
IA 101
Què és Overfitting?
Què és Overfitting?
Quan entrenes una xarxa neuronal, has d'evitar el sobreajustament. Abastament excessiu és un problema dins de l'aprenentatge automàtic i les estadístiques en què un model aprèn massa bé els patrons d'un conjunt de dades d'entrenament, explicant perfectament el conjunt de dades d'entrenament però no generalitzant el seu poder predictiu a altres conjunts de dades.
Per dir-ho d'una altra manera, en el cas d'un model de sobreajust, sovint mostrarà una precisió extremadament alta en el conjunt de dades d'entrenament, però una precisió baixa en les dades recollides i executades pel model en el futur. Aquesta és una definició ràpida de sobreadaptació, però repassem el concepte de sobreadaptació amb més detall. Fem una ullada a com es produeix el sobreajust i com es pot evitar.
Entendre "Fit" i Underfitting
És útil fer una ullada al concepte de subadaptació i "ajust” generalment quan es parla de sobreadaptació. Quan entrenem un model estem intentant desenvolupar un marc que sigui capaç de predir la naturalesa, o classe, dels elements dins d'un conjunt de dades, basant-nos en les característiques que descriuen aquests elements. Un model hauria de ser capaç d'explicar un patró dins d'un conjunt de dades i predir les classes de punts de dades futurs a partir d'aquest patró. Com millor expliqui el model la relació entre les característiques del conjunt d'entrenament, més "ajusta" el nostre model.
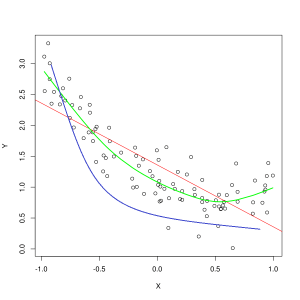
La línia blava representa les prediccions d'un model que no està ajustat, mentre que la línia verda representa un model que s'ajusta millor. Foto: Pep Roca via Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Un model que explica malament la relació entre les característiques de les dades d'entrenament i, per tant, no classifica amb precisió els exemples de dades futurs és subajustament les dades de formació. Si haguéssiu de representar gràficament la relació prevista d'un model d'ajustament insuficient amb la intersecció real de les característiques i les etiquetes, les prediccions es desviarien de la marca. Si tinguéssim un gràfic amb els valors reals d'un conjunt d'entrenament etiquetat, un model molt poc ajustat perdria dràsticament la majoria dels punts de dades. Un model amb un millor ajust podria tallar un camí pel centre dels punts de dades, amb els punts de dades individuals que es troben fora dels valors previstos només una mica.
Sovint es pot produir una subadaptació quan no hi ha dades suficients per crear un model precís o quan s'intenta dissenyar un model lineal amb dades no lineals. Més dades d'entrenament o més funcions sovint ajudaran a reduir l'ajustament insuficient.
Aleshores, per què no crearíem un model que expliqui perfectament tots els punts de les dades d'entrenament? Segurament és desitjable una precisió perfecta? Crear un model que hagi après massa bé els patrons de les dades d'entrenament és el que provoca un sobreajust. El conjunt de dades d'entrenament i altres conjunts de dades futurs que feu servir pel model no seran exactament els mateixos. Probablement seran molt semblants en molts aspectes, però també diferiran en aspectes clau. Per tant, dissenyar un model que expliqui perfectament el conjunt de dades d'entrenament significa que acabeu amb una teoria sobre la relació entre característiques que no es generalitza bé amb altres conjunts de dades.
Entendre el sobreajustament
El sobreajust es produeix quan un model aprèn massa bé els detalls del conjunt de dades d'entrenament, cosa que fa que el model pateixi quan es fan prediccions sobre dades externes. Això pot passar quan el model no només aprèn les característiques del conjunt de dades, sinó que també aprèn fluctuacions aleatòries o soroll dins del conjunt de dades, donant importància a aquestes ocurrències aleatòries/no importants.
És més probable que es produeixi un sobreajustament quan s'utilitzen models no lineals, ja que són més flexibles quan aprenen les característiques de dades. Els algorismes d'aprenentatge automàtic no paramètrics solen tenir diversos paràmetres i tècniques que es poden aplicar per limitar la sensibilitat del model a les dades i, per tant, reduir el sobreajustament. Com un exemple, models d'arbre de decisió són molt sensibles al sobreajustament, però es pot utilitzar una tècnica anomenada poda per eliminar aleatòriament alguns dels detalls que ha après el model.
Si haguéssiu de representar gràficament les prediccions del model en els eixos X i Y, tindríeu una línia de predicció que fa ziga-zagues cap endavant i cap enrere, que reflecteix el fet que el model s'ha esforçat massa per encaixar tots els punts del conjunt de dades. la seva explicació.
Control del sobreajustament
Quan entrenem un model, l'ideal és que el model no cometi errors. Quan el rendiment del model convergeix cap a fer prediccions correctes sobre tots els punts de dades del conjunt de dades d'entrenament, l'ajust és cada cop millor. Un model amb un bon ajust és capaç d'explicar gairebé tot el conjunt de dades d'entrenament sense sobreajustar-se.
A mesura que un model s'entrena, el seu rendiment millora amb el temps. La taxa d'error del model disminuirà a mesura que passi el temps d'entrenament, però només disminueix fins a un cert punt. El punt en què el rendiment del model al conjunt de prova comença a augmentar de nou és normalment el punt en què es produeix un sobreajust. Per tal d'aconseguir el millor ajust per a un model, volem deixar d'entrenar el model en el punt de pèrdua més baixa del conjunt d'entrenament, abans que l'error torni a augmentar. El punt d'aturada òptim es pot determinar mitjançant un gràfic del rendiment del model al llarg del temps d'entrenament i aturant l'entrenament quan la pèrdua és més baixa. Tanmateix, un risc d'aquest mètode de control del sobreajust és que especificar el punt final de l'entrenament basant-se en el rendiment de la prova significa que les dades de la prova s'inclouen una mica en el procediment d'entrenament i perden el seu estat de dades purament "no tocades".
Hi ha un parell de maneres diferents de combatre el sobreajustament. Un mètode per reduir el sobreajust és utilitzar una tàctica de remuestreig, que opera estimant la precisió del model. També podeu utilitzar a validació conjunt de dades a més del conjunt de proves i traceu la precisió de l'entrenament amb el conjunt de validació en lloc del conjunt de dades de prova. D'aquesta manera, el vostre conjunt de dades de prova no es veurà. Un mètode de mostreig popular és la validació creuada de plecs K. Aquesta tècnica us permet dividir les vostres dades en subconjunts en què s'entrena el model i, a continuació, s'analitza el rendiment del model en els subconjunts per estimar el rendiment del model amb les dades externes.
Fer ús de la validació creuada és una de les millors maneres d'estimar la precisió d'un model amb dades no vistes i, quan es combina amb un conjunt de dades de validació, el sobreajustament sovint es pot reduir al mínim.










