AI 101
什么是生成对抗网络(GAN)?
生成对抗网络(GAN) 神经网络架构的类型 能够生成新数据 符合学习模式。 GAN 可用于生成人脸或其他物体的图像、进行文本到图像的转换、将一种类型的图像转换为另一种类型,以及增强图像的分辨率(超分辨率)等应用。 由于 GAN 可以生成全新的数据,因此它们处于许多尖端人工智能系统、应用和研究的前沿。 然而 GAN 究竟是如何工作的呢? 让我们探讨 GAN 的工作原理并了解它们的一些主要用途。
定义生成模型和 GAN
GAN 是生成模型的一个例子。 大多数人工智能模型可以分为两类之一:监督模型和无监督模型。 监督学习模型通常用于区分不同类别的输入并进行分类。 相比之下,无监督模型通常用于总结数据的分布,通常学习 数据的高斯分布。 因为他们学习了数据集的分布,所以他们可以从这个学习的分布中提取样本并生成新数据。
不同的生成模型有不同的生成数据和计算概率分布的方法。 例如, 朴素贝叶斯模型 通过计算各种输入特征和生成类的概率分布来进行操作。 当朴素贝叶斯模型进行预测时,它通过获取不同变量的概率并将它们组合在一起来计算最可能的类别。 其他非深度学习生成模型包括高斯混合模型和潜在狄利克雷分配(LDA)。 基于深度学习的生成模型 包括 受限玻尔兹曼机 (RBM), 可变自动编码器(VAE),当然还有 GAN。
生成对抗网络是 由 Ian Goodfellow 于 2014 年首次提出,Alec Redford 和其他研究人员在 2015 年对它们进行了改进,形成了 GAN 的标准化架构。 GAN 实际上是两个不同的网络连接在一起。 GAN 是 由两半组成: 生成模型和判别模型,也称为生成器和判别器。
GAN 架构
生成对抗网络是 由生成器模型和鉴别器模型组合而成。 生成器模型的工作是根据模型从训练数据中学到的模式创建新的数据示例。 鉴别器模型的工作是分析图像(假设它是在图像上训练的)并确定图像是生成的/假的还是真实的。

这两个模型相互竞争,并以博弈论的方式进行训练。 生成器模型的目标是生成欺骗其对手——鉴别器模型的图像。 同时,鉴别器模型的工作是克服它的对手生成器模型,并捕获生成器产生的假图像。 这些模型相互竞争的事实导致了军备竞赛,两个模型都得到了改进。 鉴别器获得有关哪些图像是真实的以及哪些图像是由生成器生成的反馈,而生成器则获得有关其哪些图像被鉴别器标记为错误的信息。 这两种模型在训练过程中都会得到改进,目标是训练一个生成模型,该模型可以生成与真实数据基本上无法区分的虚假数据。
一旦在训练期间创建了数据的高斯分布,就可以使用生成模型。 生成器模型最初被输入一个随机向量,并根据高斯分布对其进行转换。 换句话说,向量为一代人播种。 训练模型时,向量空间将是数据高斯分布的压缩版本或表示。 数据分布的压缩版本称为潜在空间或潜在变量。 随后,GAN 模型可以获取潜在空间表示并从中提取点,这些点可以提供给生成模型并用于生成与训练数据高度相似的新数据。
判别器模型接收来自整个训练域的示例,该训练域由真实数据示例和生成的数据示例组成。 真实的例子包含在训练数据集中,而假数据是由生成模型生成的。 训练鉴别器模型的过程与基本的二元分类模型训练完全相同。
