人工智能
Gemma 2 的完整指南:谷歌的新开源大型语言模型

Gemma 2是在其前身基础上进行了改进,提供了增强的性能和效率,以及一系列创新功能,使其在研究和实际应用中都非常有吸引力。Gemma 2 的突出之处在于其能够提供与更大型的专有模型相当的性能,但包装在更易于使用和更广泛可用的形式中。
当我深入研究 Gemma 2 的技术规格和架构时,我越来越被其设计的巧妙所折服。该模型采用了几种先进的技术,包括新颖的注意力机制和训练稳定性的创新方法,这些都有助于其出色的能力。

谷歌开源大型语言模型 Gemma
在这份综合指南中,我们将深入探讨 Gemma 2,检查其架构、关键功能和实际应用。无论您是经验丰富的 AI 从业者还是该领域的新人,本文旨在为您提供宝贵的见解,了解 Gemma 2 的工作原理以及如何在您的项目中利用其力量。
什么是 Gemma 2?
Gemma 2 是谷歌最新的开源大型语言模型,旨在轻量化但功能强大。它基于与谷歌的 Gemini 模型相同的研究和技术,提供了最先进的性能,但包装在更易于使用的形式中。Gemma 2 有两种尺寸:
Gemma 2 9B:一个 9 亿参数的模型
Gemma 2 27B:一个更大的 27 亿参数的模型
每种尺寸都有两种变体:
基础模型:预训练在大量文本数据上
指令调优(IT)模型:为特定任务进行了微调,以获得更好的性能
在谷歌 AI Studio 中访问模型:谷歌 AI Studio – Gemma 2
阅读技术报告:Gemma 2 技术报告
关键功能和改进
Gemma 2 引入了几项重大改进:
1. 增加的训练数据
模型的训练数据量大幅增加:
Gemma 2 27B:训练在 13 万亿令牌上
Gemma 2 9B:训练在 8 万亿令牌上
这种扩大的数据集主要由网页数据(主要是英语)、代码和数学组成,有助于模型的性能和多样性。
2. 滑动窗口注意力
Gemma 2 实现了一种新颖的注意力机制:
每隔一层使用具有 4096 个令牌的局部上下文的滑动窗口注意力
交替层使用整个 8192 个令牌上下文的全二次注意力
这种混合方法旨在平衡效率与捕获输入中长距离依赖的能力。
3. 软上限
为了提高训练稳定性和性能,Gemma 2 引入了一个软上限机制:
<p>def soft_cap(x, cap): return cap * torch.tanh(x / cap)</p> <p># 应用于注意力 logits attention_logits = soft_cap(attention_logits, cap=50.0)</p> # 应用于最终层 logits <p>final_logits = soft_cap(final_logits, cap=30.0)
这种技术防止 logits 过度增长而不进行硬截断,保持更多信息同时稳定训练过程。
- Gemma 2 9B:一个 9 亿参数的模型
- Gemma 2 27B:一个更大的 27 亿参数的模型
每种尺寸都有两种变体:
- 基础模型:预训练在大量文本数据上
- 指令调优(IT)模型:为特定任务进行了微调,以获得更好的性能
4. 知识蒸馏
对于 9B 模型,Gemma 2 采用了知识蒸馏技术:
- 预训练:9B 模型在初始训练期间从更大的教师模型中学习
- 后训练:9B 和 27B 模型都使用在线策略蒸馏来改进其性能
这种过程有助于较小的模型更有效地捕获较大模型的能力。
5. 模型合并
Gemma 2 采用了一种称为 Warp 的新型模型合并技术,该技术将多个模型合并为三个阶段:
- 强化学习微调期间的指数移动平均(EMA)
- 多个策略微调后使用球面线性插值(SLERP)
- 初始化的线性插值(LITI)作为最后一步
这种方法旨在创建一个更强大、更有能力的最终模型。
性能基准
Gemma 2 在各种基准测试中表现出色:
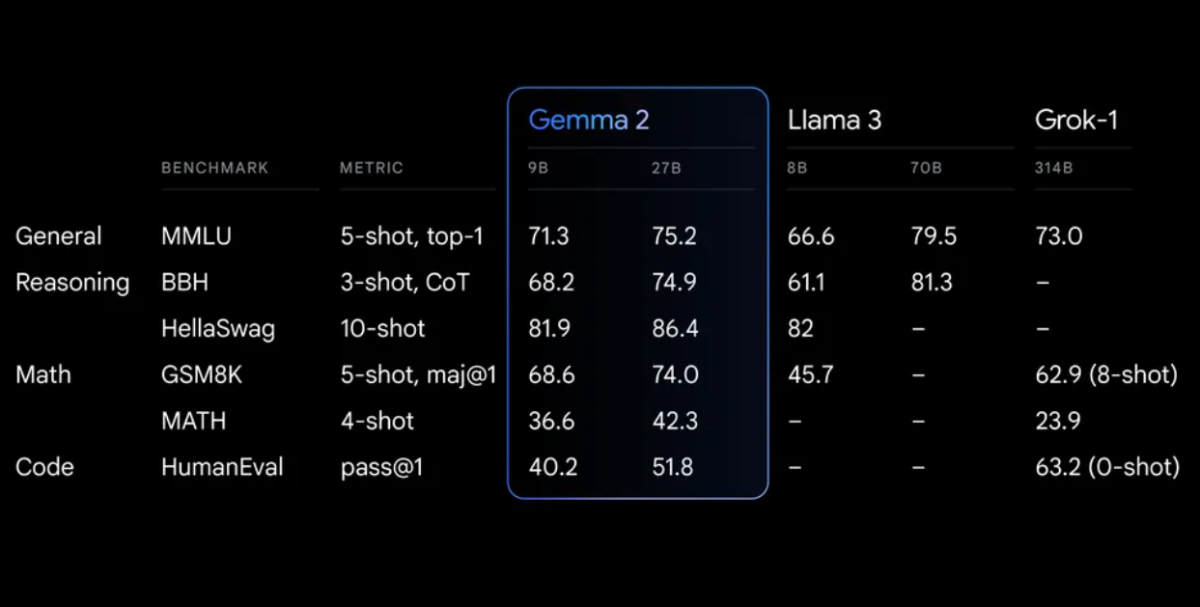
Gemma 2 在重新设计的架构上,工程化为异常性能和推理效率
开始使用 Gemma 2
要开始在您的项目中使用 Gemma 2,您有几个选项:
1. 谷歌 AI Studio
对于快速实验而无需硬件要求,您可以通过 谷歌 AI Studio 访问 Gemma 2。
2. Hugging Face Transformers
Gemma 2 已集成到流行的 Hugging Face Transformers 库中。以下是如何使用它:
