
IA 101
Què és una xarxa adversa generativa (GAN)?
Xarxes adversàries generatives (GAN) són tipus d'arquitectures de xarxes neuronals capaç de generar noves dades que s'ajusta als patrons apresos. Els GAN es poden utilitzar per generar imatges de cares humans o altres objectes, per dur a terme traduccions de text a imatge, per convertir un tipus d'imatge a un altre i per millorar la resolució d'imatges (superresolució) entre altres aplicacions. Com que els GAN poden generar dades completament noves, estan al capdavant de molts sistemes, aplicacions i investigacions d'IA d'avantguarda. Tanmateix, com funcionen exactament els GAN? Explorem com funcionen els GAN i fem una ullada a alguns dels seus usos principals.
Definició de Models Generatius i GAN
Un GAN és un exemple de model generatiu. La majoria dels models d'IA es poden dividir en una d'aquestes dues categories: models supervisats i no supervisats. Els models d'aprenentatge supervisat s'utilitzen normalment per discriminar entre diferents categories d'inputs, per classificar. En canvi, els models no supervisats s'utilitzen normalment per resumir la distribució de dades, sovint aprenent una distribució gaussiana de les dades. Com que aprenen la distribució d'un conjunt de dades, poden extreure mostres d'aquesta distribució apresa i generar dades noves.
Els diferents models generatius tenen diferents mètodes per generar dades i calcular distribucions de probabilitat. Per exemple, el Model de Bayes ingenu opera calculant una distribució de probabilitat per a les diferents característiques d'entrada i la classe generativa. Quan el model Naive Bayes fa una predicció, calcula la classe més probable agafant la probabilitat de les diferents variables i combinant-les. Altres models generatius d'aprenentatge no profund inclouen els models de mescles gaussianes i l'assignació de dirichlet latent (LDA). Models generatius basats en una inclinació profunda incloure Màquines Boltzmann restringides (RBM), Autoencoders variacionals (VAE), i per descomptat, GAN.
Les xarxes adversàries generatives eren proposat per primera vegada per Ian Goodfellow el 2014, i Alec Redford i altres investigadors els van millorar el 2015, donant lloc a una arquitectura estandarditzada per a GAN. Les GAN són en realitat dues xarxes diferents unides. Els GAN ho són compost per dues meitats: un model de generació i un model de discriminació, també conegut com a generador i discriminador.
L'arquitectura GAN
Les xarxes adversàries generatives són construït a partir d'un model generador i un model discriminador junts. La feina del model generador és crear nous exemples de dades, basats en els patrons que el model ha après de les dades d'entrenament. La feina del model discriminador és analitzar imatges (suposant que està entrenada en imatges) i determinar si les imatges són generades/falses o genuïnes.

Els dos models s'enfronten l'un a l'altre, entrenats de manera teòrica del joc. L'objectiu del model generador és produir imatges que enganin el seu adversari: el model discriminador. Mentrestant, la feina del model discriminador és superar el seu adversari, el model generador, i captar les imatges falses que produeix el generador. El fet que els models s'enfrontin els uns als altres es tradueix en una carrera armamentística on tots dos models milloren. El discriminador rep informació sobre quines imatges eren genuïnes i quines les va produir el generador, mentre que el generador rep informació sobre quines de les seves imatges van ser marcades com a falses pel discriminador. Ambdós models milloren durant l'entrenament, amb l'objectiu d'entrenar un model de generació que pugui produir dades falses bàsicament indistinguibles de dades reals i genuïnes.
Un cop s'ha creat una distribució gaussiana de dades durant l'entrenament, es pot utilitzar el model generatiu. El model generador s'alimenta inicialment d'un vector aleatori, que transforma en funció de la distribució gaussiana. En altres paraules, el vector sembra la generació. Quan s'entrena el model, l'espai vectorial serà una versió comprimida, o representació, de la distribució gaussiana de les dades. La versió comprimida de la distribució de dades s'anomena espai latent o variables latents. Més endavant, el model GAN pot agafar la representació de l'espai latent i extreure'n punts, que es poden donar al model de generació i utilitzar-los per generar noves dades molt semblants a les dades d'entrenament.
El model discriminador s'alimenta d'exemples de tot el domini d'entrenament, que està format per exemples de dades reals i generades. Els exemples reals es troben dins del conjunt de dades d'entrenament, mentre que les dades falses són produïdes pel model generatiu. El procés d'entrenament del model discriminador és exactament el mateix que l'entrenament bàsic del model de classificació binària.
Procés de formació GAN
Vegem-ho sencer training procés per a una tasca hipotètica de generació d'imatges.
Per començar, el GAN s'entrena utilitzant imatges reals i genuïnes com a part del conjunt de dades d'entrenament. Això configura el model de discriminació per distingir entre imatges generades i imatges reals. També produeix la distribució de dades que el generador utilitzarà per produir noves dades.
El generador agafa un vector de dades numèriques aleatòries i les transforma en funció de la distribució gaussiana, retornant una imatge. Aquestes imatges generades, juntament amb algunes imatges genuïnes del conjunt de dades d'entrenament, s'introdueixen al model discriminador. El discriminador farà una predicció probabilística sobre la naturalesa de les imatges que rep, generant un valor entre 0 i 1, on 1 és normalment imatges autèntiques i 0 és una imatge falsa.
