人工智能
数据科学领域中的简单线性回归
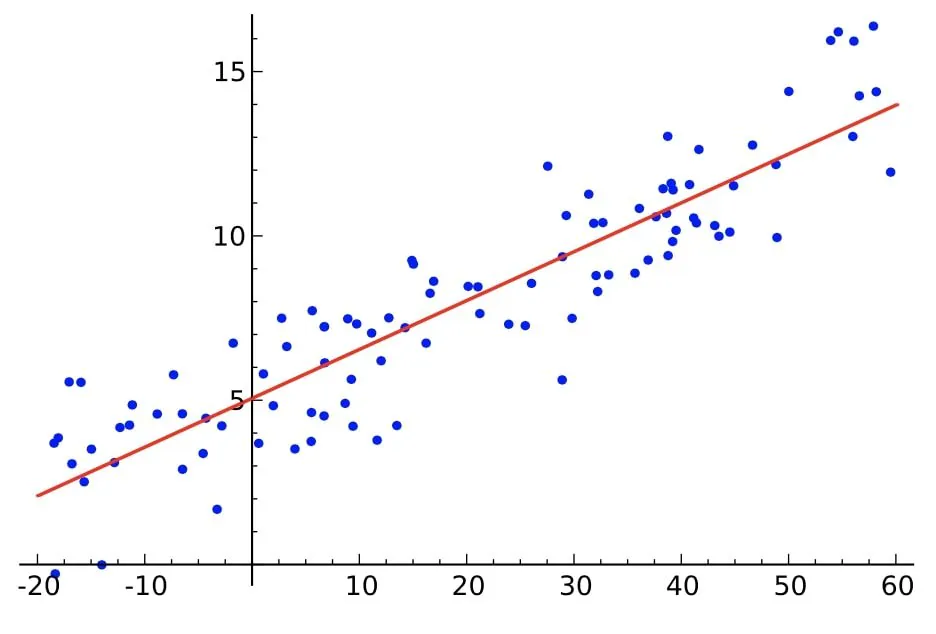
数据科学是一个正在快速发展的领域,今天,顶级公司正在寻找具有扎实数据科学知识和相关概念的专业数据科学家。要在这个领域表现良好,必须对数据科学算法有深入的了解。简单线性回归是最基本的数据科学算法之一。每个数据科学家都应该知道如何使用这个算法来解决问题和得出有意义的结果。
简单线性回归是一种确定输入和输出变量之间关系的方法。输入变量被认为是独立变量或预测因子,输出变量被认为是依赖变量或响应变量。在简单线性回归中,只考虑一个输入变量。
简单线性回归的实时例子
让我们考虑一个包含两个参数的数据集:工作小时数和完成的工作量。简单线性回归旨在根据工作小时数预测完成的工作量。绘制一条回归线,生成最小的误差。同时,形成一个线性方程,可以用于几乎任何数据集。
描述简单线性回归目的的原则:
简单线性回归用于预测数据集中变量之间的关系并得出有意义的结论。简单线性回归主要用于推导变量之间的统计关系,这种关系并不足够准确。四个基本原则描述了简单线性回归的使用。这些原则如下:
- 变量之间的关系被认为是线性和加性的: 为每一对依赖变量和独立变量建立一个直线函数。该线的斜率与数据集中变量的值不同。依赖变量对独立变量的值有加性的影响。
- 误差是统计独立的: 这个原则可以用于包含时间和系列信息的数据集。这种数据集的连续误差不相关且统计独立。
- 误差具有恒定的方差(同方差性): 误差的同方差性可以根据各种参数考虑,包括时间、其他预测和其他变量。
- 误差分布正态性: 这是一个重要的原则,因为它支持上述三个原则。如果不能在数据集中建立变量之间的关系,或者上述任何原则不成立,那么模型产生的所有预测和结论都是错误的。这些结论不能用于项目,因为如果使用错误和误导性的数据,无法获得真实的结果。
简单线性回归的优点
- 这种方法非常容易使用,结果可以轻松获得。
- 这种方法的复杂度远远低于其他数据科学算法,特别是当已知依赖变量和独立变量之间的关系时。
- 过拟合是一个常见的问题,当这种方法接收到无意义的信息时就会发生。为了解决这个问题,正则化技术是可用的,它通过降低复杂度来减少过拟合的问题。
简单线性回归的缺点
- 虽然过拟合的问题可以消除,但不能忽略。这种方法可以接收无意义的数据,并且可以消除有意义的信息。在这种情况下,对于特定数据集的所有预测和结论都是错误的,无法产生有效的结果。
- 数据异常值的问题也非常常见。异常值被认为是错误的值,不符合实际数据。当这种值被考虑时,整个模型将产生误导性的结果,这些结果是无用的。
- 在简单线性回归中,假设数据集中的数据是独立的。但是,这个假设是错误的,因为变量之间可能存在依赖关系。
简单线性回归 是一种有用的技术,用于确定数据集中各种输入和输出变量之间的关系。简单线性回归有许多实时应用。这个算法不需要高计算能力,可以轻松实现。推导出的方程和结论可以进一步构建,并且非常容易理解。然而,一些专业人士认为,简单线性回归不是适合用于各种应用的方法,因为它做出了很多假设。这些假设可能被证明是错误的。因此,必须在可以正确应用这种技术的地方使用它。












