
IA 101
Què és un arbre de decisions?
Què és un arbre de decisions?
A arbre de decisió és un algorisme d'aprenentatge automàtic útil que s'utilitza tant per a tasques de regressió com de classificació. El nom "arbre de decisió" prové del fet que l'algoritme segueix dividint el conjunt de dades en porcions cada cop més petites fins que les dades s'han dividit en instàncies individuals, que després es classifiquen. Si haguéssiu de visualitzar els resultats de l'algorisme, la manera com es divideixen les categories s'assemblaria a un arbre i moltes fulles.
Aquesta és una definició ràpida d'un arbre de decisió, però aprofundim en com funcionen els arbres de decisió. Tenir una millor comprensió de com funcionen els arbres de decisió, així com dels seus casos d'ús, us ajudarà a saber quan utilitzar-los durant els vostres projectes d'aprenentatge automàtic.
Format d'un arbre de decisions
Un arbre de decisió és molt semblant a un diagrama de flux. Per utilitzar un diagrama de flux, comenceu des del punt inicial, o arrel, del diagrama i, en funció de com responeu als criteris de filtratge d'aquest node inicial, passeu a un dels següents nodes possibles. Aquest procés es repeteix fins que s'arriba a un final.
Els arbres de decisió funcionen essencialment de la mateixa manera, amb cada node intern de l'arbre com una mena de criteri de prova/filtratge. Els nodes de l'exterior, els punts finals de l'arbre, són les etiquetes del punt de dades en qüestió i s'anomenen "fulles". Les branques que condueixen des dels nodes interns al node següent són característiques o conjuncions de característiques. Les regles utilitzades per classificar els punts de dades són els camins que van des de l'arrel fins a les fulles.
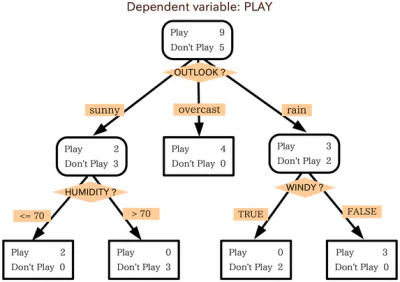
Algoritmes per a arbres de decisió
Els arbres de decisió funcionen amb un enfocament algorítmic que divideix el conjunt de dades en punts de dades individuals en funció de diferents criteris. Aquestes divisions es fan amb diferents variables, o amb les diferents característiques del conjunt de dades. Per exemple, si l'objectiu és determinar si les funcions d'entrada descriuen o no un gos o un gat, les variables en què es divideixen les dades podrien ser coses com ara "urpes" i "lladrucs".
Aleshores, quins algorismes s'utilitzen per dividir les dades en branques i fulles? Hi ha diversos mètodes que es poden utilitzar per dividir un arbre, però el mètode més comú de dividir és probablement una tècnica anomenada "divisió binària recursiva”. Quan es realitza aquest mètode de divisió, el procés comença a l'arrel i el nombre de característiques del conjunt de dades representa el nombre possible de divisions possibles. S'utilitza una funció per determinar quanta precisió costarà cada divisió possible, i la divisió es fa utilitzant els criteris que sacrifiquen la menor precisió. Aquest procés es realitza de forma recursiva i es formen subgrups utilitzant la mateixa estratègia general.
Per determinar el cost de la divisió, s'utilitza una funció de cost. S'utilitza una funció de cost diferent per a les tasques de regressió i les tasques de classificació. L'objectiu d'ambdues funcions de cost és determinar quines branques tenen els valors de resposta més similars o les branques més homogènies. Tingueu en compte que voleu que les dades de prova d'una classe determinada segueixin determinats camins i això té sentit intuïtiu.
Pel que fa a la funció de cost de regressió per a la divisió binària recursiva, l'algorisme utilitzat per calcular el cost és el següent:
suma(y – predicció)^2
La predicció per a un grup particular de punts de dades és la mitjana de les respostes de les dades d'entrenament d'aquest grup. Tots els punts de dades s'executen a través de la funció de cost per determinar el cost de totes les divisions possibles i es selecciona la divisió amb el cost més baix.
Pel que fa a la funció de cost per a la classificació, la funció és la següent:
G = suma(pk * (1 – pk))
Aquesta és la puntuació de Gini, i és una mesura de l'efectivitat d'una divisió, basada en quantes instàncies de classes diferents hi ha als grups resultants de la divisió. En altres paraules, quantifica com de barrejats estan els grups després de la divisió. Una divisió òptima és quan tots els grups resultants de la divisió consisteixen només en entrades d'una classe. Si s'ha creat una divisió òptima, el valor "pk" serà 0 o 1 i G serà igual a zero. És possible que pugueu endevinar que la divisió del pitjor cas és aquella en què hi ha una representació de 50-50 de les classes a la divisió, en el cas de la classificació binària. En aquest cas, el valor "pk" seria 0.5 i G també seria 0.5.
El procés de desdoblament s'acaba quan tots els punts de dades s'han convertit en fulles i classificats. Tanmateix, és possible que vulgueu aturar el creixement de l'arbre abans d'hora. Els arbres complexos grans són propensos a sobreajustar-se, però es poden utilitzar diversos mètodes diferents per combatre-ho. Un mètode per reduir el sobreajust és especificar un nombre mínim de punts de dades que s'utilitzaran per crear una fulla. Un altre mètode per controlar l'ajustament excessiu és restringir l'arbre a una certa profunditat màxima, que controla quant de temps pot allargar-se un camí des de l'arrel fins a una fulla.
Un altre procés implicat en la creació d'arbres de decisió és poda. La poda pot ajudar a augmentar el rendiment d'un arbre de decisió eliminant les branques que contenen característiques que tenen poc poder predictiu/poca importància per al model. D'aquesta manera, es redueix la complexitat de l'arbre, es fa menys probable que s'ajusti més i s'augmenta la utilitat predictiva del model.
Quan es realitza la poda, el procés pot començar a la part superior de l'arbre o a la part inferior de l'arbre. Tanmateix, el mètode més fàcil de podar és començar amb les fulles i intentar deixar anar el node que conté la classe més comuna dins d'aquesta fulla. Si la precisió del model no es deteriora quan es fa, el canvi es conserva. Hi ha altres tècniques utilitzades per dur a terme la poda, però el mètode descrit anteriorment, la poda amb errors reduïts, és probablement el mètode més comú de poda de l'arbre de decisió.
Consideracions per utilitzar arbres de decisió
Arbres de decisió sovint són útils quan la classificació s'ha de dur a terme però el temps de càlcul és una limitació important. Els arbres de decisió poden deixar clar quines característiques dels conjunts de dades escollits tenen el poder predictiu més gran. A més, a diferència de molts algorismes d'aprenentatge automàtic on les regles que s'utilitzen per classificar les dades poden ser difícils d'interpretar, els arbres de decisió poden fer regles interpretables. Els arbres de decisió també poden fer ús de variables categòriques i contínues, la qual cosa significa que es necessita menys preprocessament, en comparació amb algorismes que només poden gestionar un d'aquests tipus de variables.
Els arbres de decisió solen no tenir un bon rendiment quan s'utilitzen per determinar els valors dels atributs continus. Una altra limitació dels arbres de decisió és que, quan es fa una classificació, si hi ha pocs exemples d'entrenament però moltes classes, l'arbre de decisió acostuma a ser inexacte.










