Штучний інтелект
Модельні маршрутизатори та петля зворотного зв’язку: Як штучний інтелект вчиться у самого себе
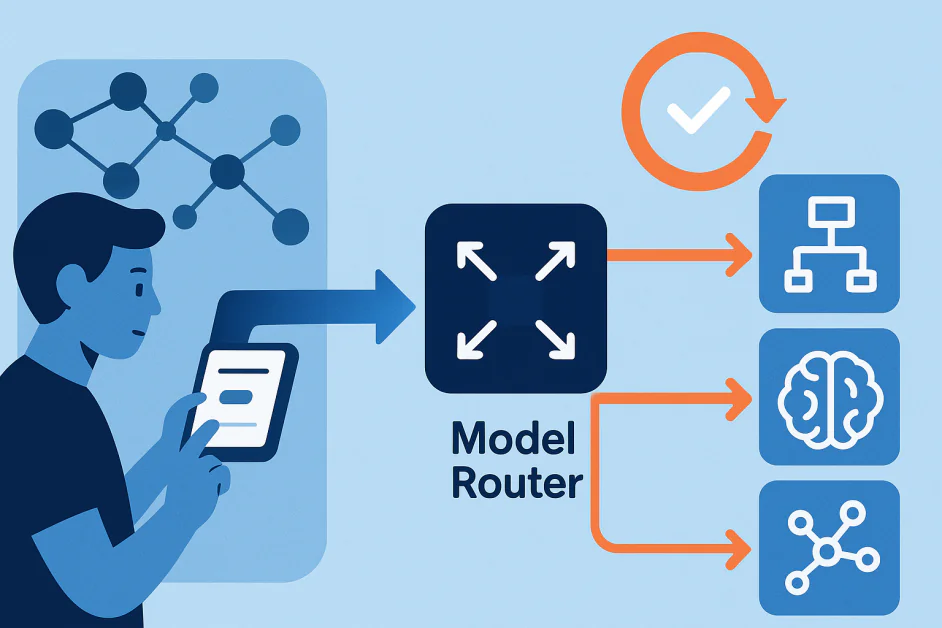
Сучасні системи штучного інтелекту вже не будуються навколо однієї моделі, яка обробляє кожне завдання. Натомість, вони покладаються на колекції моделей, кожна з яких призначена для конкретних цілей. У центрі цього набору знаходиться модельний маршрутизатор, компонент, який інтерпретує запит користувача та вирішує, яка модель повинна його обробити. Наприклад, у системах типу OpenAI’s GPT-5, маршрутизатор може направити простий запит до легкої моделі для швидкості, а складні завдання з висновку до більш просунутої моделі.
Маршрутизатори не лише керують трафіком. Вони вчаться з поведінки користувача, chẳng hạn, коли люди перемикаються між моделями або віддають перевагу певним відповідям. Це створює цикл: маршрутизатор призначає запит, модель видає відповідь, реакції користувача надають зворотний зв’язок, а маршрутизатор оновлює свої рішення. Коли ці цикли працюють тихо на задньому плані, вони можуть утворювати приховані петлі зворотного зв’язку. Такі петлі можуть посилювати упередженість, підтримувати помилкові моделі або поступово знижувати продуктивність способами, які важко виявити.
Ця стаття розглядає, як працюють модельні маршрутизатори, як виникають петлі зворотного зв’язку та які ризики вони становлять, коли системи штучного інтелекту продовжують розвиватися.
Поняття модельних маршрутизаторів у штучному інтелекті
Модельний маршрутизатор є рішенням про прийняття рішення у багатомодельній системі штучного інтелекту. Його роль полягає у визначенні, яка модель найкраще підходить для завдання. Вибір залежить від таких факторів, як складність запиту, намір користувача, контекст та компроміс між вартістю, точністю та швидкістю.
На відміну від систем, які слідують фіксованим правилам, більшість модельних маршрутизаторів є системами машинного навчання самих по собі. Вони тренуються на реальних сигналах та адаптуються з часом. Вони можуть вчиться з поведінки користувача, chẳng hạn, перемикання між моделями, оцінка відповідей чи перефразування запитів, а також з автоматичних оцінок, які вимірюють якість виводу.
Ця адаптивність робить маршрутизатори потужними, але також ризикованими. Вони підвищують ефективність та забезпечують кращий досвід користувача, але ті самі процеси зворотного зв’язку, які уточнюють їхні рішення, можуть також створювати підтримуючі петлі. З часом ці петлі можуть впливати не лише на стратегії маршрутизації, а й на поведінку всієї системи штучного інтелекту.
