Artificial Intelligence
Creating Satellite Imagery From Vector Maps

Researchers in the UK have developed an AI-based image synthesis system that can convert vector-based maps into satellite-style imagery on the fly.
The neural architecture is called Seamless Satellite-image Synthesis (SSS), and offers the prospect of realistic virtual environments and navigation solutions that have better resolution than satellite imagery can offer; are more up to date (since cartographic map systems can be updated on a live basis); and can facilitate realistic orbital-style views in areas where satellite sensor resolution is limited or otherwise unavailable.

Resolution-free vector data can be translated to much higher image sizes than are often available from real satellite imagery, and can quickly reflect updates in network-based cartographic maps, such as new obstructions or changes in road network infrastructure. Source: https://arxiv.org/pdf/2111.03384.pdf
To demonstrate the power of the system, the researchers have created an interactive, Google Earth-style environment where the viewer can zoom in and observe the generated satellite imagery at a variety of render scales and detail, with the tiles updating live in much the same way as conventional interactive systems for satellite imagery:
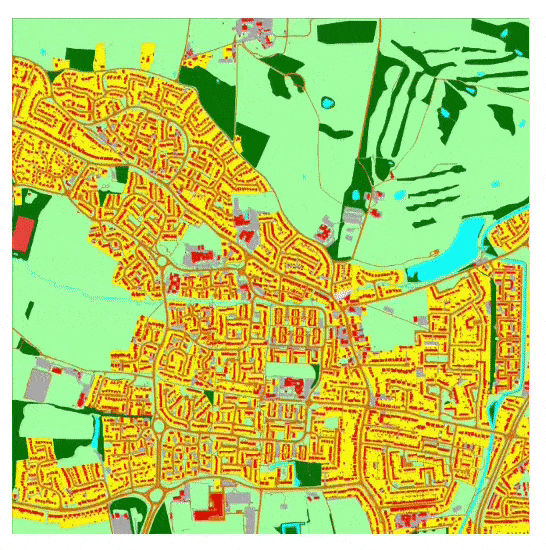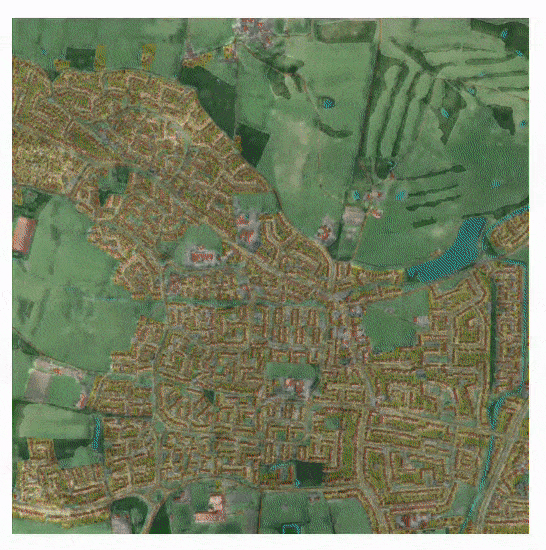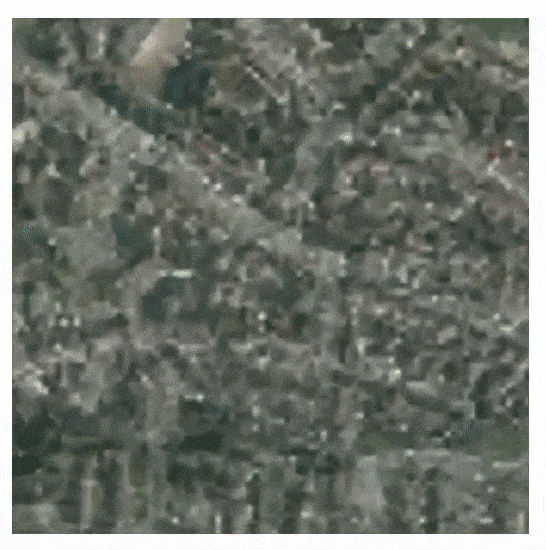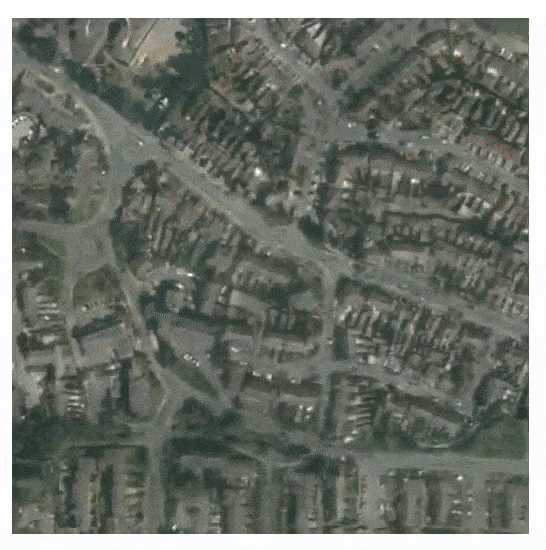
Zooming into the created environment, based on a cartographic map. See video at end of article for better resolution and more detail about the process. Source: https://www.youtube.com/watch?v=PqFySVpkZzg
Furthermore, since the system can generate satellite-style imagery from any vector-based map, it could in theory be used to build historic, projected or fictitious worlds, for incorporation into flight simulators and virtual environments. Additionally, the researchers anticipate synthesizing fully 3D virtual environments from cartographic data using transformers.
In the nearer-term, the authors believe that their framework could be used for a number of real-world applications, including interactive city planning and procedural modeling, envisaging a scenario where stakeholders can edit a map interactively and see birds-eye view imagery of the projected terrain within seconds.
The new paper comes from two researchers at the University of Leeds, and is titled Seamless Satellite-image Synthesis.