GAN 训练过程
首先,使用真实的真实图像作为训练数据集的一部分来训练 GAN。 这建立了鉴别器模型来区分生成的图像和真实图像。 它还生成生成器将用来生成新数据的数据分布。
生成器接收随机数值数据向量,并根据高斯分布对其进行转换,返回图像。 生成的图像与训练数据集中的一些真实图像一起被输入到鉴别器模型中。 鉴别器将对其接收的图像的性质进行概率预测,输出 0 到 1 之间的值,其中 1 通常是真实图像,0 是假图像。
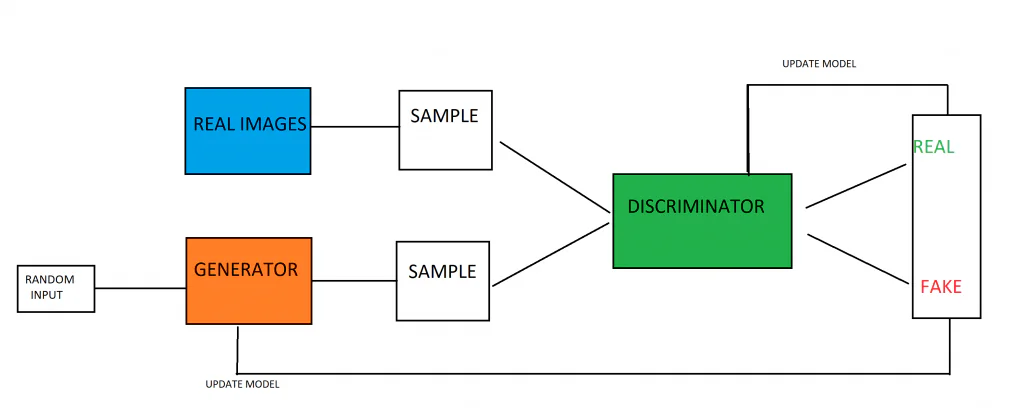
这里存在一个双反馈循环,因为地面鉴别器被馈送到图像的地面真实值,而鉴别器则向生成器提供有关其性能的反馈。
生成模型和判别模型正在相互玩零和游戏。 零和博弈是一方的收益以另一方的成本为代价的博弈(双方行动之和为零)。 当判别器模型能够成功区分真假示例时,判别器的参数无需更改。 然而,当模型无法区分真假图像时,会对模型参数进行大量更新。 对于生成模型来说,反之亦然,当它未能欺骗判别模型时,它会受到惩罚(并且其参数会更新),否则它的参数不会改变(或者会受到奖励)。
理想情况下,生成器能够将其性能提高到鉴别器无法区分假图像和真实图像的程度。 这意味着鉴别器对于真实图像和假图像的渲染概率始终为 50%,这意味着生成的图像应该与真实图像无法区分。 实际上,GAN 通常不会达到这一点。 然而,生成模型不需要创建完全相似的图像,仍然可以用于 GAN 所执行的许多任务。
生成式对抗网络的应用
GAN 有许多不同的应用,其中大多数都围绕图像和图像组件的生成。 GAN 通常用于所需图像数据缺失或某些容量受限的任务,作为生成所需数据的方法。 让我们来看看 GAN 的一些常见用例。
为数据集生成新示例
GAN 可用于为简单图像数据集生成新示例。 如果您只有少量训练示例并且需要更多训练示例,则可以使用 GAN 为图像分类器生成新的训练数据,从而在不同方向和角度生成新的训练示例。
生成独特的人脸

照片中的女人并不存在。 该图像由 StyleGAN 生成。 照片:Owlsmcgee,来自维基共享资源,公共领域 (https://commons.wikimedia.org/wiki/File:Woman_1.jpg)
经过充分训练后,GAN 可用于 生成极其逼真的人脸图像。 这些生成的图像可用于帮助训练人脸识别系统。
图像到图像的翻译
GAN 擅长图像翻译。 GAN 可用于对黑白图像进行着色、将草图或图画转换为摄影图像,或将图像从白天转换为夜间。
文本到图像翻译
文本到图像的翻译是 通过使用 GAN 可以实现。 当提供描述图像和随附图像的文本时,GAN 可以 接受训练以创造新形象 当提供所需图像的描述时。
编辑和修复图像
GAN 可用于编辑现有照片。 GAN 删除雨或雪等元素 来自图像,但它们也可用于 修复旧的、损坏的图像或损坏的图像。
超级分辨率
超分辨率是拍摄低分辨率图像并向图像中插入更多像素以提高图像分辨率的过程。 GAN 可以被训练来拍摄图像 生成该图像的更高分辨率版本。














