
IA 101
Què són les CNN (xarxes neuronals convolucionals)?
Potser us heu preguntat com Facebook o Instagram són capaços de reconèixer automàticament cares en una imatge, o com Google us permet cercar al web fotos similars només penjant una foto vostra. Aquestes característiques són exemples de visió per ordinador i estan alimentades per xarxes neuronals convolucionals (CNN). Però, què són exactament les xarxes neuronals convolucionals? Aprofundim en l'arquitectura d'una CNN i entenem com funcionen.
Què són les xarxes neuronals?
Abans de començar a parlar de xarxes neuronals convolucionals, prenem un moment per definir la xarxa neuronal regular. Hi ha un altre article sobre el tema de les xarxes neuronals disponibles, així que no les aprofundirem aquí. Tanmateix, per definir-los breument són models computacionals inspirats en el cervell humà. Una xarxa neuronal funciona agafant dades i manipulant-les mitjançant l'ajust de "pesos", que són suposicions sobre com es relacionen les característiques d'entrada entre si i amb la classe de l'objecte. A mesura que s'entrena la xarxa, els valors dels pesos s'ajusten i s'espera que convergin en pesos que capturen amb precisió les relacions entre les característiques.
Així és com funciona una xarxa neuronal d'alimentació anticipada, i les CNN estan formades per dues meitats: una xarxa neuronal d'alimentació anticipada i un grup de capes convolucionals.
Què són les xarxes neuronals de convolució (CNN)?
Quines són les "convolucions" que succeeixen en una xarxa neuronal convolucional? Una convolució és una operació matemàtica que crea un conjunt de pesos, creant essencialment una representació de parts de la imatge. Aquest conjunt de pesos s'anomena un nucli o filtre. El filtre que es crea és més petit que tota la imatge d'entrada i cobreix només una subsecció de la imatge. Els valors del filtre es multipliquen amb els valors de la imatge. A continuació, es mou el filtre per formar una representació d'una nova part de la imatge i el procés es repeteix fins que s'ha cobert tota la imatge.
Una altra manera de pensar-ho és imaginar una paret de maons, amb els maons que representen els píxels de la imatge d'entrada. S'està fent lliscar una "finestra" cap endavant i cap enrere per la paret, que és el filtre. Els maons que es poden veure a través de la finestra són els píxels que tenen el seu valor multiplicat pels valors dins del filtre. Per aquest motiu, aquest mètode de creació de pesos amb un filtre es coneix sovint com la tècnica de "finestres corredisses".
La sortida dels filtres que es mouen per tota la imatge d'entrada és una matriu bidimensional que representa tota la imatge. Aquesta matriu s'anomena a "Mapa de funcions".
Per què les circumvolucions són essencials
Quin és el propòsit de crear circumvolucions de totes maneres? Les convolucions són necessàries perquè una xarxa neuronal ha de ser capaç d'interpretar els píxels d'una imatge com a valors numèrics. La funció de les capes convolucionals és convertir la imatge en valors numèrics que la xarxa neuronal pugui interpretar i després extreure patrons rellevants. La feina dels filtres a la xarxa convolucional és crear una matriu bidimensional de valors que es puguin passar a les capes posteriors d'una xarxa neuronal, aquelles que aprendran els patrons de la imatge.
Filtres i canals
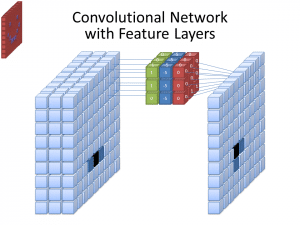
Foto: cecebur via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
Les CNN no utilitzen només un filtre per aprendre patrons de les imatges d'entrada. S'utilitzen diversos filtres, ja que les diferents matrius creades pels diferents filtres condueixen a una representació més complexa i rica de la imatge d'entrada. Els nombres habituals de filtres per a CNN són 32, 64, 128 i 512. Com més filtres hi hagi, més oportunitats té la CNN per examinar les dades d'entrada i aprendre d'elles.
Una CNN analitza les diferències en els valors de píxels per determinar les vores dels objectes. En una imatge en escala de grisos, la CNN només miraria les diferències en blanc i negre, termes clars a foscos. Quan les imatges són imatges en color, la CNN no només té en compte la foscor i la llum, sinó que també ha de tenir en compte els tres canals de color diferents: vermell, verd i blau. En aquest cas, els filtres posseeixen 3 canals, igual que la imatge mateixa. El nombre de canals que té un filtre es coneix com la seva profunditat i el nombre de canals del filtre ha de coincidir amb el nombre de canals de la imatge.
Xarxa neuronal convolucional (CNN) arquitectura
Fem una ullada a l'arquitectura completa de una xarxa neuronal convolucional. Una capa convolucional es troba al principi de cada xarxa convolucional, ja que és necessari transformar les dades de la imatge en matrius numèriques. Tanmateix, les capes convolucionals també poden venir després d'altres capes convolucionals, el que significa que aquestes capes es poden apilar una sobre l'altra. Tenir múltiples capes convolucionals significa que les sortides d'una capa poden experimentar més convolucions i agrupar-se en patrons rellevants. Pràcticament, això significa que a mesura que les dades de la imatge avancen a través de les capes convolucionals, la xarxa comença a "reconèixer" característiques més complexes de la imatge.
Les primeres capes d'una ConvNet s'encarreguen d'extreure les característiques de baix nivell, com ara els píxels que formen línies simples. Les capes posteriors de la ConvNet uniran aquestes línies formant formes. Aquest procés de passar de l'anàlisi a nivell de superfície a l'anàlisi a nivell profund continua fins que ConvNet reconeix formes complexes com animals, rostres humans i cotxes.
Després que les dades hagin passat per totes les capes convolucionals, es dirigeixen a la part densament connectada de la CNN. Les capes densament connectades són el que sembla una xarxa neuronal de feed-forward tradicional, una sèrie de nodes disposats en capes connectades entre si. Les dades passen a través d'aquestes capes densament connectades, que aprenen els patrons que van ser extrets per les capes convolucionals i, en fer-ho, la xarxa esdevé capaç de reconèixer objectes.