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> <p>from transformers import AutoTokenizer, AutoModelForCausalLM</p> <p># 加载模型和分词器 model_name = "google/gemma-2-27b-it" # 或 "google/gemma-2-9b-it" 用于较小版本 tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name)</p> <p># 准备输入 prompt = "用简单的术语解释量子纠缠的概念。" inputs = tokenizer(prompt, return_tensors="pt")</p> <p># 生成文本 outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True)</p> print(response)
3. TensorFlow/Keras
对于 TensorFlow 用户,Gemma 2 可通过 Keras 使用:
<p>import tensorflow as tf from keras_nlp.models import GemmaCausalLM</p> <p># 加载模型 model = GemmaCausalLM.from_preset("gemma_2b_en")</p> <p># 生成文本 prompt = "用简单的术语解释量子纠缠的概念。" output = model.generate(prompt, max_length=200)</p> print(output)
高级用法:使用 Gemma 2 构建本地 RAG 系统
Gemma 2 的一个强大应用是构建检索增强生成(RAG)系统。让我们使用 Gemma 2 和 Nomic 嵌入创建一个简单的本地 RAG 系统。
步骤 1:设置环境
首先,确保安装了必要的库:
<p>pip install langchain ollama nomic chromadb</p>
步骤 2:索引文档
创建一个索引器来处理您的文档:
<p>import os from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.document_loaders import DirectoryLoader from langchain.vectorstores import Chroma from langchain.embeddings import HuggingFaceEmbeddings</p> <p>class Indexer: def __init__(self, directory_path): self.directory_path = directory_path self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) self.embeddings = HuggingFaceEmbeddings(model_name="nomic-ai/nomic-embed-text-v1")</p> <p>def load_and_split_documents(self): loader = DirectoryLoader(self.directory_path, glob="**/*.txt") documents = loader.load() return self.text_splitter.split_documents(documents)</p> <p>def create_vector_store(self, documents): return Chroma.from_documents(documents, self.embeddings, persist_directory="./chroma_db")</p> <p>def index(self): documents = self.load_and_split_documents() vector_store = self.create_vector_store(documents) vector_store.persist() return vector_store</p> <p># 使用 indexer = Indexer("path/to/your/documents") vector_store = indexer.index()</p>
步骤 3:设置 RAG 系统
现在,让我们使用 Gemma 2 创建 RAG 系统:
<p>from langchain.llms import Ollama
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate</p>
<p>class RAGSystem:
def __init__(self, vector_store):
self.vector_store = vector_store
self.llm = Ollama(model="gemma2:9b")
self.retriever = self.vector_store.as_retriever(search_kwargs={"k": 3})</p>
