daten trainiert:
Gemma 2 27B: Trainiert mit 13 Billionen Token
Gemma 2 9B: Trainiert mit 8 Billionen Token
Dieser erweiterte Datensatz, der hauptsächlich aus Webdaten (meist Englisch), Code und Mathematik besteht, trägt zur verbesserten Leistung und Vielseitigkeit der Modelle bei.
2. Schiebefenster Achtung
Gemma 2 implementiert einen neuartigen Ansatz für Aufmerksamkeitsmechanismen:
Jede zweite Schicht verwendet ein gleitendes Fenster mit einem lokalen Kontext von 4096 Token.
Abwechselnde Schichten verwenden volle quadratische globale Aufmerksamkeit über den gesamten 8192-Token-Kontext
Dieser hybride Ansatz zielt darauf ab, Effizienz mit der Fähigkeit in Einklang zu bringen, langfristige Abhängigkeiten in der Eingabe zu erfassen.
3. Soft-Capping
Um die Trainingsstabilität und -leistung zu verbessern, führt Gemma 2 einen Soft-Capping-Mechanismus ein:
def soft_cap(x, cap):
return cap * torch.tanh(x / cap)
# Applied to attention logits
attention_logits = soft_cap(attention_logits, cap=50.0)
# Applied to final layer logits
final_logits = soft_cap(final_logits, cap=30.0)
Mit dieser Technik wird verhindert, dass Logits übermäßig groß werden, ohne dass eine harte Kürzung erfolgt. So bleiben mehr Informationen erhalten und der Trainingsprozess wird stabilisiert.
- Gemma 2 9B: Ein 9 Milliarden Parametermodell
- Gemma 2 27B: Ein größeres Modell mit 27 Milliarden Parametern
Jede Größe ist in zwei Varianten erhältlich:
- Basismodelle: Vortrainiert auf einem riesigen Korpus an Textdaten
- Anweisungsoptimierte (IT-)Modelle: Feinabstimmung für eine bessere Leistung bei bestimmten Aufgaben
4. Wissensdestillation
Für das 9B-Modell verwendet Gemma 2 Techniken zur Wissensdestillation:
- Vortraining: Das 9B-Modell lernt während des ersten Trainings von einem größeren Lehrermodell
- Nach dem Training: Sowohl das 9B- als auch das 27B-Modell verwenden On-Policy-Destillation, um ihre Leistung zu verfeinern
Dieser Prozess hilft dem kleineren Modell, die Fähigkeiten größerer Modelle effektiver zu erfassen.
5. Modellzusammenführung
Gemma 2 verwendet eine neuartige Modellzusammenführungstechnik namens Warp, die mehrere Modelle in drei Schritten kombiniert:
- Exponential Moving Average (EMA) während der Feinabstimmung des Reinforcement Learning
- Spherical Linear intERPolation (SLERP) nach Feinabstimmung mehrerer Richtlinien
- Lineare Interpolation zur Initialisierung (LITI) als letzter Schritt
Ziel dieses Ansatzes ist die Schaffung eines robusteren und leistungsfähigeren Endmodells.