The SSS architecture recreates London, with a glimpse into the underlying vector structure that is feeding the reconstruction. Inset top left, the entire image, available in supplementary materials at 8k resolution.
Architecture and Source Training Data
The new system makes use of UCL Berkeley’s 2017 Pix2Pix and NVIDIA’s SPADE image synthesis architecture. The framework contains two novel convolutional neural networks – map2sat, which performs the conversion from vector to pixel-based imagery; and seam2cont, which not only calculates a seamless method to gather together the 256×256 tiles, but also provides an interactive exploration environment.

The architecture of SSS.
The system learns to synthesize satellite views by training on vector views and their real-life satellite equivalents, forming a generalized understanding about how to interpret vector facets into photo-real interpretations.
The vector-based images used in the dataset are rasterized from GeoPackage (.geo) files which contain up to 13 class labels, such as track, natural environment, building and road, which are leveraged in deciding on the kind of imagery to put into the satellite view.
The rasterized .geo satellite images also retain local Coordinate Reference System metadata, which is used to interpret them into context in the broader map framework, and to allow the user to interactively navigate the created maps.
Seamless Tiles Under Hard Constraints
Creating explorable map environments is a challenge, since hardware limitations in the project constrains tiles to a size of only 256 x 256 pixels. Therefore it’s important that either the rendering or composition process takes the ‘bigger picture’ into account, instead of concentrating exclusively on the tile at hand, which would lead to jarring juxtapositions when the tiles are collated, with roads suddenly changing color, and other non-realistic rendering artifacts.
Therefore SSS uses a scale-space hierarchy of generator networks to generate variation of content at a variety of scales, and the system is able to arbitrarily evaluate tiles at any intermediate scale the viewer might need.
The seam2cont section of the architecture uses two overlapping and independent layers of the map2sat output, and calculates an appropriate border within the context of the wider image to be represented:

The seam2cont module uses one images with tiled seam and one without seams from the map2sat network, in order to calculate seamless borders between the 256×256 pixel generated tiles.
The map2sat network is an optimized adaptation of a full-fledged SPADE network, exclusively trained at 256×256 pixels. The authors note that this is a lightweight and spry implementation, leading to weights of only 31.5mb vs. 436.9mb in a full SPADE network.
3000 real satellite images were used to train the two sub-networks over 70 epochs of training time; all images contain equivalent semantic information (i.e. a low-level conceptual understanding of depicted objects such as ‘roads’), and geo-based positioning metadata.
Further materials are available at the project page, as well as an accompanying video (embedded below).