Як утворюються петлі зворотного зв’язку
Петля зворотного зв’язку виникає, коли вивід системи впливає на дані, які вона пізніше вивчає. Простий приклад – система рекомендацій: якщо ви натискаєте на спортивне відео, система показує вам більше спортивного контенту, який формує те, що ви дивитесь далі. З часом система підтримує свої власні моделі. Інший приклад, щоб зрозуміти петлю зворотного зв’язку, – це передбачувальна поліція. Алгоритм може передбачити вищу злочинність у певних районах, що може привести до більшої кількості патрулів. Збільшені патрулі виявляють більше інцидентів, які потім підтверджують передбачення алгоритму. Система виглядає точною, але дані є викривленими її власним впливом. Петлі зворотного зв’язку можуть бути прямими або прихованими. Прямі петлі легко визначаються, chẳng hạn, система рекомендацій, яка повторно тренується на своїх власних пропозиціях. Приховані петлі є більш тонкими, оскільки вони виникають, коли різні частини системи непрямо впливають одна на одну.
Модельні маршрутизатори можуть створювати подібні петлі. Рішення маршрутизатора формує, яка модель видає відповідь. Ця відповідь формує поведінку користувача, яка стає зворотним зв’язком для маршрутизатора. З часом маршрутизатор може почати підтримувати моделі, які працювали в минулому, а не постійно вибирати найкращу модель. Ці петлі важко виявити та можуть тихо штовхати системи штучного інтелекту в ненавмисні напрямки.
Чому петлі зворотного зв’язку в маршрутизаторах ризиковані
Хоча петлі зворотного зв’язку допомагають маршрутизаторам покращувати при призначенні завдань, вони також несуть ризики, які можуть викривлювати поведінку системи. Одним з ризиків є підтримка початкових упереджень. Якщо маршрутизатор повторно направляє певний тип запиту до Моделі А, більшість зворотного зв’язку буде походити від виводу Моделі А. Маршрутизатор може тоді припустити, що Модель А завжди найкраща, відсторонивши Модель Б, навіть якщо вона іноді може виконувати завдання краще. Це нерівномірне використання може стати самопідтримуючим. Моделі, які добре виконують завдання, приваблюють більше запитів, які підтримують їхні сильні сторони. Менш використовувані моделі отримують менше можливостей для покращення, створюючи дисбаланс та знижуючи різноманітність.
Упередженість також можуть походити від моделей оцінки, які використовуються для визначення правильності. Якщо “суддя”-модель має сліпі місця, її упередженість передається напряму до маршрутизатора, який потім оптимізується для цінностей “судді” замість справжніх потреб користувача. Поведінка користувача додає ще один рівень складності. Якщо маршрутизатор схильний повертати певні стилі відповідей, користувачі можуть адаптувати свої запити, щоб відповідати цим моделям, ще більше підтримуючи їх. З часом це може звузити як поведінку користувача, так і відповіді системи. Маршрутизатори також можуть вчиться асоціювати певні моделі запитів або демографічні групи з конкретними моделями. Це може привести до систематично різних досвідів між групами, потенційно підтримуючи та посилюючи існуючі соціальні упередженості.
Іншим ключовим vấn є довгостроковий дрейф. Рішення, які приймає маршрутизатор сьогодні, впливають на тренувальні дані, які використовуються завтра. Якщо моделі повторно тренуються на виводі, який впливає на маршрутизацію, вони можуть вивчити переваги маршрутизатора замість незалежних підходів. Це може зробити відповіді між моделями більш уніфікованими та вбудовувати упередженість, яка зберігається з часом.
Стратегії для розриву циклу
Зниження ризиків прихованих петель вимагає активного проектування та нагляду. Навчання повинно використовувати різноманітні джерела даних, а не лише кліки користувача чи перемикання. Окказіональне випадкове маршрутизація також може запобігти монополізуванню одного типу завдання однією моделлю. Мониторинг є суттєвим. Регулярні аудити можуть виявити, чи маршрутизатор дрейфує до певних моделей чи надмірно покладається на одну модель. Прозорість у рішеннях маршрутизатора допомагає дослідникам виявити упередженість на ранній стадії.
Маршрутизатори також повинні повторно тренуватися періодично з свіжими, балансированими даними, щоб старі упередженості не стали закріпленими. Включення нагляду людини, особливо в чутливих галузях, додає ще один рівень відповідальності. Люди можуть визначити, коли маршрутизатор систематично віддає перевагу одній моделі або неправильно класифікує певні запити.
Ключовим є те, щоб розглядати маршрутизатор як модель, яка підлягає зворотному зв’язку, а не як фіксовану чи нейтральну складову. Розпізнавши, як маршрутизатори самі формуються даними, які вони створюють, дослідники та розробники можуть проектувати системи, які залишаються справедливими, адаптивними та надійними з часом.
Основний висновок
Модельні маршрутизатори пропонують явні переваги в ефективності та адаптивності, але вони також несуть приховані ризики. Петлі зворотного зв’язку всередині цих систем можуть тихо посилювати упередженість, обмежувати різноманітність відповідей та блокувати моделі в вузькі моделі поведінки. Коли ці архітектури стають більш поширеними, визнання та подолання цих ризиків на ранній стадії буде суттєвим для побудови систем штучного інтелекту, які залишаються справедливими, надійними та真正ньо адаптивними.