Leistungsbenchmarks
Gemma 2 zeigt bei verschiedenen Benchmarks eine beeindruckende Leistung:
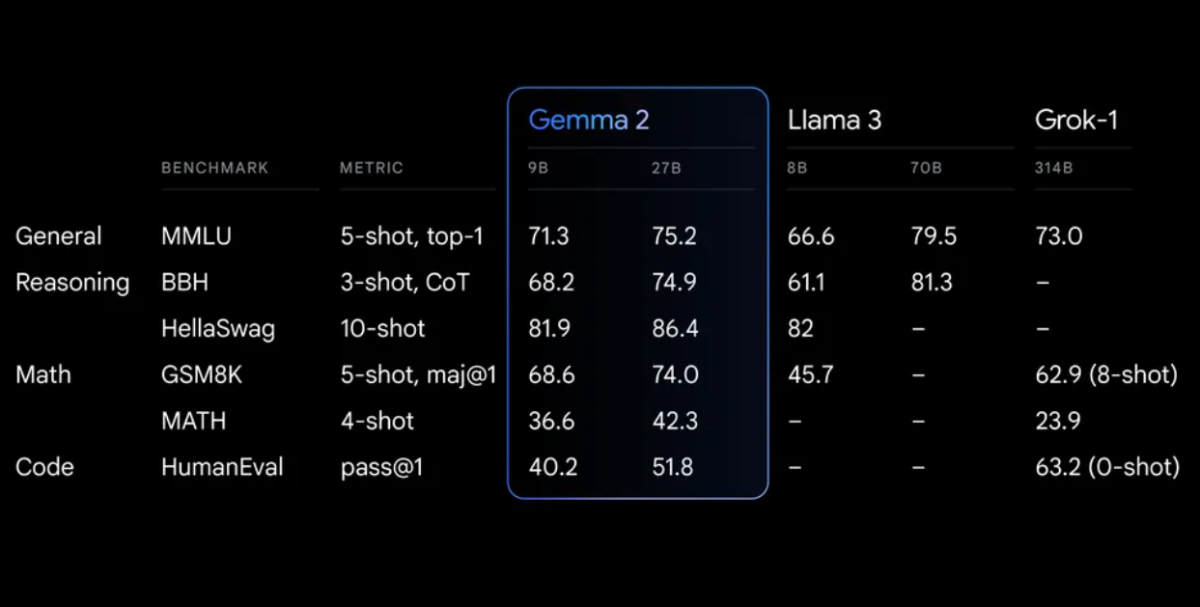
Gemma 2 mit einer neu gestalteten Architektur, die sowohl auf außergewöhnliche Leistung als auch auf Inferenzeffizienz ausgelegt ist
Erste Schritte mit Gemma 2
Um Gemma 2 in Ihren Projekten zu verwenden, haben Sie mehrere Möglichkeiten:
1. Google AI Studio
Für schnelle Experimente ohne Hardwareanforderungen können Sie Gemma 2 über Google AI Studio.
2. Hugging Face Transformers
Gemma 2 ist integriert mit dem beliebten Gesicht umarmen Transformers-Bibliothek. So können Sie sie verwenden:
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # Load the model and tokenizer model_name = "google/gemma-2-27b-it" # or "google/gemma-2-9b-it" for the smaller version tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # Prepare input prompt = "Explain the concept of quantum entanglement in simple terms." inputs = tokenizer(prompt, return_tensors="pt") # Generate text outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)
3. TensorFlow/Keras
Für TensorFlow-Benutzer ist Gemma 2 über Keras verfügbar:
import tensorflow as tf
from keras_nlp.models import GemmaCausalLM
# Load the model
model = GemmaCausalLM.from_preset("gemma_2b_en")
# Generate text
prompt = "Explain the concept of quantum entanglement in simple terms."
output = model.generate(prompt, max_length=200)
print(output)
Fortgeschrittene Nutzung: Erstellen eines lokalen RAG-Systems mit Gemma 2
Eine leistungsstarke Anwendung von Gemma 2 ist der Aufbau eines Retrieval Augmented Generation (RAG)-Systems. Lassen Sie uns ein einfaches, vollständig lokales RAG-System mit Gemma 2 und Nomic-Einbettungen erstellen.
