Штучний інтелект
Навчання моделей комп’ютерного зору на випадковому шумі замість реальних зображень

Дослідники з MIT Computer Science & Artificial Intelligence Laboratory (CSAIL) експериментували з використанням випадкових шумових зображень у наборах даних комп’ютерного зору для навчання моделей комп’ютерного зору, і виявили, що замість генерації сміття, цей метод є дивовижно ефективним:

Генеративні моделі з експерименту, відсортовані за продуктивністю. Джерело: https://openreview.net/pdf?id=RQUl8gZnN7O
Підгодовування очевидного “візуального сміття” у популярні архітектури комп’ютерного зору не повинно призводити до такого роду продуктивності. На дальньому правому боці зображення вище, чорні стовпці представляють точність (на Imagenet-100) для чотирьох “реальних” наборів даних. Хоча “випадкові шумові” набори даних, що передують їм (зображені різними кольорами, див. індекс зверху ліворуч), не можуть дорівняти їм, вони майже всі знаходяться в межах поважних верхніх і нижніх меж (червоні пунктирні лінії) для точності.
У цьому сенсі “точність” не означає, що результат обов’язково виглядає як обличчя, церква, піца або будь-яка інша конкретна область для якої ви можете бути зацікавлені у створенні системи синтезу зображень, такої як Генеративна суперницька мережа, або мережа кодування/декодування.
РATHER, воно означає, що моделі CSAIL вивели широко застосовні центральні “істини” з даних зображень так явно неструктурованих, що вони не повинні бути здатні постачати їх.
Різноманітність проти природності
Ні ці результати не можуть бути віднесені до переобучення: живий обговорення між авторами і рецензентами на Open Review показує, що змішування різних контентів з візуально різноманітних наборів даних (таких як “мертві листя”, “фрактали” і “процедурний шум” – див. зображення нижче) до тренувального набору даних справді покращує точність у цих експериментах.
Це свідчить (і це трохи революційна концепція) про новий тип “недообучення”, де “різноманітність” переважає “природність”.
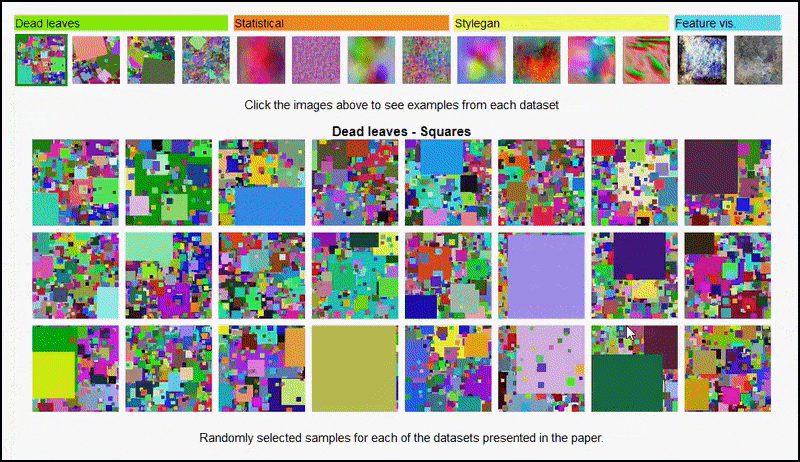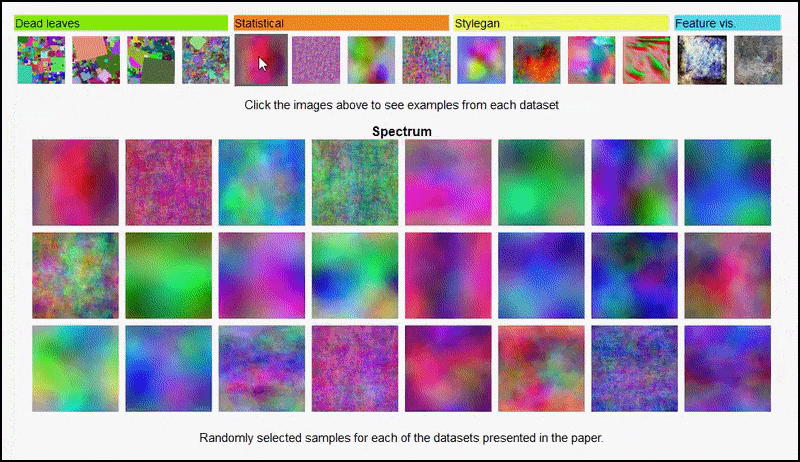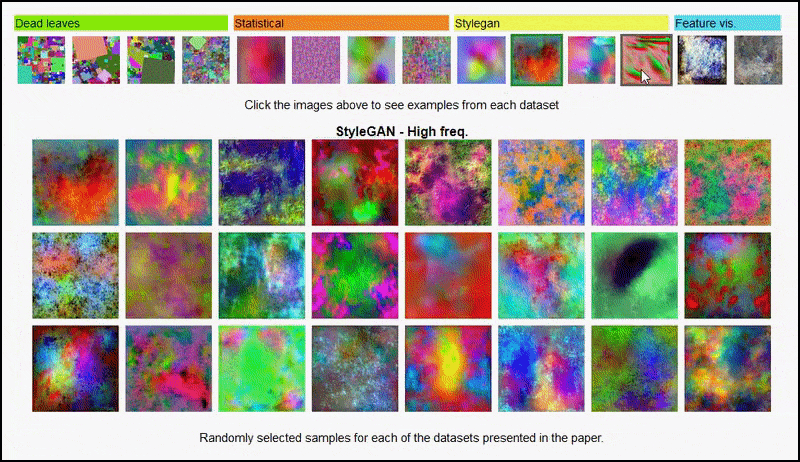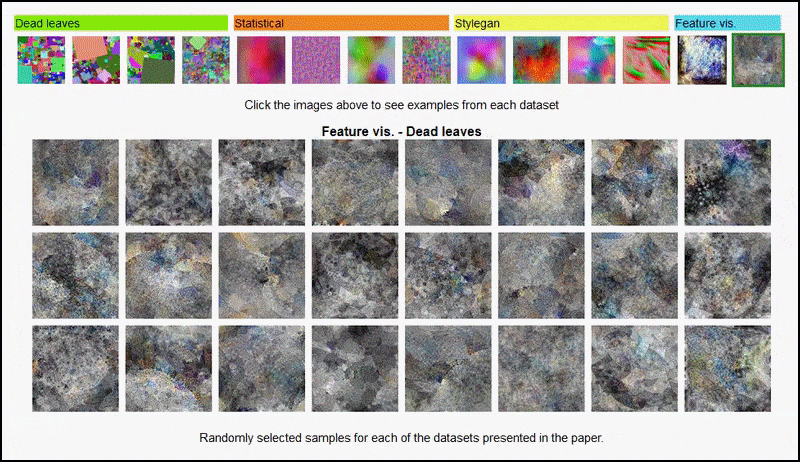
Сторінка проекту ініціативи дозволяє взаємодію з різними типами випадкових наборів даних зображень, використаних у експерименті. Джерело: https://mbaradad.github.io/learning_with_noise/
Результати, отримані дослідниками, ставлять під сумнів фундаментальну взаємозв’язок між мережами нейронів на основі зображень і “реальним світом” зображень, які кидаються їм у все більшій кількості щороку, і свідчать про те, що необхідність отримання, кураторства та іншого впорядкування гіпермасштабних наборів даних зображень може врешті-решт стати зайвою. Автори заявляють:
‘Поточні системи бачення тренуються на величезних наборах даних, і ці набори даних мають свої витрати: кураторство дорого, вони успадковують упередження людини, і існують проблеми щодо конфіденційності та прав на використання. Щоб протидіяти цим витратам, інтерес до навчання з дешевих джерел даних, таких як неозначені зображення, різко зріс.
‘У цій роботі ми йдемо далі і питаємо, чи можемо ми відмовитися від реальних наборів даних зображень зовсім, навчаючи на процедурних процесах шуму.’
Дослідники припускають, що поточна генерація архітектур машинного навчання може висновувати щось набагато фундаментальніше (або, принаймні, несподіваніше) з зображень, ніж вважалося раніше, і що “несенс” зображення можуть потенційно надати велику частку цієї інформації набагато дешевше, навіть з можливим використанням адгок-синтетичних даних, через архітектури генерації наборів даних, які генерують випадкові зображення під час тренування:
‘Ми ідентифікуємо два ключових властивості, які роблять добрі синтетичні дані для тренування систем бачення: 1)природність, 2) різноманітність. Цікаво, що найбільш природні дані не завжди найкращі, оскільки природність може бути на шкоду різноманітності.
‘Той факт, що природні дані допомагають, не повинен бути несподіваним, і це свідчить про те, що indeed, великомасштабні реальні дані мають значення. Однак, ми знаходимо, що те, що є важливим, не те, що дані є реальними, а те, що вони є природними, тобто вони повинні захоплювати певні структурні властивості реальних даних.
‘Багато з цих властивостей можуть бути захоплені в простих моделях шуму.’