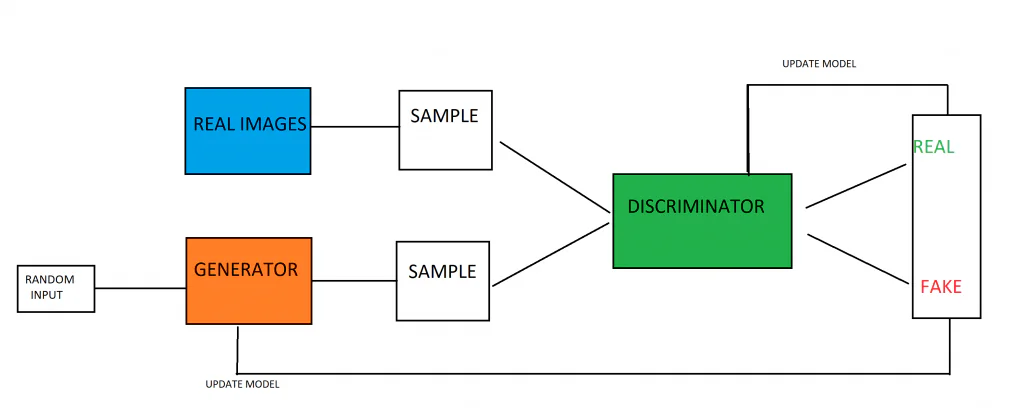
Hi ha un doble bucle de retroalimentació en joc, ja que el discriminador de terra s'alimenta de la veritat terrestre de les imatges, mentre que el generador rep una retroalimentació sobre el seu rendiment pel discriminador.
Els models generatiu i de discriminació estan jugant un joc de suma zero entre ells. Un joc de suma zero és aquell en què els guanys d'un bàndol són a costa de l'altre costat (la suma és que ambdues accions són zero ex). Quan el model del discriminador és capaç de distingir amb èxit entre exemples reals i falsos, no es fan canvis als paràmetres del discriminador. Tanmateix, es fan grans actualitzacions dels paràmetres del model quan no aconsegueix distingir entre imatges reals i falses. El contrari és cert per al model generatiu, es penalitza (i s'actualitzen els seus paràmetres) quan no aconsegueix enganyar el model discriminatiu, però en cas contrari els seus paràmetres no es modifiquen (o es recompensa).
Idealment, el generador és capaç de millorar el seu rendiment fins a un punt en què el discriminador no pot discernir entre les imatges falses i reals. Això vol dir que el discriminador sempre mostrarà probabilitats de % 50 per a imatges reals i falses, el que significa que les imatges generades haurien de ser indistinguibles de les imatges genuïnes. A la pràctica, els GAN normalment no arribaran a aquest punt. Tanmateix, el model generatiu no necessita crear imatges perfectament similars per continuar sent útil per a les moltes tasques per a les quals s'utilitzen els GAN.
Aplicacions GAN
Els GAN tenen una sèrie d'aplicacions diferents, la majoria d'elles giren al voltant de la generació d'imatges i components d'imatges. Els GAN s'utilitzen habitualment en tasques on les dades d'imatge necessàries falten o estan limitades en certa capacitat, com a mètode per generar les dades requerides. Examinem alguns dels casos d'ús habituals dels GAN.
Generació de nous exemples per a conjunts de dades
Els GAN es poden utilitzar per generar exemples nous per a conjunts de dades d'imatges simples. Si només teniu un grapat d'exemples d'entrenament i en necessiteu més, els GAN es podrien utilitzar per generar noves dades d'entrenament per a un classificador d'imatges, generant nous exemples d'entrenament en diferents orientacions i angles.
Generar cares humanes úniques

La dona d'aquesta foto no existeix. La imatge va ser generada per StyleGAN. Foto: Owlsmcgee a través de Wikimedia Commons, domini públic (https://commons.wikimedia.org/wiki/File:Woman_1.jpg)
Quan estiguin prou entrenats, els GAN es poden utilitzar generar imatges extremadament realistes de rostres humans. Aquestes imatges generades es poden utilitzar per ajudar a entrenar sistemes de reconeixement facial.
Traducció d'imatge a imatge
Gans excel·lent en la traducció d'imatges. Els GAN es poden utilitzar per acolorir imatges en blanc i negre, traduir esbossos o dibuixos a imatges fotogràfiques o convertir imatges del dia a la nit.
Traducció de text a imatge
La traducció de text a imatge és possible mitjançant l'ús de GAN. Quan es proporciona un text que descriu una imatge i la imatge que l'acompanya, un GAN pot estar entrenat per crear una nova imatge quan es proporcioni una descripció de la imatge desitjada.
Edició i reparació d'imatges
Els GAN es poden utilitzar per editar fotografies existents. GAN eliminar elements com la pluja o la neu d'una imatge, però també es poden fer servir reparar imatges velles, danyades o malmeses.
Super resolució
La superresolució és el procés de prendre una imatge de baixa resolució i inserir més píxels a la imatge, millorant la resolució d'aquesta imatge. Els GAN es poden entrenar per fer una imatge i generar una versió de més alta resolució d'aquesta imatge.