Schritt 1: Einrichten der Umgebung
Stellen Sie zunächst sicher, dass Sie die erforderlichen Bibliotheken installiert haben:
pip install langchain ollama nomic chromadb
Schritt 2: Dokumente indizieren
Erstellen Sie einen Indexer zur Verarbeitung Ihrer Dokumente:
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
class Indexer:
def __init__(self, directory_path):
self.directory_path = directory_path
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
self.embeddings = HuggingFaceEmbeddings(model_name="nomic-ai/nomic-embed-text-v1")
def load_and_split_documents(self):
loader = DirectoryLoader(self.directory_path, glob="**/*.txt")
documents = loader.load()
return self.text_splitter.split_documents(documents)
def create_vector_store(self, documents):
return Chroma.from_documents(documents, self.embeddings, persist_directory="./chroma_db")
def index(self):
documents = self.load_and_split_documents()
vector_store = self.create_vector_store(documents)
vector_store.persist()
return vector_store
# Usage
indexer = Indexer("path/to/your/documents")
vector_store = indexer.index()
Schritt 3: Einrichten des RAG-Systems
Erstellen wir nun das RAG-System mit Gemma 2:
from langchain.llms import Ollama
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
class RAGSystem:
def __init__(self, vector_store):
self.vector_store = vector_store
self.llm = Ollama(model="gemma2:9b")
self.retriever = self.vector_store.as_retriever(search_kwargs={"k": 3})
self.template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Answer: """
self.qa_prompt = PromptTemplate(
template=self.template, input_variables=["context", "question"]
)
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": self.qa_prompt}
)
def query(self, question):
return self.qa_chain({"query": question})
# Usage
rag_system = RAGSystem(vector_store)
response = rag_system.query("What is the capital of France?")
print(response["result"])
Dieses RAG-System verwendet Gemma 2 bis Ollama für das Sprachmodell und Nomic-Einbettungen für die Dokumentensuche. Es ermöglicht Ihnen, Fragen auf Grundlage der indexierten Dokumente zu stellen und Antworten mit Kontext aus den relevanten Quellen bereitzustellen.
Feinabstimmung von Gemma 2
Für bestimmte Aufgaben oder Bereiche möchten Sie Gemma 2 möglicherweise optimieren. Hier ist ein einfaches Beispiel mit der Bibliothek „Hugging Face Transformers“:
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
from datasets import load_dataset
# Load model and tokenizer
model_name = "google/gemma-2-9b-it"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Prepare dataset
dataset = load_dataset("your_dataset")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Set up training arguments
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
)
# Initialize Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
)
# Start fine-tuning
trainer.train()
# Save the fine-tuned model
model.save_pretrained("./fine_tuned_gemma2")
tokenizer.save_pretrained("./fine_tuned_gemma2")
Denken Sie daran, die Trainingsparameter an Ihre spezifischen Anforderungen und Rechenressourcen anzupassen.
Ethische Überlegungen und Einschränkungen
Obwohl Gemma 2 beeindruckende Funktionen bietet, ist es wichtig, sich seiner Einschränkungen und ethischen Aspekte bewusst zu sein:
- Befangenheit: Wie alle Sprachmodelle kann Gemma 2 Verzerrungen in seinen Trainingsdaten widerspiegeln. Bewerten Sie seine Ergebnisse immer kritisch.
- Sachliche Richtigkeit: Gemma 2 ist zwar sehr leistungsfähig, kann aber manchmal falsche oder inkonsistente Informationen generieren. Überprüfen Sie wichtige Fakten anhand zuverlässiger Quellen.
- Kontextlänge: Gemma 2 hat eine Kontextlänge von 8192 Token. Bei längeren Dokumenten oder Konversationen müssen Sie möglicherweise Strategien implementieren, um den Kontext effektiv zu verwalten.
- Computerressourcen: Insbesondere für das 27B-Modell können erhebliche Rechenressourcen für eine effiziente Inferenz und Feinabstimmung erforderlich sein.
- Verantwortungsvolle Nutzung: Halten Sie sich an die Responsible AI-Praktiken von Google und stellen Sie sicher, dass Ihre Verwendung von Gemma 2 den ethischen KI-Prinzipien entspricht.
Fazit
Dank der erweiterten Funktionen von Gemma 2 wie Sliding Window Attention, Soft-Capping und neuartigen Techniken zum Zusammenführen von Modellen ist es ein leistungsstarkes Werkzeug für eine breite Palette von Aufgaben zur Verarbeitung natürlicher Sprache.
Indem Sie Gemma 2 in Ihren Projekten nutzen, sei es durch einfache Inferenz, komplexe RAG-Systeme oder fein abgestimmte Modelle für bestimmte Domänen, können Sie die Leistung von SOTA AI nutzen und gleichzeitig die Kontrolle über Ihre Daten und Prozesse behalten.