<p>self.template = """使用以下上下文来回答末尾的问题。
如果不知道答案,请直接说不知道,不要尝试编造答案。
{context}
<p>问题:{question}
答案:"""</p>
<p>self.qa_prompt = PromptTemplate(
template=self.template, input_variables=["context", "question"]
)</p>
<p>self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": self.qa_prompt}
)</p>
<p>def query(self, question):
return self.qa_chain({"query": question})</p>
<p># 使用
rag_system = RAGSystem(vector_store)
response = rag_system.query("法国的首都是什么?")
print(response["result"])</p>
这个 RAG 系统使用 Gemma 2 通过 Ollama 作为语言模型,并使用 Nomic 嵌入进行文档检索。它允许您根据索引的文档提问,并提供来自相关来源的上下文答案。
微调 Gemma 2
对于特定任务或领域,您可能需要微调 Gemma 2。以下是一个使用 Hugging Face Transformers 库的基本示例:
从 transformers 导入 AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer 从 datasets 导入 load_dataset <p># 加载模型和分词器 model_name = "google/gemma-2-9b-it" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name)</p> <p># 准备数据集 dataset = load_dataset("your_dataset")</p> <p>def tokenize_function(examples): return tokenizer(examples["text"], padding="max_length", truncation=True)</p> <p>tokenized_datasets = dataset.map(tokenize_function, batched=True)</p> <p># 设置训练参数 training_args = TrainingArguments( output_dir="./results", num_train_epochs=3, per_device_train_batch_size=4, per_device_eval_batch_size=4, warmup_steps=500, weight_decay=0.01, logging_dir="./logs", )</p> <p># 初始化 Trainer trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["test"], )</p> # 开始微调 trainer.train() <p># 保存微调后的模型 model.save_pretrained("./fine_tuned_gemma2") tokenizer.save_pretrained("./fine_tuned_gemma2")</p>
请记得根据您的具体需求和计算资源调整训练参数。
伦理考虑和局限性
虽然 Gemma 2 提供了令人印象深刻的功能,但了解其局限性和伦理考虑至关重要:
- 偏见:像所有语言模型一样,Gemma 2 可能会反映其训练数据中的偏见。始终要批判性地评估其输出。
- 事实准确性:虽然具有很高的能力,但 Gemma 2 有时会生成不正确或不一致的信息。请从可靠的来源验证重要事实。
- 上下文长度:Gemma 2 的上下文长度为 8192 个令牌。对于更长的文档或对话,您可能需要实施有效管理上下文的策略。
- 计算资源:尤其是对于 27B 模型,可能需要大量的计算资源来实现高效的推理和微调。
- 负责任的使用:遵循谷歌的负责任的 AI 实践,并确保您对 Gemma 2 的使用符合道德的 AI 原则。
结论
Gemma 2 的先进功能,如滑动窗口注意力、软上限和新型模型合并技术,使其成为自然语言处理任务的强大工具。
通过在您的项目中利用 Gemma 2,无论是通过简单的推理、复杂的 RAG 系统还是为特定领域进行微调,您都可以利用最先进的 AI 的力量,同时保持对您的数据和流程的控制。