Візуалізації функцій, що результатуються з AlexNet-похідного кодувача на деяких з різних “випадкових наборів даних зображень”, використаних авторами, що охоплюють 3-й і 5-й (фінальний) конволюційний шар. Методологія, використана тут, слідує методології, викладеній у дослідженні Google AI 2017 року.
Праця стаття, представлена на 35-ій Конференції з обробки нейронної інформації (NeurIPS 2021) у Сіднеї, називається Навчання бачити, дивлячись на шум, і походить від шести дослідників у CSAIL, з рівним внеском.
Праця була рекомендована консенсусом для вибіркового відбору на NeurIPS 2021, з рецензентами, які характеризують статтю як “науковий прорив”, який відкриває “велику область дослідження”, навіть якщо вона ставить так nhiều питань, як і відповідає.
У статті автори висновують:
‘Ми показали, що, коли проектуються за допомогою результатів попередніх досліджень про статистику природних зображень, ці набори даних можуть успішно тренувати візуальні представлення. Ми сподіваємося, що ця стаття мотивуватиме дослідження нових генеративних моделей, здатних генерувати структурований шум, який досягає ще вищої продуктивності при використанні в різноманітних візуальних завданнях.
‘Чи можливо досягти продуктивності, отриманої з попереднім тренуванням на ImageNet? Можливо, у відсутності великого тренувального набору, специфічного для певного завдання, найкраще попереднє тренування може не використовувати стандартний реальний набір даних, такий як ImageNet.’












