Лідери думок
3 способи збереження застарілих фактів у свіжому вигляді в великих мовних моделях
Великі мовні моделі (LLM) типу GPT3, ChatGPT і BARD зараз у центрі уваги. Усі мають свою думку про те, як ці інструменти хороші чи погані для суспільства та що вони означають для майбутнього штучного інтелекту. Google отримала багато критики за свою нову модель BARD, яка неправильно відповіла на складне питання (трохи). Коли її запитали: “Які нові відкриття з телескопа Джеймса Вебба можна розповісти моєму 9-річному синові?” – чат-бот дав три відповіді, з яких 2 були правильними, а 1 – неправильною. Неправильна відповідь була така, що перше зображення “ексопланети” було зроблено JWST, що було неправильно. Отже, модель мала неправильний факт, збережений у своїй базі знань. Для того, щоб великі мовні моделі були ефективними, нам потрібно знайти спосіб оновити ці факти або доповнити факти новими знаннями.
Давайте спочатку розглянемо, як факти зберігаються всередині великої мовної моделі (LLM). Великі мовні моделі не зберігають інформацію та факти традиційним способом, як бази даних або файли. Замість цього вони були навчені на величезних обсягах текстових даних і вивчили закономірності та відносини в цих даних. Це дозволяє їм генерувати відповіді, подібні до тих, які дає людина, але вони не мають конкретного місця для зберігання своєї навченої інформації. Коли модель відповідає на питання, вона використовує свій навчальний процес для генерації відповіді на основі отриманого вводу. Інформація та знання, які має мовна модель, є результатом закономірностей, які вона вивчила в даних, на яких була навчена, а не результатом явного зберігання в пам’яті моделі. Архітектура Transformers, на якій засновані більшість сучасних LLM, має внутрішнє кодування фактів, яке використовується для відповіді на питання, поставлене в промпті.

Якщо факти всередині внутрішньої пам’яті LLM неправильні або застаріли, нову інформацію потрібно надавати через промпт. Промпт – це текст, надісланий до LLM з запитом і підтримуючими доказами, які можуть бути новими або виправленими фактами. Ось три способи підходу до цього.
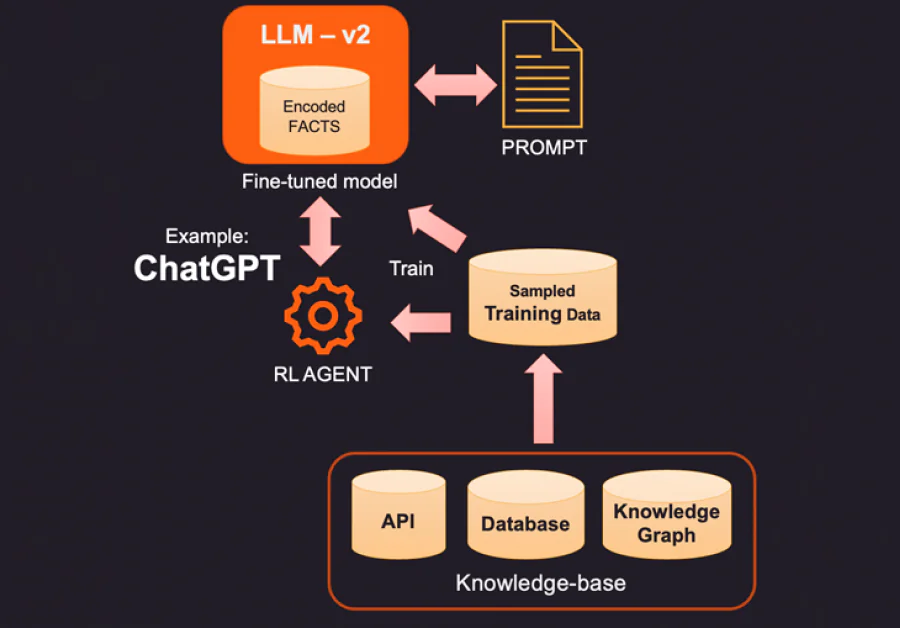
1. Один зі способів виправлення закодованих фактів LLM – це надання нових фактів, які стосуються контексту, за допомогою зовнішньої бази знань. Ця база знань може бути API-запитами для отримання відповідної інформації або пошуком у базі даних SQL, No-SQL або векторній базі даних. Більш просунуте знання можна витягнути з бази знань, яка зберігає дані сутностей та відносини між ними. В залежності від інформації, яку запитує користувач, відповідну контекстну інформацію можна отримати та надати як додаткові факти LLM. Ці факти також можуть бути відформатовані, щоб вони виглядали як навчальні приклади для поліпшення процесу навчання. Наприклад, ви можете передати набір пар питань та відповідей, щоб модель навчилася давати відповіді.

2. Більш інноваційний (і більш дорогий) спосіб доповнення LLM – це фактичне тонке налаштування за допомогою навчальних даних. Замість того, щоб запитувати базу знань для отримання конкретних фактів для додавання, ми будемо створювати навчальний набір даних шляхом вибірки бази знань. Використовуючи методи нагляду за навчанням, такі як тонке налаштування, ми могли б створити нову версію LLM, яка навчена на цих додаткових знаннях. Цей процес зазвичай дорогий і може коштувати кілька тисяч доларів для створення та підтримки тонко налаштованої моделі в OpenAI. Природно, що вартість повинна знизитися з часом.
3. Інший варіант – використання методів, таких як навчання з підкріпленням (RL), для навчання агента з людською допомогою та вивчення політики щодо відповідей на питання. Цей метод був дуже ефективним у створенні моделей з меншим слідом, які добре виконують конкретні завдання. Наприклад, знаменитий ChatGPT, випущений OpenAI, був навчений на комбінації нагляду за навчанням та RL з людською допомогою.

У підсумку, це дуже швидко розвивається галузь, у яку хочуть вступити всі великі компанії, щоб показати свою відмінність. Ми скоро побачимо великі інструменти LLM у більшості галузей, таких як роздрібна торгівля, охорона здоров’я та банківська справа, які можуть відповідати на питання людською мовою, розуміючи нюанси мови. Ці інструменти LLM, інтегровані з корпоративними даними, можуть оптимізувати доступ та надавати правильні дані правильним людям у правильний час.












